 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Model Selection under Prior Probability Shift
Jul 30, 2025Transductive learning is a supervised machine learning task in which, unlike in traditional inductive learning, the unlabelled data that require labelling are a finite set and are available at training time. Similarly to inductive learning contexts, transductive learning contexts may be affected by dataset shift, i.e., may be such that the IID assumption does not hold. We here propose a method, tailored to transductive classification contexts, for performing model selection (i.e., hyperparameter optimisation) when the data exhibit prior probability shift, an important type of dataset shift typical of anti-causal learning problems. In our proposed method the hyperparameters can be optimised directly on the unlabelled data to which the trained classifier must be applied; this is unlike traditional model selection methods, that are based on performing cross-validation on the labelled training data. We provide experimental results that show the benefits brought about by our method.
Quantifying Query Fairness Under Unawareness
Jun 04, 2025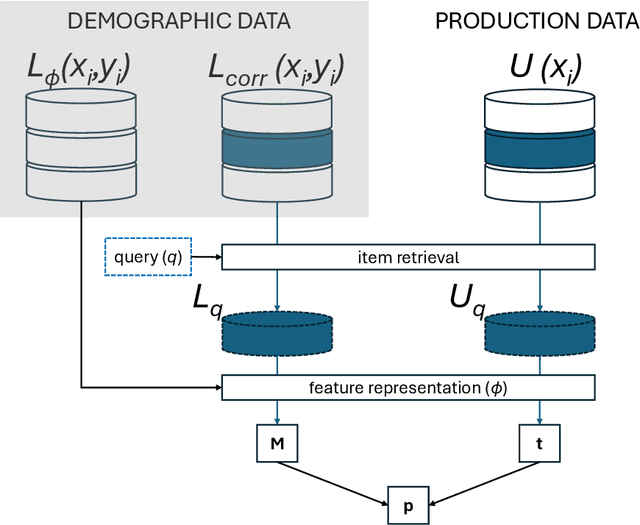

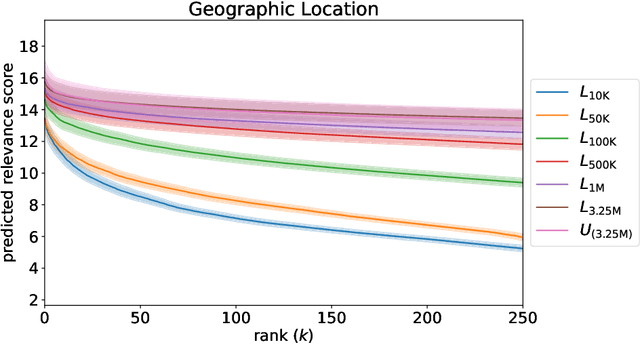

Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
Learning to quantify graph nodes
Mar 19, 2025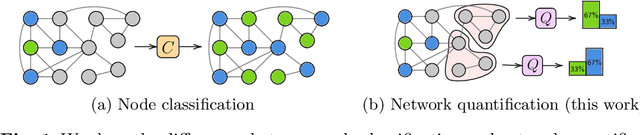
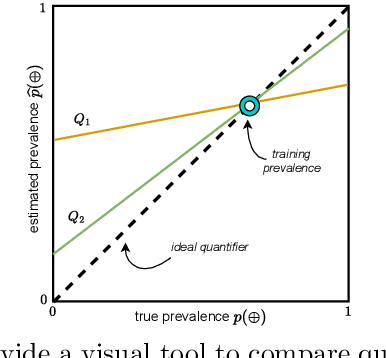
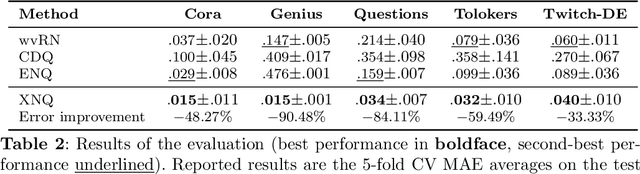
Network Quantification is the problem of estimating the class proportions in unlabeled subsets of graph nodes. When prior probability shift is at play, this task cannot be effectively addressed by first classifying the nodes and then counting the class predictions. In addition, unlike non-relational quantification on i.i.d. datapoints, Network Quantification demands enhanced flexibility to capture a broad range of connectivity patterns, resilience to the challenge of heterophily, and efficiency to scale to larger networks. To meet these stringent requirements we introduce XNQ, a novel method that synergizes the flexibility and efficiency of the unsupervised node embeddings computed by randomized recursive Graph Neural Networks, with an Expectation-Maximization algorithm that provides a robust quantification-aware adjustment to the output probabilities of a calibrated node classifier. We validate the design choices underpinning our method through comprehensive ablation experiments. In an extensive evaluation, we find that our approach consistently and significantly improves on the best Network Quantification methods to date, thereby setting the new state of the art for this challenging task. Simultaneously, it provides a training speed-up of up to 10x-100x over other graph learning based methods.
