 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded-Abstention Multi-horizon Time-series Forecasting
Feb 04, 2026Multi-horizon time-series forecasting involves simultaneously making predictions for a consecutive sequence of subsequent time steps. This task arises in many application domains, such as healthcare and finance, where mispredictions can have a high cost and reduce trust. The learning with abstention framework tackles these problems by allowing a model to abstain from offering a prediction when it is at an elevated risk of making a misprediction. Unfortunately, existing abstention strategies are ill-suited for the multi-horizon setting: they target problems where a model offers a single prediction for each instance. Hence, they ignore the structured and correlated nature of the predictions offered by a multi-horizon forecaster. We formalize the problem of learning with abstention for multi-horizon forecasting setting and show that its structured nature admits a richer set of abstention problems. Concretely, we propose three natural notions of how a model could abstain for multi-horizon forecasting. We theoretically analyze each problem to derive the optimal abstention strategy and propose an algorithm that implements it. Extensive evaluation on 24 datasets shows that our proposed algorithms significantly outperforms existing baselines.
Multimodal Coordinated Online Behavior: Trade-offs and Strategies
Jul 16, 2025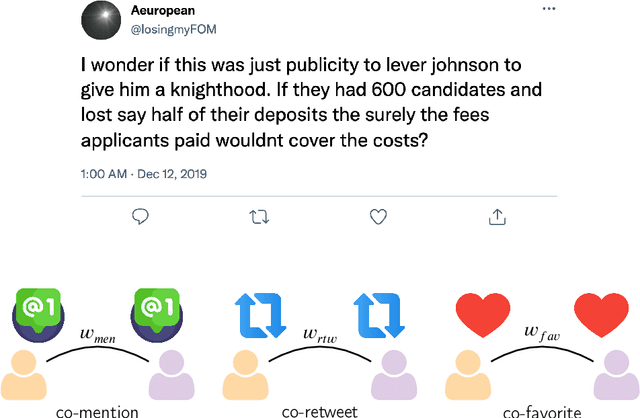



Coordinated online behavior, which spans from beneficial collective actions to harmful manipulation such as disinformation campaigns, has become a key focus in digital ecosystem analysis. Traditional methods often rely on monomodal approaches, focusing on single types of interactions like co-retweets or co-hashtags, or consider multiple modalities independently of each other. However, these approaches may overlook the complex dynamics inherent in multimodal coordination. This study compares different ways of operationalizing the detection of multimodal coordinated behavior. It examines the trade-off between weakly and strongly integrated multimodal models, highlighting the balance between capturing broader coordination patterns and identifying tightly coordinated behavior. By comparing monomodal and multimodal approaches, we assess the unique contributions of different data modalities and explore how varying implementations of multimodality impact detection outcomes. Our findings reveal that not all the modalities provide distinct insights, but that with a multimodal approach we can get a more comprehensive understanding of coordination dynamics. This work enhances the ability to detect and analyze coordinated online behavior, offering new perspectives for safeguarding the integrity of digital platforms.
Workshop Scientific HPC in the pre-Exascale era (part of ITADATA 2024) Proceedings
Mar 26, 2025The proceedings of Workshop Scientific HPC in the pre-Exascale era (SHPC), held in Pisa, Italy, September 18, 2024, are part of 3rd Italian Conference on Big Data and Data Science (ITADATA2024) proceedings (arXiv: 2503.14937). The main objective of SHPC workshop was to discuss how the current most critical questions in HPC emerge in astrophysics, cosmology, and other scientific contexts and experiments. In particular, SHPC workshop focused on: $\bullet$ Scientific (mainly in astrophysical and medical fields) applications toward (pre-)Exascale computing $\bullet$ Performance portability $\bullet$ Green computing $\bullet$ Machine learning $\bullet$ Big Data management $\bullet$ Programming on heterogeneous architectures $\bullet$ Programming on accelerators $\bullet$ I/O techniques
