 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Heterogeneity and Forgotten Labels in Split Federated Learning
Nov 12, 2025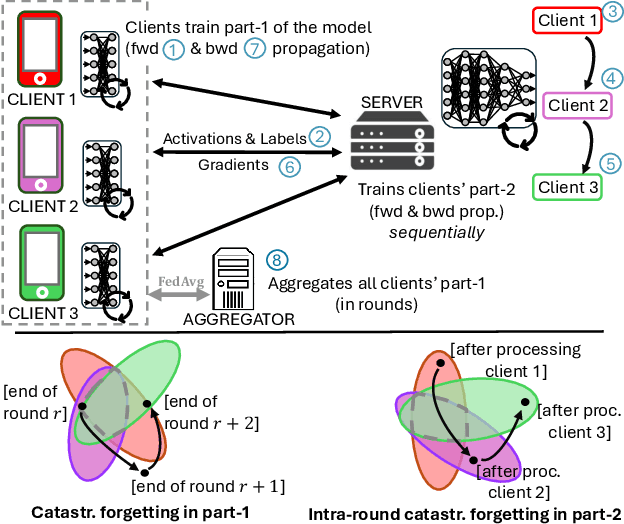
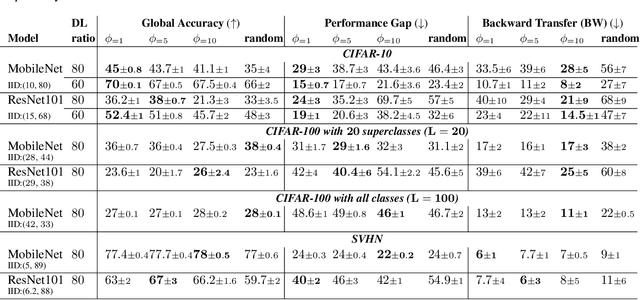


In Split Federated Learning (SFL), the clients collaboratively train a model with the help of a server by splitting the model into two parts. Part-1 is trained locally at each client and aggregated by the aggregator at the end of each round. Part-2 is trained at a server that sequentially processes the intermediate activations received from each client. We study the phenomenon of catastrophic forgetting (CF) in SFL in the presence of data heterogeneity. In detail, due to the nature of SFL, local updates of part-1 may drift away from global optima, while part-2 is sensitive to the processing sequence, similar to forgetting in continual learning (CL). Specifically, we observe that the trained model performs better in classes (labels) seen at the end of the sequence. We investigate this phenomenon with emphasis on key aspects of SFL, such as the processing order at the server and the cut layer. Based on our findings, we propose Hydra, a novel mitigation method inspired by multi-head neural networks and adapted for the SFL's setting. Extensive numerical evaluations show that Hydra outperforms baselines and methods from the literature.
PUFFLE: Balancing Privacy, Utility, and Fairness in Federated Learning
Jul 21, 2024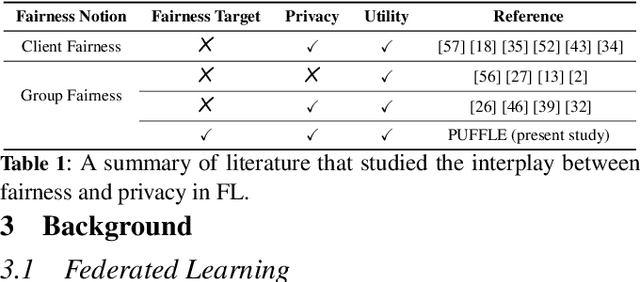
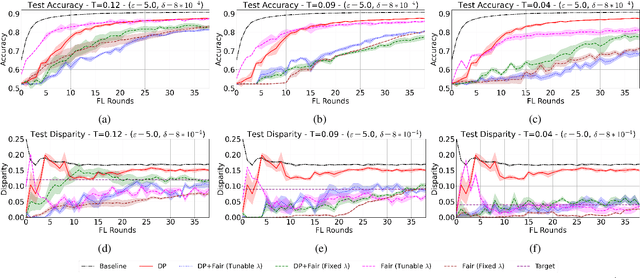
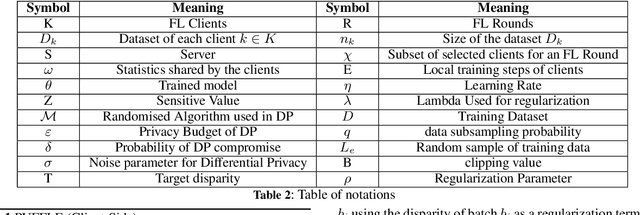
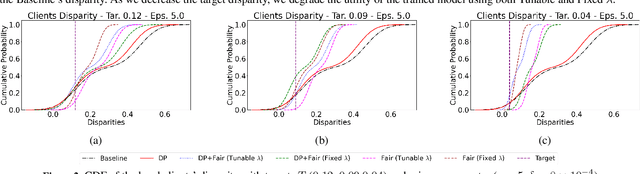
Training and deploying Machine Learning models that simultaneously adhere to principles of fairness and privacy while ensuring good utility poses a significant challenge. The interplay between these three factors of trustworthiness is frequently underestimated and remains insufficiently explored. Consequently, many efforts focus on ensuring only two of these factors, neglecting one in the process. The decentralization of the datasets and the variations in distributions among the clients exacerbate the complexity of achieving this ethical trade-off in the context of Federated Learning (FL). For the first time in FL literature, we address these three factors of trustworthiness. We introduce PUFFLE, a high-level parameterised approach that can help in the exploration of the balance between utility, privacy, and fairness in FL scenarios. We prove that PUFFLE can be effective across diverse datasets, models, and data distributions, reducing the model unfairness up to 75%, with a maximum reduction in the utility of 17% in the worst-case scenario, while maintaining strict privacy guarantees during the FL training.
Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Mar 08, 2024



As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 69 input perturbations which are intended to simulate various corruptions that ASR models may encounter in the physical and digital world. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as discrete representations, and self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females, and observed noticeable disparities in the model's robustness across subgroups. We believe that SRB will facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
Analyzing and Mitigating Bias for Vulnerable Classes: Towards Balanced Representation in Dataset
Jan 18, 2024The accuracy and fairness of perception systems in autonomous driving are crucial, particularly for vulnerable road users. Mainstream research has looked into improving the performance metrics for classification accuracy. However, the hidden traits of bias inheritance in the AI models, class imbalances and disparities in the datasets are often overlooked. In this context, our study examines the class imbalances for vulnerable road users by focusing on class distribution analysis, performance evaluation, and bias impact assessment. We identify the concern of imbalances in class representation, leading to potential biases in detection accuracy. Utilizing popular CNN models and Vision Transformers (ViTs) with the nuScenes dataset, our performance evaluation reveals detection disparities for underrepresented classes. We propose a methodology for model optimization and bias mitigation, which includes data augmentation, resampling, and metric-specific learning. Using the proposed mitigation approaches, we see improvement in IoU(%) and NDS(%) metrics from 71.3 to 75.6 and 80.6 to 83.7 respectively, for the CNN model. Similarly, for ViT, we observe improvement in IoU and NDS metrics from 74.9 to 79.2 and 83.8 to 87.1 respectively. This research contributes to developing more reliable models and datasets, enhancing inclusiveness for minority classes.