Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedLatin1 and MedLatin2: Two Datasets for the Computational Authorship Analysis of Medieval Latin Texts
Jun 22, 2020
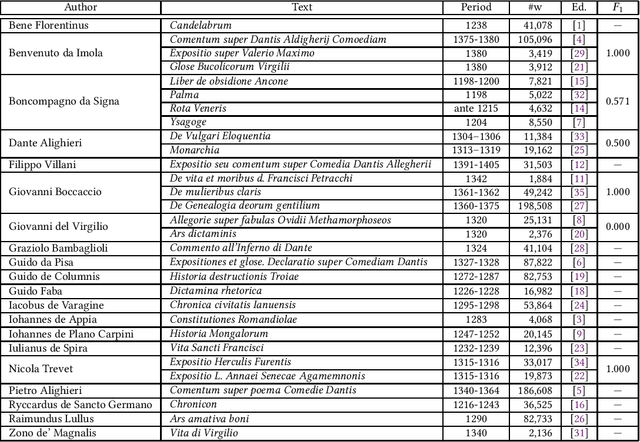
We present and make available MedLatin1 and MedLatin2, two datasets of medieval Latin texts to be used in research on computational authorship analysis. MedLatin1 and MedLatin2 consist of 294 and 30 curated texts, respectively, labelled by author, with MedLatin1 texts being of an epistolary nature and MedLatin2 texts consisting of literary comments and treatises about various subjects. As such, these two datasets lend themselves to supporting research in authorship analysis tasks, such as authorship attribution, authorship verification, or same-author verification.
Via