Proceedings of the 3rd Italian Conference on Big Data and Data Science (ITADATA2024)
Mar 19, 2025Proceedings of the 3rd Italian Conference on Big Data and Data Science (ITADATA2024), held in Pisa, Italy, September 17-19, 2024. The Italian Conference on Big Data and Data Science (ITADATA2024) is the annual event supported by the CINI Big Data National Laboratory and ISTI CNR that aims to put together Italian researchers and professionals from academia, industry, government, and public administration working in the field of big data and data science, as well as related fields (e.g., security and privacy, HPC, Cloud). ITADATA2024 covered research on all theoretical and practical aspects of Big Data and data science including data governance, data processing, data analysis, data reporting, data protection, as well as experimental studies and lessons learned. In particular, ITADATA2024 focused on - Data spaces - Data processing life cycle - Machine learning and Large Language Models - Applications of big data and data science in healthcare, finance, industry 5.0, and beyond - Data science for social network analysis
Explainable AI in Time-Sensitive Scenarios: Prefetched Offline Explanation Model
Mar 06, 2025As predictive machine learning models become increasingly adopted and advanced, their role has evolved from merely predicting outcomes to actively shaping them. This evolution has underscored the importance of Trustworthy AI, highlighting the necessity to extend our focus beyond mere accuracy and toward a comprehensive understanding of these models' behaviors within the specific contexts of their applications. To further progress in explainability, we introduce Poem, Prefetched Offline Explanation Model, a model-agnostic, local explainability algorithm for image data. The algorithm generates exemplars, counterexemplars and saliency maps to provide quick and effective explanations suitable for time-sensitive scenarios. Leveraging an existing local algorithm, \poem{} infers factual and counterfactual rules from data to create illustrative examples and opposite scenarios with an enhanced stability by design. A novel mechanism then matches incoming test points with an explanation base and produces diverse exemplars, informative saliency maps and believable counterexemplars. Experimental results indicate that Poem outperforms its predecessor Abele in speed and ability to generate more nuanced and varied exemplars alongside more insightful saliency maps and valuable counterexemplars.
Talking Back -- human input and explanations to interactive AI systems
Mar 06, 2025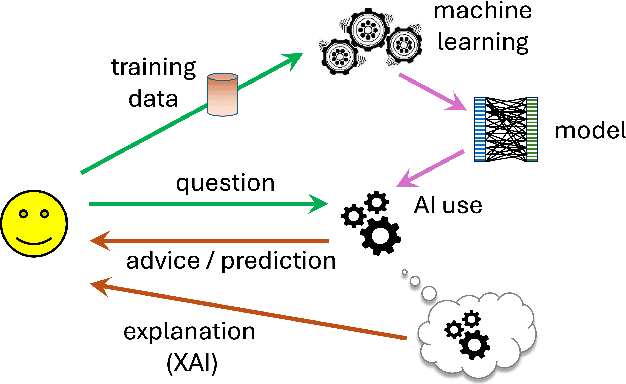

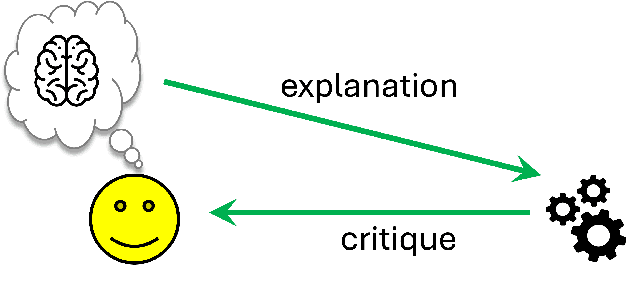
While XAI focuses on providing AI explanations to humans, can the reverse - humans explaining their judgments to AI - foster richer, synergistic human-AI systems? This paper explores various forms of human inputs to AI and examines how human explanations can guide machine learning models toward automated judgments and explanations that align more closely with human concepts.
