 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForging the Forger: An Attempt to Improve Authorship Verification via Data Augmentation
Mar 17, 2024



Authorship Verification (AV) is a text classification task concerned with inferring whether a candidate text has been written by one specific author or by someone else. It has been shown that many AV systems are vulnerable to adversarial attacks, where a malicious author actively tries to fool the classifier by either concealing their writing style, or by imitating the style of another author. In this paper, we investigate the potential benefits of augmenting the classifier training set with (negative) synthetic examples. These synthetic examples are generated to imitate the style of the author of interest. We analyze the improvements in classifier prediction that this augmentation brings to bear in the task of AV in an adversarial setting. In particular, we experiment with three different generator architectures (one based on Recurrent Neural Networks, another based on small-scale transformers, and another based on the popular GPT model) and with two training strategies (one inspired by standard Language Models, and another inspired by Wasserstein Generative Adversarial Networks). We evaluate our hypothesis on five datasets (three of which have been specifically collected to represent an adversarial setting) and using two learning algorithms for the AV classifier (Support Vector Machines and Convolutional Neural Networks). This experimentation has yielded negative results, revealing that, although our methodology proves effective in many adversarial settings, its benefits are too sporadic for a pragmatical application.
Explainable Authorship Identification in Cultural Heritage Applications: Analysis of a New Perspective
Nov 03, 2023



While a substantial amount of work has recently been devoted to enhance the performance of computational Authorship Identification (AId) systems, little to no attention has been paid to endowing AId systems with the ability to explain the reasons behind their predictions. This lacking substantially hinders the practical employment of AId methodologies, since the predictions returned by such systems are hardly useful unless they are supported with suitable explanations. In this paper, we explore the applicability of existing general-purpose eXplainable Artificial Intelligence (XAI) techniques to AId, with a special focus on explanations addressed to scholars working in cultural heritage. In particular, we assess the relative merits of three different types of XAI techniques (feature ranking, probing, factuals and counterfactual selection) on three different AId tasks (authorship attribution, authorship verification, same-authorship verification) by running experiments on real AId data. Our analysis shows that, while these techniques make important first steps towards explainable Authorship Identification, more work remains to be done in order to provide tools that can be profitably integrated in the workflows of scholars.
Same or Different? Diff-Vectors for Authorship Analysis
Jan 24, 2023



We investigate the effects on authorship identification tasks of a fundamental shift in how to conceive the vectorial representations of documents that are given as input to a supervised learner. In ``classic'' authorship analysis a feature vector represents a document, the value of a feature represents (an increasing function of) the relative frequency of the feature in the document, and the class label represents the author of the document. We instead investigate the situation in which a feature vector represents an unordered pair of documents, the value of a feature represents the absolute difference in the relative frequencies (or increasing functions thereof) of the feature in the two documents, and the class label indicates whether the two documents are from the same author or not. This latter (learner-independent) type of representation has been occasionally used before, but has never been studied systematically. We argue that it is advantageous, and that in some cases (e.g., authorship verification) it provides a much larger quantity of information to the training process than the standard representation. The experiments that we carry out on several publicly available datasets (among which one that we here make available for the first time) show that feature vectors representing pairs of documents (that we here call Diff-Vectors) bring about systematic improvements in the effectiveness of authorship identification tasks, and especially so when training data are scarce (as it is often the case in real-life authorship identification scenarios). Our experiments tackle same-author verification, authorship verification, and closed-set authorship attribution; while DVs are naturally geared for solving the 1st, we also provide two novel methods for solving the 2nd and 3rd that use a solver for the 1st as a building block.
Syllabic Quantity Patterns as Rhythmic Features for Latin Authorship Attribution
Oct 27, 2021

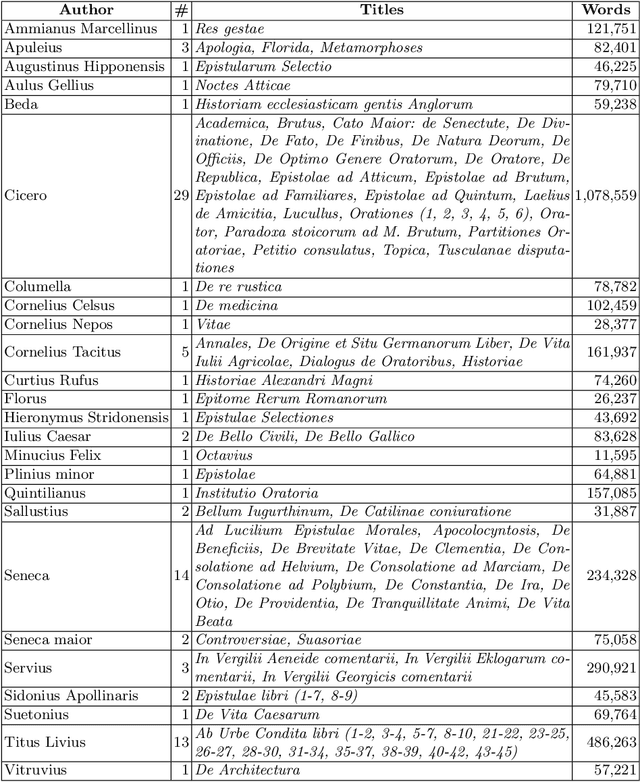

It is well known that, within the Latin production of written text, peculiar metric schemes were followed not only in poetic compositions, but also in many prose works. Such metric patterns were based on so-called syllabic quantity, i.e., on the length of the involved syllables, and there is substantial evidence suggesting that certain authors had a preference for certain metric patterns over others. In this research we investigate the possibility to employ syllabic quantity as a base for deriving rhythmic features for the task of computational authorship attribution of Latin prose texts. We test the impact of these features on the authorship attribution task when combined with other topic-agnostic features. Our experiments, carried out on three different datasets, using two different machine learning methods, show that rhythmic features based on syllabic quantity are beneficial in discriminating among Latin prose authors.
MedLatin1 and MedLatin2: Two Datasets for the Computational Authorship Analysis of Medieval Latin Texts
Jun 22, 2020
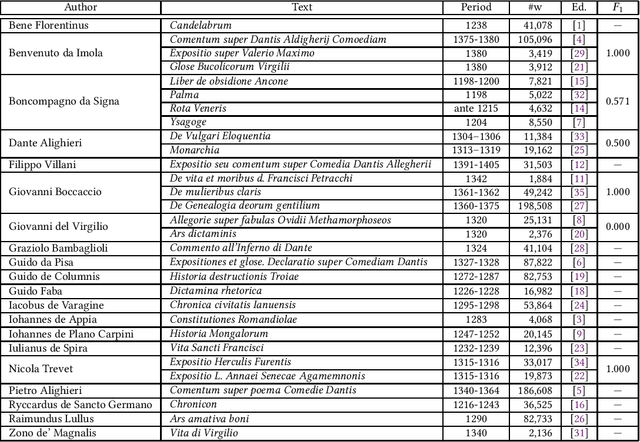
We present and make available MedLatin1 and MedLatin2, two datasets of medieval Latin texts to be used in research on computational authorship analysis. MedLatin1 and MedLatin2 consist of 294 and 30 curated texts, respectively, labelled by author, with MedLatin1 texts being of an epistolary nature and MedLatin2 texts consisting of literary comments and treatises about various subjects. As such, these two datasets lend themselves to supporting research in authorship analysis tasks, such as authorship attribution, authorship verification, or same-author verification.