 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Limitations in the Synthetic Generation of mHealth Sensor Data
May 20, 2025The widespread adoption of mobile sensors has the potential to provide massive and heterogeneous time series data, driving Artificial Intelligence applications in mHealth. However, data collection remains limited due to stringent ethical regulations, privacy concerns, and other constraints, hindering progress in the field. Synthetic data generation, particularly through Generative Adversarial Networks and Diffusion Models, has emerged as a promising solution to address both data scarcity and privacy issues. Yet, these models are often limited to short-term, unimodal signal patterns. This paper presents a systematic evaluation of state-of-the-art generative models for time series synthesis, with a focus on their ability to jointly handle multi-modality, long-range dependencies, and conditional generation-key challenges in the mHealth domain. To ensure a fair comparison, we introduce a novel evaluation framework designed to measure both the intrinsic quality of synthetic data and its utility in downstream predictive tasks. Our findings reveal critical limitations in the existing approaches, particularly in maintaining cross-modal consistency, preserving temporal coherence, and ensuring robust performance in train-on-synthetic, test-on-real, and data augmentation scenarios. Finally, we present our future research directions to enhance synthetic time series generation and improve the applicability of generative models in mHealth.
FedSub: Introducing class-aware Subnetworks Fusion to Enhance Personalized Federated Learning in Ubiquitous Systems
Nov 13, 2024



Personalized Federated Learning is essential in AI-driven ubiquitous systems, supporting the distributed development of models able to adapt to diverse and evolving user behaviors while safeguarding privacy. Despite addressing heterogeneous user data distributions in collaborative model training, existing methods often face limitations balancing personalization and generalization, oversimplifying user similarities, or relying heavily on global models. In this paper, we propose FedSub, a novel federated approach designed to enhance personalization through the use of class-aware prototypes and model subnetworks. Prototypes serve as compact representations of user data, clustered on the server to identify similarities based on specific label patterns. Concurrently, subnetworks -- model components necessary to process each class -- are extracted locally and fused by the server according to these clusters, producing highly tailored model updates for each user. This fine-grained, class-specific aggregation of clients' models allows FedSub to capture the unique characteristics of individual user data patterns. The effectiveness of FedSub is validated in three real-world scenarios characterized by high data heterogeneity, derived from human activity recognition and mobile health applications. Experimental evaluations demonstrate FedSub's performance improvements with respect to the state-of-the-art and significant advancements in personalization for ubiquitous systems based on personal mobile and wearable devices.
ContextLabeler Dataset: physical and virtual sensors data collected from smartphone usage in-the-wild
Jul 07, 2023This paper describes a data collection campaign and the resulting dataset derived from smartphone sensors characterizing the daily life activities of 3 volunteers in a period of two weeks. The dataset is released as a collection of CSV files containing more than 45K data samples, where each sample is composed by 1332 features related to a heterogeneous set of physical and virtual sensors, including motion sensors, running applications, devices in proximity, and weather conditions. Moreover, each data sample is associated with a ground truth label that describes the user activity and the situation in which she was involved during the sensing experiment (e.g., working, at restaurant, and doing sport activity). To avoid introducing any bias during the data collection, we performed the sensing experiment in-the-wild, that is, by using the volunteers' devices, and without defining any constraint related to the user's behavior. For this reason, the collected dataset represents a useful source of real data to both define and evaluate a broad set of novel context-aware solutions (both algorithms and protocols) that aim to adapt their behavior according to the changes in the user's situation in a mobile environment.
A Machine-Learned Ranking Algorithm for Dynamic and Personalised Car Pooling Services
Jul 06, 2023Car pooling is expected to significantly help in reducing traffic congestion and pollution in cities by enabling drivers to share their cars with travellers with similar itineraries and time schedules. A number of car pooling matching services have been designed in order to efficiently find successful ride matches in a given pool of drivers and potential passengers. However, it is now recognised that many non-monetary aspects and social considerations, besides simple mobility needs, may influence the individual willingness of sharing a ride, which are difficult to predict. To address this problem, in this study we propose GoTogether, a recommender system for car pooling services that leverages on learning-to-rank techniques to automatically derive the personalised ranking model of each user from the history of her choices (i.e., the type of accepted or rejected shared rides). Then, GoTogether builds the list of recommended rides in order to maximise the success rate of the offered matches. To test the performance of our scheme we use real data from Twitter and Foursquare sources in order to generate a dataset of plausible mobility patterns and ride requests in a metropolitan area. The results show that the proposed solution quickly obtain an accurate prediction of the personalised user's choice model both in static and dynamic conditions.
Transfer Learning for the Efficient Detection of COVID-19 from Smartphone Audio Data
Jul 06, 2023