The \textit{Questio de aqua et terra}: A Computational Authorship Verification Study
Jan 07, 2025



The Questio de aqua et terra is a cosmological treatise traditionally attributed to Dante Alighieri. However, the authenticity of this text is controversial, due to discrepancies with Dante's established works and to the absence of contemporary references. This study investigates the authenticity of the Questio via computational authorship verification (AV), a class of techniques which combine supervised machine learning and stylometry. We build a family of AV systems and assemble a corpus of 330 13th- and 14th-century Latin texts, which we use to comparatively evaluate the AV systems through leave-one-out cross-validation. Our best-performing system achieves high verification accuracy (F1=0.970) despite the heterogeneity of the corpus in terms of textual genre. The key contribution to the accuracy of this system is shown to come from Distributional Random Oversampling (DRO), a technique specially tailored to text classification which is here used for the first time in AV. The application of the AV system to the Questio returns a highly confident prediction concerning its authenticity. These findings contribute to the debate on the authorship of the Questio, and highlight DRO's potential in the application of AV to cultural heritage.
Explainable Authorship Identification in Cultural Heritage Applications: Analysis of a New Perspective
Nov 03, 2023



While a substantial amount of work has recently been devoted to enhance the performance of computational Authorship Identification (AId) systems, little to no attention has been paid to endowing AId systems with the ability to explain the reasons behind their predictions. This lacking substantially hinders the practical employment of AId methodologies, since the predictions returned by such systems are hardly useful unless they are supported with suitable explanations. In this paper, we explore the applicability of existing general-purpose eXplainable Artificial Intelligence (XAI) techniques to AId, with a special focus on explanations addressed to scholars working in cultural heritage. In particular, we assess the relative merits of three different types of XAI techniques (feature ranking, probing, factuals and counterfactual selection) on three different AId tasks (authorship attribution, authorship verification, same-authorship verification) by running experiments on real AId data. Our analysis shows that, while these techniques make important first steps towards explainable Authorship Identification, more work remains to be done in order to provide tools that can be profitably integrated in the workflows of scholars.
Regularization-Based Methods for Ordinal Quantification
Oct 13, 2023Quantification, i.e., the task of training predictors of the class prevalence values in sets of unlabeled data items, has received increased attention in recent years. However, most quantification research has concentrated on developing algorithms for binary and multiclass problems in which the classes are not ordered. Here, we study the ordinal case, i.e., the case in which a total order is defined on the set of n>2 classes. We give three main contributions to this field. First, we create and make available two datasets for ordinal quantification (OQ) research that overcome the inadequacies of the previously available ones. Second, we experimentally compare the most important OQ algorithms proposed in the literature so far. To this end, we bring together algorithms proposed by authors from very different research fields, such as data mining and astrophysics, who were unaware of each others' developments. Third, we propose a novel class of regularized OQ algorithms, which outperforms existing algorithms in our experiments. The key to this gain in performance is that our regularization prevents ordinally implausible estimates, assuming that ordinal distributions tend to be smooth in practice. We informally verify this assumption for several real-world applications.
Binary Quantification and Dataset Shift: An Experimental Investigation
Oct 06, 2023Quantification is the supervised learning task that consists of training predictors of the class prevalence values of sets of unlabelled data, and is of special interest when the labelled data on which the predictor has been trained and the unlabelled data are not IID, i.e., suffer from dataset shift. To date, quantification methods have mostly been tested only on a special case of dataset shift, i.e., prior probability shift; the relationship between quantification and other types of dataset shift remains, by and large, unexplored. In this work we carry out an experimental analysis of how current quantification algorithms behave under different types of dataset shift, in order to identify limitations of current approaches and hopefully pave the way for the development of more broadly applicable methods. We do this by proposing a fine-grained taxonomy of types of dataset shift, by establishing protocols for the generation of datasets affected by these types of shift, and by testing existing quantification methods on the datasets thus generated. One finding that results from this investigation is that many existing quantification methods that had been found robust to prior probability shift are not necessarily robust to other types of dataset shift. A second finding is that no existing quantification method seems to be robust enough to dealing with all the types of dataset shift we simulate in our experiments. The code needed to reproduce all our experiments is publicly available at https://github.com/pglez82/quant_datasetshift.
