 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing the efficiency of human feedback in AI alignment: a comparative analysis
Nov 16, 2025Reinforcement Learning from Human Feedback (RLHF) relies on preference modeling to align machine learning systems with human values, yet the popular approach of random pair sampling with Bradley-Terry modeling is statistically limited and inefficient under constrained annotation budgets. In this work, we explore alternative sampling and evaluation strategies for preference inference in RLHF, drawing inspiration from areas such as game theory, statistics, and social choice theory. Our best-performing method, Swiss InfoGain, employs a Swiss tournament system with a proxy mutual-information-gain pairing rule, which significantly outperforms all other methods in constrained annotation budgets while also being more sample-efficient. Even in high-resource settings, we can identify superior alternatives to the Bradley-Terry baseline. Our experiments demonstrate that adaptive, resource-aware strategies reduce redundancy, enhance robustness, and yield statistically significant improvements in preference learning, highlighting the importance of balancing alignment quality with human workload in RLHF pipelines.
MP-SL: Multihop Parallel Split Learning
Jan 31, 2024Federated Learning (FL) stands out as a widely adopted protocol facilitating the training of Machine Learning (ML) models while maintaining decentralized data. However, challenges arise when dealing with a heterogeneous set of participating devices, causing delays in the training process, particularly among devices with limited resources. Moreover, the task of training ML models with a vast number of parameters demands computing and memory resources beyond the capabilities of small devices, such as mobile and Internet of Things (IoT) devices. To address these issues, techniques like Parallel Split Learning (SL) have been introduced, allowing multiple resource-constrained devices to actively participate in collaborative training processes with assistance from resourceful compute nodes. Nonetheless, a drawback of Parallel SL is the substantial memory allocation required at the compute nodes, for instance training VGG-19 with 100 participants needs 80 GB. In this paper, we introduce Multihop Parallel SL (MP-SL), a modular and extensible ML as a Service (MLaaS) framework designed to facilitate the involvement of resource-constrained devices in collaborative and distributed ML model training. Notably, to alleviate memory demands per compute node, MP-SL supports multihop Parallel SL-based training. This involves splitting the model into multiple parts and utilizing multiple compute nodes in a pipelined manner. Extensive experimentation validates MP-SL's capability to handle system heterogeneity, demonstrating that the multihop configuration proves more efficient than horizontally scaled one-hop Parallel SL setups, especially in scenarios involving more cost-effective compute nodes.
Lightweight Modeling of User Context Combining Physical and Virtual Sensor Data
Jun 28, 2023The multitude of data generated by sensors available on users' mobile devices, combined with advances in machine learning techniques, support context-aware services in recognizing the current situation of a user (i.e., physical context) and optimizing the system's personalization features. However, context-awareness performances mainly depend on the accuracy of the context inference process, which is strictly tied to the availability of large-scale and labeled datasets. In this work, we present a framework developed to collect datasets containing heterogeneous sensing data derived from personal mobile devices. The framework has been used by 3 voluntary users for two weeks, generating a dataset with more than 36K samples and 1331 features. We also propose a lightweight approach to model the user context able to efficiently perform the entire reasoning process on the user mobile device. To this aim, we used six dimensionality reduction techniques in order to optimize the context classification. Experimental results on the generated dataset show that we achieve a 10x speed up and a feature reduction of more than 90% while keeping the accuracy loss less than 3%.
IPLS : A Framework for Decentralized Federated Learning
Jan 06, 2021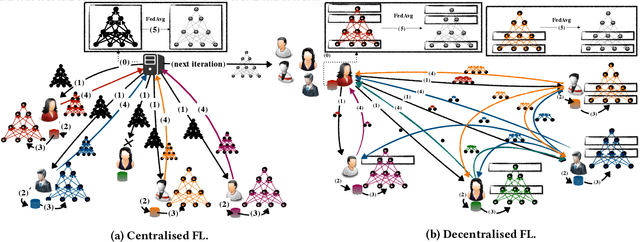
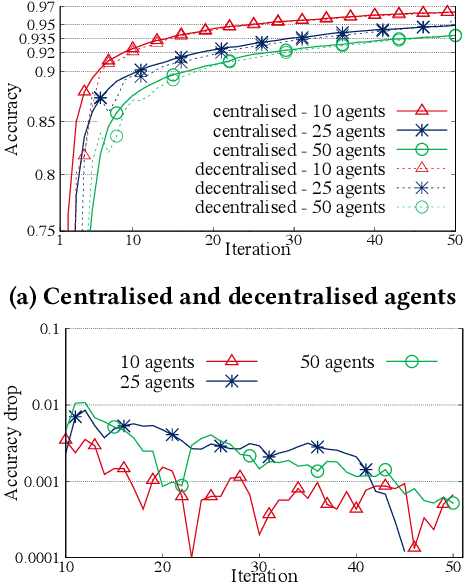
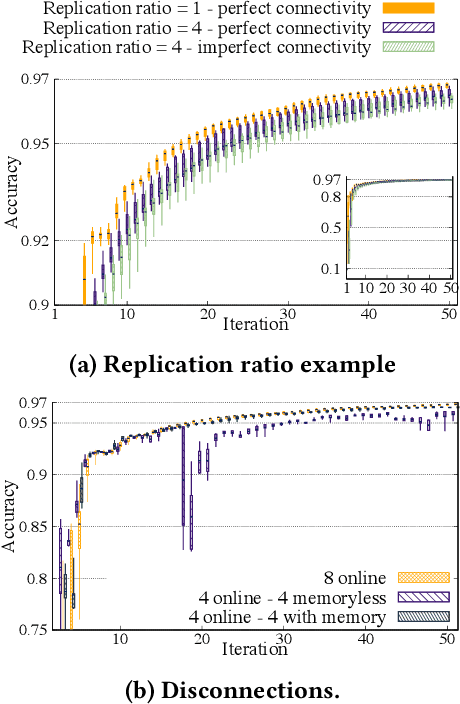
The proliferation of resourceful mobile devices that store rich, multidimensional and privacy-sensitive user data motivate the design of federated learning (FL), a machine-learning (ML) paradigm that enables mobile devices to produce an ML model without sharing their data. However, the majority of the existing FL frameworks rely on centralized entities. In this work, we introduce IPLS, a fully decentralized federated learning framework that is partially based on the interplanetary file system (IPFS). By using IPLS and connecting into the corresponding private IPFS network, any party can initiate the training process of an ML model or join an ongoing training process that has already been started by another party. IPLS scales with the number of participants, is robust against intermittent connectivity and dynamic participant departures/arrivals, requires minimal resources, and guarantees that the accuracy of the trained model quickly converges to that of a centralized FL framework with an accuracy drop of less than one per thousand.