Detection and Characterization of Coordinated Online Behavior: A Survey
Aug 02, 2024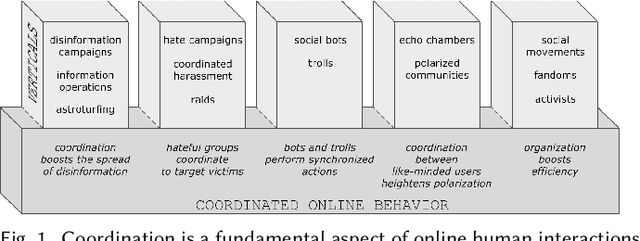

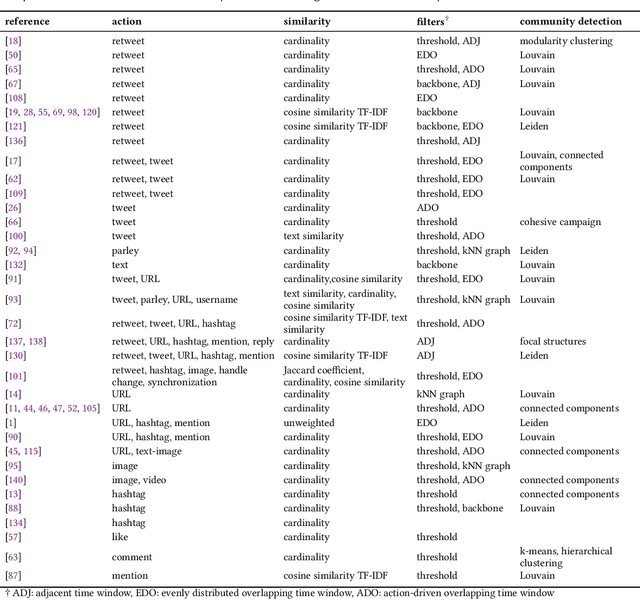
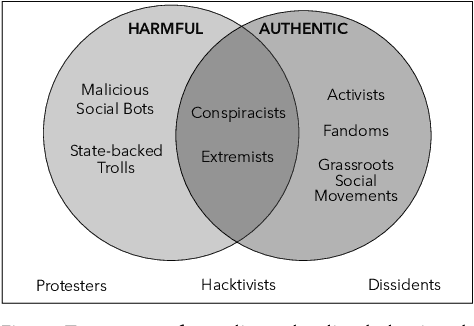
Coordination is a fundamental aspect of life. The advent of social media has made it integral also to online human interactions, such as those that characterize thriving online communities and social movements. At the same time, coordination is also core to effective disinformation, manipulation, and hate campaigns. This survey collects, categorizes, and critically discusses the body of work produced as a result of the growing interest on coordinated online behavior. We reconcile industry and academic definitions, propose a comprehensive framework to study coordinated online behavior, and review and critically discuss the existing detection and characterization methods. Our analysis identifies open challenges and promising directions of research, serving as a guide for scholars, practitioners, and policymakers in understanding and addressing the complexities inherent to online coordination.
PUFFLE: Balancing Privacy, Utility, and Fairness in Federated Learning
Jul 21, 2024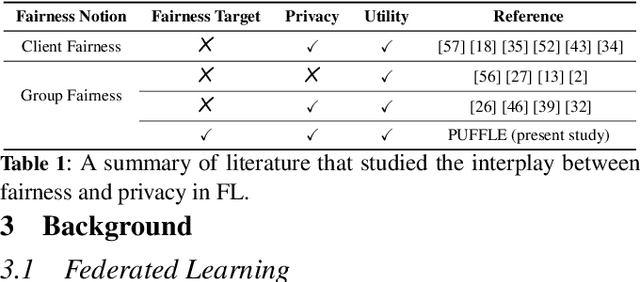
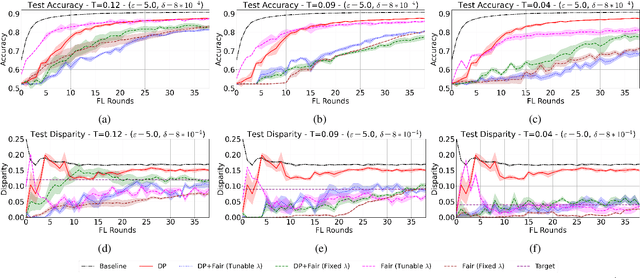
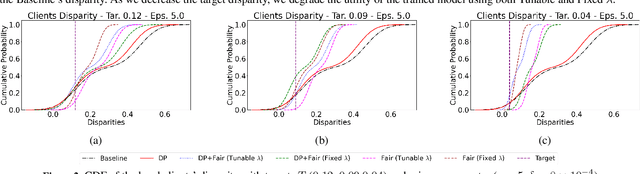
Training and deploying Machine Learning models that simultaneously adhere to principles of fairness and privacy while ensuring good utility poses a significant challenge. The interplay between these three factors of trustworthiness is frequently underestimated and remains insufficiently explored. Consequently, many efforts focus on ensuring only two of these factors, neglecting one in the process. The decentralization of the datasets and the variations in distributions among the clients exacerbate the complexity of achieving this ethical trade-off in the context of Federated Learning (FL). For the first time in FL literature, we address these three factors of trustworthiness. We introduce PUFFLE, a high-level parameterised approach that can help in the exploration of the balance between utility, privacy, and fairness in FL scenarios. We prove that PUFFLE can be effective across diverse datasets, models, and data distributions, reducing the model unfairness up to 75%, with a maximum reduction in the utility of 17% in the worst-case scenario, while maintaining strict privacy guarantees during the FL training.