Same or Different? Diff-Vectors for Authorship Analysis
Jan 24, 2023



We investigate the effects on authorship identification tasks of a fundamental shift in how to conceive the vectorial representations of documents that are given as input to a supervised learner. In ``classic'' authorship analysis a feature vector represents a document, the value of a feature represents (an increasing function of) the relative frequency of the feature in the document, and the class label represents the author of the document. We instead investigate the situation in which a feature vector represents an unordered pair of documents, the value of a feature represents the absolute difference in the relative frequencies (or increasing functions thereof) of the feature in the two documents, and the class label indicates whether the two documents are from the same author or not. This latter (learner-independent) type of representation has been occasionally used before, but has never been studied systematically. We argue that it is advantageous, and that in some cases (e.g., authorship verification) it provides a much larger quantity of information to the training process than the standard representation. The experiments that we carry out on several publicly available datasets (among which one that we here make available for the first time) show that feature vectors representing pairs of documents (that we here call Diff-Vectors) bring about systematic improvements in the effectiveness of authorship identification tasks, and especially so when training data are scarce (as it is often the case in real-life authorship identification scenarios). Our experiments tackle same-author verification, authorship verification, and closed-set authorship attribution; while DVs are naturally geared for solving the 1st, we also provide two novel methods for solving the 2nd and 3rd that use a solver for the 1st as a building block.
Multi-Label Quantification
Nov 15, 2022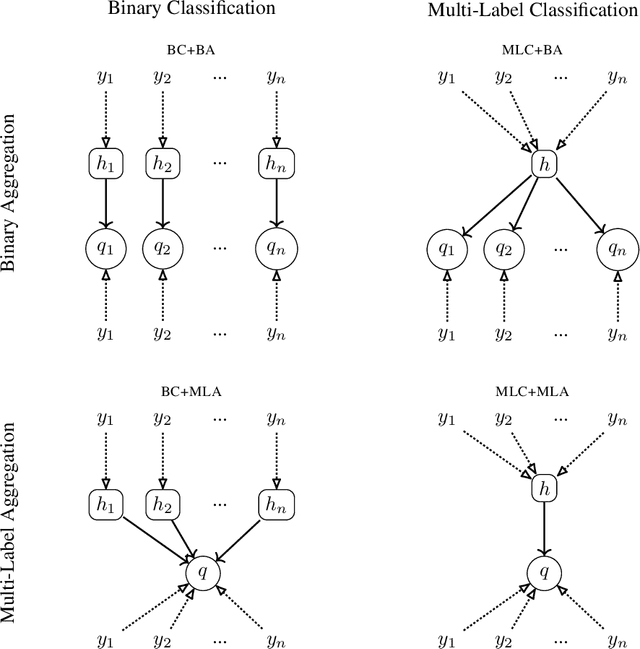
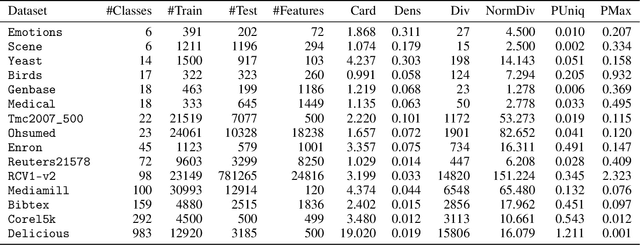
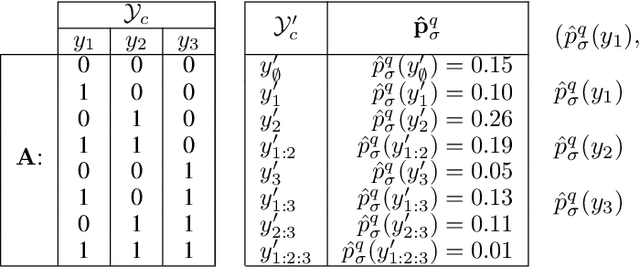

Quantification, variously called "supervised prevalence estimation" or "learning to quantify", is the supervised learning task of generating predictors of the relative frequencies (a.k.a. "prevalence values") of the classes of interest in unlabelled data samples. While many quantification methods have been proposed in the past for binary problems and, to a lesser extent, single-label multiclass problems, the multi-label setting (i.e., the scenario in which the classes of interest are not mutually exclusive) remains by and large unexplored. A straightforward solution to the multi-label quantification problem could simply consist of recasting the problem as a set of independent binary quantification problems. Such a solution is simple but na\"ive, since the independence assumption upon which it rests is, in most cases, not satisfied. In these cases, knowing the relative frequency of one class could be of help in determining the prevalence of other related classes. We propose the first truly multi-label quantification methods, i.e., methods for inferring estimators of class prevalence values that strive to leverage the stochastic dependencies among the classes of interest in order to predict their relative frequencies more accurately. We show empirical evidence that natively multi-label solutions outperform the na\"ive approaches by a large margin. The code to reproduce all our experiments is available online.