SplitEasy: A Practical Approach for Training ML models on Mobile Devices in a split second
Nov 09, 2020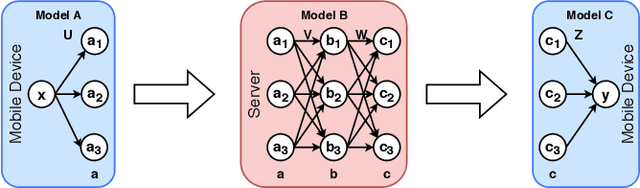
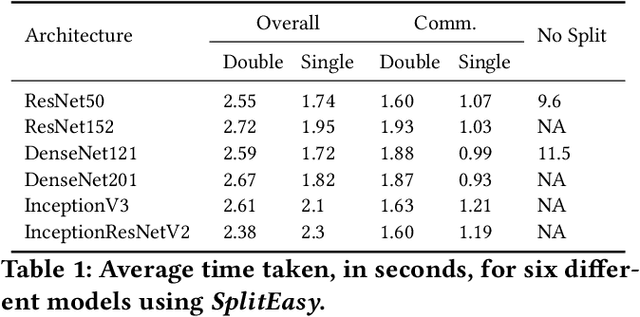
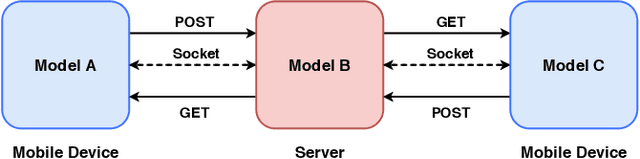
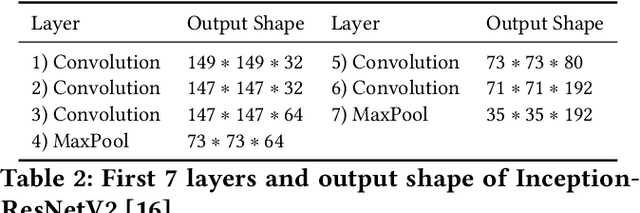
Modern mobile devices, although resourceful, cannot train state-of-the-art machine learning models without the assistance of servers, which require access to privacy-sensitive user data. Split learning has recently emerged as a promising technique for training complex deep learning (DL) models on low-powered mobile devices. The core idea behind this technique is to train the sensitive layers of a DL model on the mobile devices while offloading the computationally intensive layers to a server. Although a lot of works have already explored the effectiveness of split learning in simulated settings, a usable toolkit for this purpose does not exist. In this work, we propose SplitEasy, a framework for training ML models on mobile devices using split learning. Using the abstraction provided by SplitEasy, developers can run various DL models under split learning setting by making minimal modifications. We provide a detailed explanation of SplitEasy and perform experiments under varying networks to demonstrate its versatility. We demonstrate how SplitEasy can be used to train state-of-the-art models while incurring nearly constant computational cost on mobile devices.
FaRM: Fair Reward Mechanism for Information Aggregation in Spontaneous Localized Settings (Extended Version)
Jun 10, 2019
Although peer prediction markets are widely used in crowdsourcing to aggregate information from agents, they often fail to reward the participating agents equitably. Honest agents can be wrongly penalized if randomly paired with dishonest ones. In this work, we introduce \emph{selective} and \emph{cumulative} fairness. We characterize a mechanism as fair if it satisfies both notions and present FaRM, a representative mechanism we designed. FaRM is a Nash incentive mechanism that focuses on information aggregation for spontaneous local activities which are accessible to a limited number of agents without assuming any prior knowledge of the event. All the agents in the vicinity observe the same information. FaRM uses \textit{(i)} a \emph{report strength score} to remove the risk of random pairing with dishonest reporters, \textit{(ii)} a \emph{consistency score} to measure an agent's history of accurate reports and distinguish valuable reports, \textit{(iii)} a \emph{reliability score} to estimate the probability of an agent to collude with nearby agents and prevents agents from getting swayed, and \textit{(iv)} a \emph{location robustness score} to filter agents who try to participate without being present in the considered setting. Together, report strength, consistency, and reliability represent a fair reward given to agents based on their reports.