Disease detection from smartphone data represents an open research challenge in mobile health (m-health) systems. COVID-19 and its respiratory symptoms are an important case study in this area and their early detection is a potential real instrument to counteract the pandemic situation. The efficacy of this solution mainly depends on the performances of AI algorithms applied to the collected data and their possible implementation directly on the users' mobile devices. Considering these issues, and the limited amount of available data, in this paper we present the experimental evaluation of 3 different deep learning models, compared also with hand-crafted features, and of two main approaches of transfer learning in the considered scenario: both feature extraction and fine-tuning. Specifically, we considered VGGish, YAMNET, and L\textsuperscript{3}-Net (including 12 different configurations) evaluated through user-independent experiments on 4 different datasets (13,447 samples in total). Results clearly show the advantages of L\textsuperscript{3}-Net in all the experimental settings as it overcomes the other solutions by 12.3\% in terms of Precision-Recall AUC as features extractor, and by 10\% when the model is fine-tuned. Moreover, we note that to fine-tune only the fully-connected layers of the pre-trained models generally leads to worse performances, with an average drop of 6.6\% with respect to feature extraction. %highlighting the need for further investigations. Finally, we evaluate the memory footprints of the different models for their possible applications on commercial mobile devices.
PLIERS: a Popularity-Based Recommender System for Content Dissemination in Online Social Networks
Jul 06, 2023
In this paper, we propose a novel tag-based recommender system called PLIERS, which relies on the assumption that users are mainly interested in items and tags with similar popularity to those they already own. PLIERS is aimed at reaching a good tradeoff between algorithmic complexity and the level of personalization of recommended items. To evaluate PLIERS, we performed a set of experiments on real OSN datasets, demonstrating that it outperforms state-of-the-art solutions in terms of personalization, relevance, and novelty of recommendations.
Context-Aware Configuration and Management of WiFi Direct Groups for Real Opportunistic Networks
Jul 06, 2023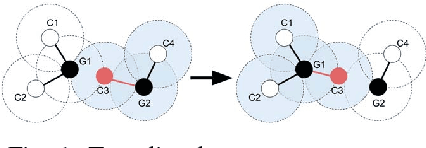


Wi-Fi Direct is a promising technology for the support of device-to-device communications (D2D) on commercial mobile devices. However, the standard as-it-is is not sufficient to support the real deployment of networking solutions entirely based on D2D such as opportunistic networks. In fact, WiFi Direct presents some characteristics that could limit the autonomous creation of D2D connections among users' personal devices. Specifically, the standard explicitly requires the user's authorization to establish a connection between two or more devices, and it provides a limited support for inter-group communication. In some cases, this might lead to the creation of isolated groups of nodes which cannot communicate among each other. In this paper, we propose a novel middleware-layer protocol for the efficient configuration and management of WiFi Direct groups (WiFi Direct Group Manager, WFD-GM) to enable autonomous connections and inter-group communication. This enables opportunistic networks in real conditions (e.g., variable mobility and network size). WFD-GM defines a context function that takes into account heterogeneous parameters for the creation of the best group configuration in a specific time window, including an index of nodes' stability and power levels. We evaluate the protocol performances by simulating three reference scenarios including different mobility models, geographical areas and number of nodes. Simulations are also supported by experimental results related to the evaluation in a real testbed of the involved context parameters. We compare WFD-GM with the state-of-the-art solutions and we show that it performs significantly better than a Baseline approach in scenarios with medium/low mobility, and it is comparable with it in case of high mobility, without introducing additional overhead.
Recommender Systems for Online and Mobile Social Networks: A survey
Jun 28, 2023Recommender Systems (RS) currently represent a fundamental tool in online services, especially with the advent of Online Social Networks (OSN). In this case, users generate huge amounts of contents and they can be quickly overloaded by useless information. At the same time, social media represent an important source of information to characterize contents and users' interests. RS can exploit this information to further personalize suggestions and improve the recommendation process. In this paper we present a survey of Recommender Systems designed and implemented for Online and Mobile Social Networks, highlighting how the use of social context information improves the recommendation task, and how standard algorithms must be enhanced and optimized to run in a fully distributed environment, as opportunistic networks. We describe advantages and drawbacks of these systems in terms of algorithms, target domains, evaluation metrics and performance evaluations. Eventually, we present some open research challenges in this area.
MyDigitalFootprint: an extensive context dataset for pervasive computing applications at the edge
Jun 28, 2023The widespread diffusion of connected smart devices has contributed to the rapid expansion and evolution of the Internet at its edge. Personal mobile devices interact with other smart objects in their surroundings, adapting behavior based on rapidly changing user context. The ability of mobile devices to process this data locally is crucial for quick adaptation. This can be achieved through a single elaboration process integrated into user applications or a middleware platform for context processing. However, the lack of public datasets considering user context complexity in the mobile environment hinders research progress. We introduce MyDigitalFootprint, a large-scale dataset comprising smartphone sensor data, physical proximity information, and Online Social Networks interactions. This dataset supports multimodal context recognition and social relationship modeling. It spans two months of measurements from 31 volunteer users in their natural environment, allowing for unrestricted behavior. Existing public datasets focus on limited context data for specific applications, while ours offers comprehensive information on the user context in the mobile environment. To demonstrate the dataset's effectiveness, we present three context-aware applications utilizing various machine learning tasks: (i) a social link prediction algorithm based on physical proximity data, (ii) daily-life activity recognition using smartphone-embedded sensors data, and (iii) a pervasive context-aware recommender system. Our dataset, with its heterogeneity of information, serves as a valuable resource to validate new research in mobile and edge computing.
Lightweight Modeling of User Context Combining Physical and Virtual Sensor Data
Jun 28, 2023The multitude of data generated by sensors available on users' mobile devices, combined with advances in machine learning techniques, support context-aware services in recognizing the current situation of a user (i.e., physical context) and optimizing the system's personalization features. However, context-awareness performances mainly depend on the accuracy of the context inference process, which is strictly tied to the availability of large-scale and labeled datasets. In this work, we present a framework developed to collect datasets containing heterogeneous sensing data derived from personal mobile devices. The framework has been used by 3 voluntary users for two weeks, generating a dataset with more than 36K samples and 1331 features. We also propose a lightweight approach to model the user context able to efficiently perform the entire reasoning process on the user mobile device. To this aim, we used six dimensionality reduction techniques in order to optimize the context classification. Experimental results on the generated dataset show that we achieve a 10x speed up and a feature reduction of more than 90% while keeping the accuracy loss less than 3%.