 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitEasy: A Practical Approach for Training ML models on Mobile Devices in a split second
Nov 09, 2020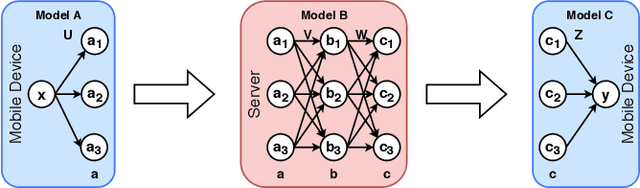
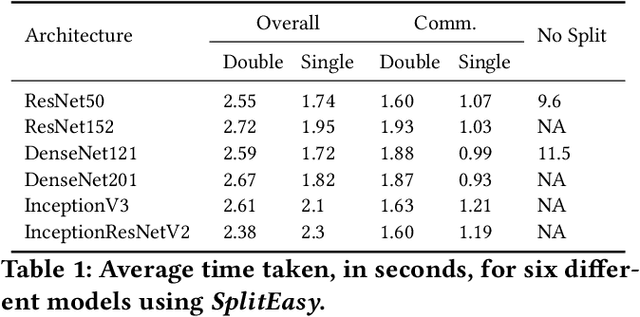
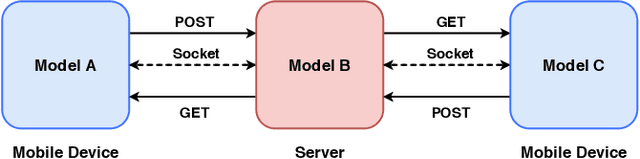
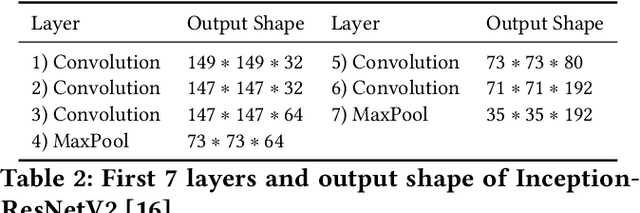
Modern mobile devices, although resourceful, cannot train state-of-the-art machine learning models without the assistance of servers, which require access to privacy-sensitive user data. Split learning has recently emerged as a promising technique for training complex deep learning (DL) models on low-powered mobile devices. The core idea behind this technique is to train the sensitive layers of a DL model on the mobile devices while offloading the computationally intensive layers to a server. Although a lot of works have already explored the effectiveness of split learning in simulated settings, a usable toolkit for this purpose does not exist. In this work, we propose SplitEasy, a framework for training ML models on mobile devices using split learning. Using the abstraction provided by SplitEasy, developers can run various DL models under split learning setting by making minimal modifications. We provide a detailed explanation of SplitEasy and perform experiments under varying networks to demonstrate its versatility. We demonstrate how SplitEasy can be used to train state-of-the-art models while incurring nearly constant computational cost on mobile devices.
FaRM: Fair Reward Mechanism for Information Aggregation in Spontaneous Localized Settings (Extended Version)
Jun 10, 2019
Although peer prediction markets are widely used in crowdsourcing to aggregate information from agents, they often fail to reward the participating agents equitably. Honest agents can be wrongly penalized if randomly paired with dishonest ones. In this work, we introduce \emph{selective} and \emph{cumulative} fairness. We characterize a mechanism as fair if it satisfies both notions and present FaRM, a representative mechanism we designed. FaRM is a Nash incentive mechanism that focuses on information aggregation for spontaneous local activities which are accessible to a limited number of agents without assuming any prior knowledge of the event. All the agents in the vicinity observe the same information. FaRM uses \textit{(i)} a \emph{report strength score} to remove the risk of random pairing with dishonest reporters, \textit{(ii)} a \emph{consistency score} to measure an agent's history of accurate reports and distinguish valuable reports, \textit{(iii)} a \emph{reliability score} to estimate the probability of an agent to collude with nearby agents and prevents agents from getting swayed, and \textit{(iv)} a \emph{location robustness score} to filter agents who try to participate without being present in the considered setting. Together, report strength, consistency, and reliability represent a fair reward given to agents based on their reports.