 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Heterogeneity and Forgotten Labels in Split Federated Learning
Nov 12, 2025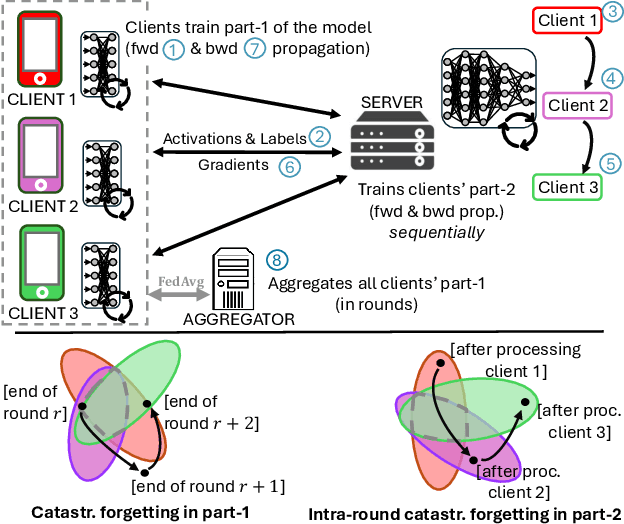
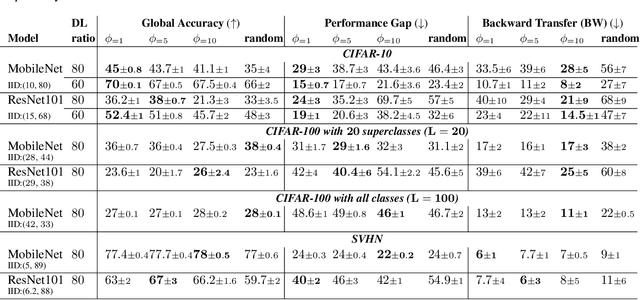


In Split Federated Learning (SFL), the clients collaboratively train a model with the help of a server by splitting the model into two parts. Part-1 is trained locally at each client and aggregated by the aggregator at the end of each round. Part-2 is trained at a server that sequentially processes the intermediate activations received from each client. We study the phenomenon of catastrophic forgetting (CF) in SFL in the presence of data heterogeneity. In detail, due to the nature of SFL, local updates of part-1 may drift away from global optima, while part-2 is sensitive to the processing sequence, similar to forgetting in continual learning (CL). Specifically, we observe that the trained model performs better in classes (labels) seen at the end of the sequence. We investigate this phenomenon with emphasis on key aspects of SFL, such as the processing order at the server and the cut layer. Based on our findings, we propose Hydra, a novel mitigation method inspired by multi-head neural networks and adapted for the SFL's setting. Extensive numerical evaluations show that Hydra outperforms baselines and methods from the literature.
MP-SL: Multihop Parallel Split Learning
Jan 31, 2024Federated Learning (FL) stands out as a widely adopted protocol facilitating the training of Machine Learning (ML) models while maintaining decentralized data. However, challenges arise when dealing with a heterogeneous set of participating devices, causing delays in the training process, particularly among devices with limited resources. Moreover, the task of training ML models with a vast number of parameters demands computing and memory resources beyond the capabilities of small devices, such as mobile and Internet of Things (IoT) devices. To address these issues, techniques like Parallel Split Learning (SL) have been introduced, allowing multiple resource-constrained devices to actively participate in collaborative training processes with assistance from resourceful compute nodes. Nonetheless, a drawback of Parallel SL is the substantial memory allocation required at the compute nodes, for instance training VGG-19 with 100 participants needs 80 GB. In this paper, we introduce Multihop Parallel SL (MP-SL), a modular and extensible ML as a Service (MLaaS) framework designed to facilitate the involvement of resource-constrained devices in collaborative and distributed ML model training. Notably, to alleviate memory demands per compute node, MP-SL supports multihop Parallel SL-based training. This involves splitting the model into multiple parts and utilizing multiple compute nodes in a pipelined manner. Extensive experimentation validates MP-SL's capability to handle system heterogeneity, demonstrating that the multihop configuration proves more efficient than horizontally scaled one-hop Parallel SL setups, especially in scenarios involving more cost-effective compute nodes.