A Bag of Receptive Fields for Time Series Extrinsic Predictions
Nov 29, 2023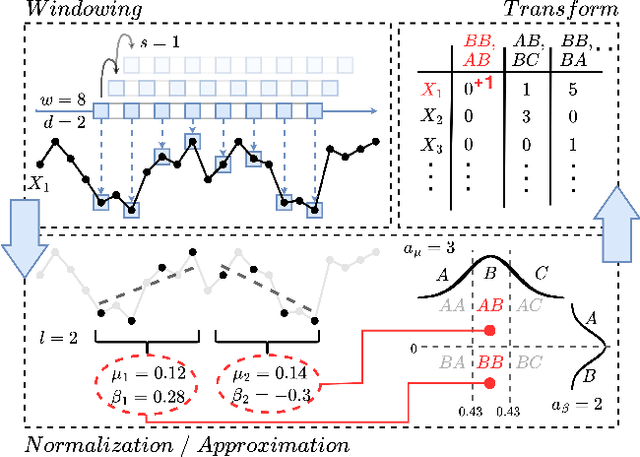
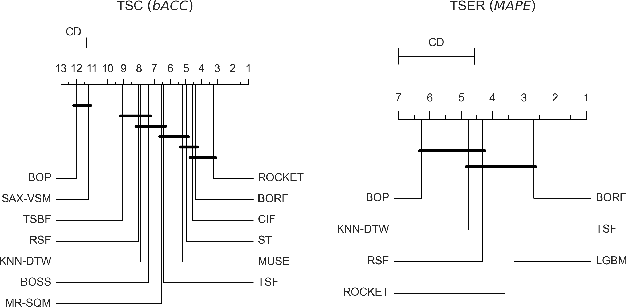
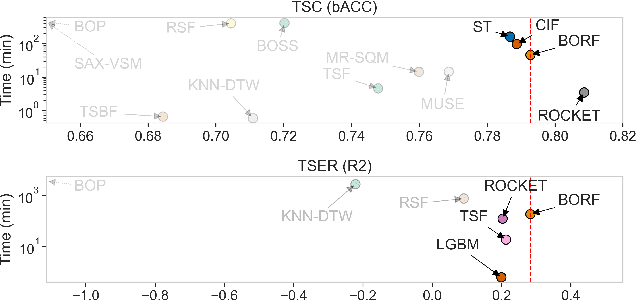
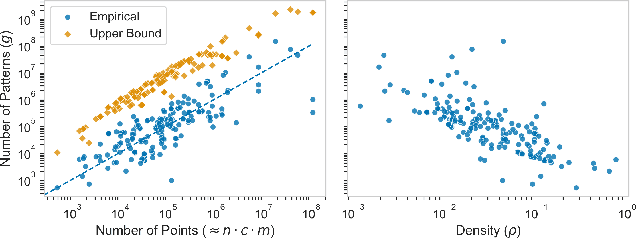
High-dimensional time series data poses challenges due to its dynamic nature, varying lengths, and presence of missing values. This kind of data requires extensive preprocessing, limiting the applicability of existing Time Series Classification and Time Series Extrinsic Regression techniques. For this reason, we propose BORF, a Bag-Of-Receptive-Fields model, which incorporates notions from time series convolution and 1D-SAX to handle univariate and multivariate time series with varying lengths and missing values. We evaluate BORF on Time Series Classification and Time Series Extrinsic Regression tasks using the full UEA and UCR repositories, demonstrating its competitive performance against state-of-the-art methods. Finally, we outline how this representation can naturally provide saliency and feature-based explanations.
Explainable Authorship Identification in Cultural Heritage Applications: Analysis of a New Perspective
Nov 03, 2023



While a substantial amount of work has recently been devoted to enhance the performance of computational Authorship Identification (AId) systems, little to no attention has been paid to endowing AId systems with the ability to explain the reasons behind their predictions. This lacking substantially hinders the practical employment of AId methodologies, since the predictions returned by such systems are hardly useful unless they are supported with suitable explanations. In this paper, we explore the applicability of existing general-purpose eXplainable Artificial Intelligence (XAI) techniques to AId, with a special focus on explanations addressed to scholars working in cultural heritage. In particular, we assess the relative merits of three different types of XAI techniques (feature ranking, probing, factuals and counterfactual selection) on three different AId tasks (authorship attribution, authorship verification, same-authorship verification) by running experiments on real AId data. Our analysis shows that, while these techniques make important first steps towards explainable Authorship Identification, more work remains to be done in order to provide tools that can be profitably integrated in the workflows of scholars.