Unravelling Interlanguage Facts via Explainable Machine Learning
Aug 02, 2022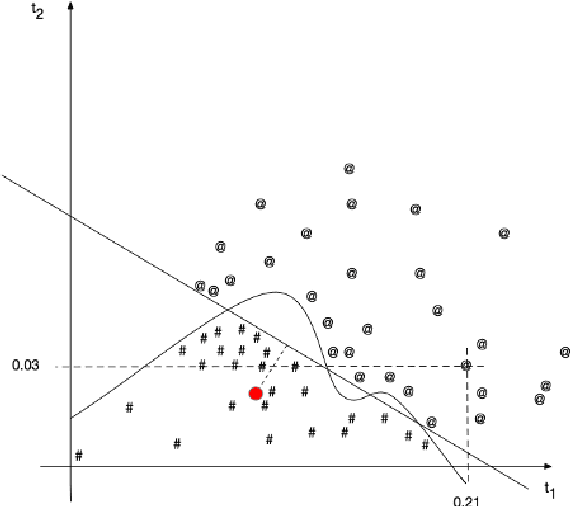
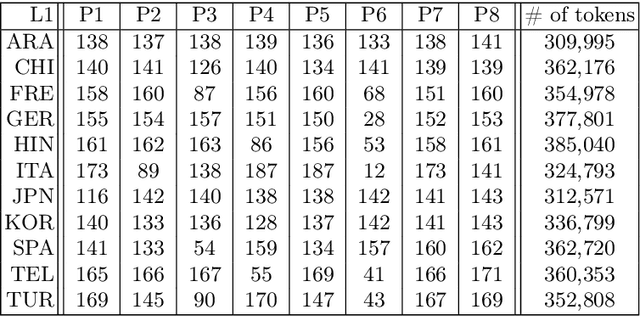
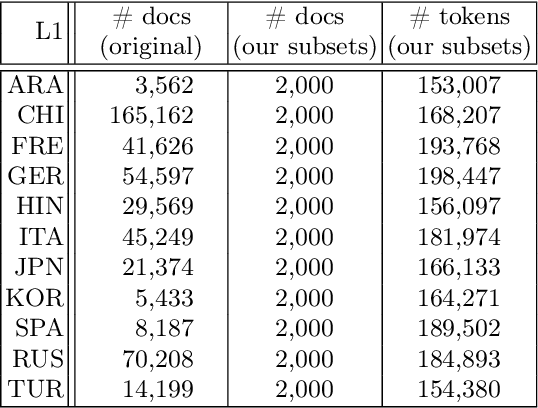
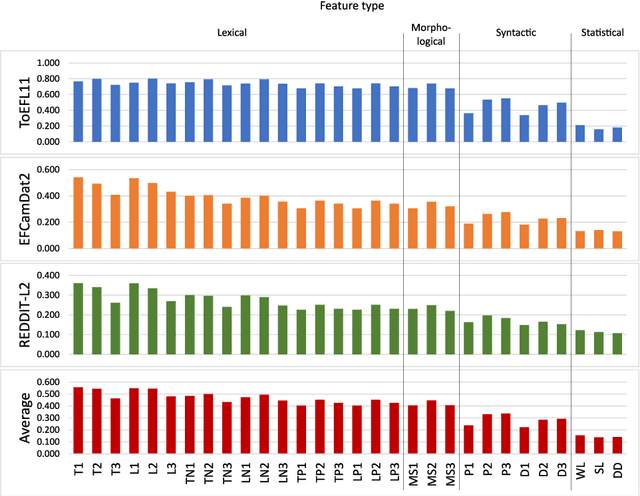
Native language identification (NLI) is the task of training (via supervised machine learning) a classifier that guesses the native language of the author of a text. This task has been extensively researched in the last decade, and the performance of NLI systems has steadily improved over the years. We focus on a different facet of the NLI task, i.e., that of analysing the internals of an NLI classifier trained by an \emph{explainable} machine learning algorithm, in order to obtain explanations of its classification decisions, with the ultimate goal of gaining insight into which linguistic phenomena ``give a speaker's native language away''. We use this perspective in order to tackle both NLI and a (much less researched) companion task, i.e., guessing whether a text has been written by a native or a non-native speaker. Using three datasets of different provenance (two datasets of English learners' essays and a dataset of social media posts), we investigate which kind of linguistic traits (lexical, morphological, syntactic, and statistical) are most effective for solving our two tasks, namely, are most indicative of a speaker's L1. We also present two case studies, one on Spanish and one on Italian learners of English, in which we analyse individual linguistic traits that the classifiers have singled out as most important for spotting these L1s. Overall, our study shows that the use of explainable machine learning can be a valuable tool for th