 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Model Selection under Prior Probability Shift
Jul 30, 2025Transductive learning is a supervised machine learning task in which, unlike in traditional inductive learning, the unlabelled data that require labelling are a finite set and are available at training time. Similarly to inductive learning contexts, transductive learning contexts may be affected by dataset shift, i.e., may be such that the IID assumption does not hold. We here propose a method, tailored to transductive classification contexts, for performing model selection (i.e., hyperparameter optimisation) when the data exhibit prior probability shift, an important type of dataset shift typical of anti-causal learning problems. In our proposed method the hyperparameters can be optimised directly on the unlabelled data to which the trained classifier must be applied; this is unlike traditional model selection methods, that are based on performing cross-validation on the labelled training data. We provide experimental results that show the benefits brought about by our method.
Quantifying Query Fairness Under Unawareness
Jun 04, 2025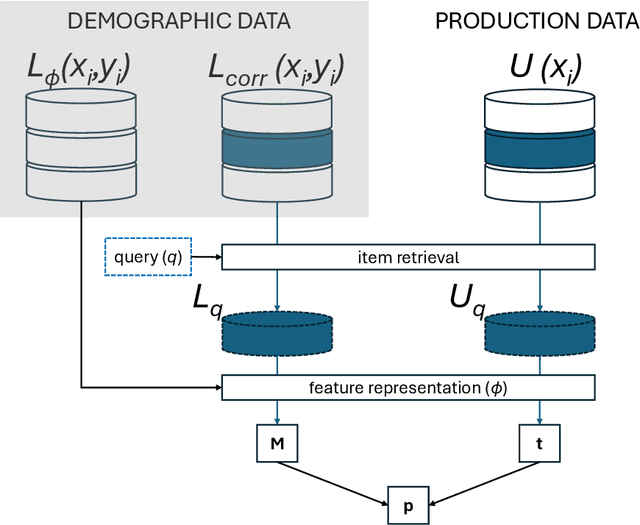

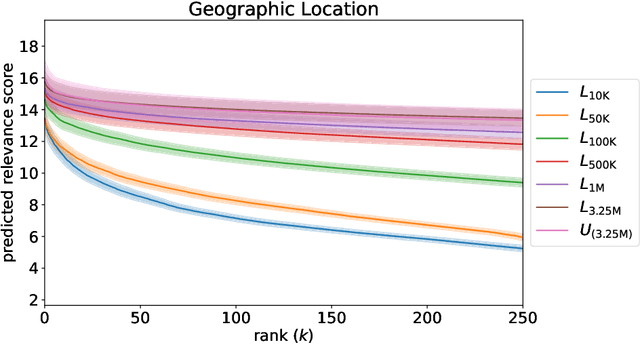

Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
On the Interconnections of Calibration, Quantification, and Classifier Accuracy Prediction under Dataset Shift
May 16, 2025When the distribution of the data used to train a classifier differs from that of the test data, i.e., under dataset shift, well-established routines for calibrating the decision scores of the classifier, estimating the proportion of positives in a test sample, or estimating the accuracy of the classifier, become particularly challenging. This paper investigates the interconnections among three fundamental problems, calibration, quantification, and classifier accuracy prediction, under dataset shift conditions. Specifically, we prove their equivalence through mutual reduction, i.e., we show that access to an oracle for any one of these tasks enables the resolution of the other two. Based on these proofs, we propose new methods for each problem based on direct adaptations of well-established methods borrowed from the other disciplines. Our results show such methods are often competitive, and sometimes even surpass the performance of dedicated approaches from each discipline. The main goal of this paper is to fostering cross-fertilization among these research areas, encouraging the development of unified approaches and promoting synergies across the fields.
Learning to quantify graph nodes
Mar 19, 2025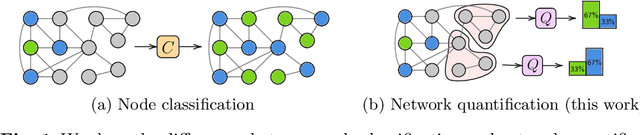
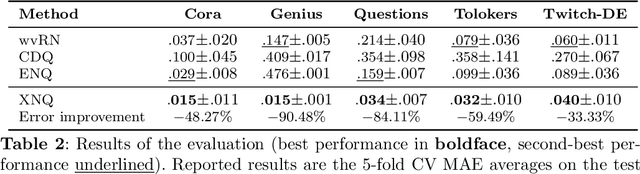
Network Quantification is the problem of estimating the class proportions in unlabeled subsets of graph nodes. When prior probability shift is at play, this task cannot be effectively addressed by first classifying the nodes and then counting the class predictions. In addition, unlike non-relational quantification on i.i.d. datapoints, Network Quantification demands enhanced flexibility to capture a broad range of connectivity patterns, resilience to the challenge of heterophily, and efficiency to scale to larger networks. To meet these stringent requirements we introduce XNQ, a novel method that synergizes the flexibility and efficiency of the unsupervised node embeddings computed by randomized recursive Graph Neural Networks, with an Expectation-Maximization algorithm that provides a robust quantification-aware adjustment to the output probabilities of a calibrated node classifier. We validate the design choices underpinning our method through comprehensive ablation experiments. In an extensive evaluation, we find that our approach consistently and significantly improves on the best Network Quantification methods to date, thereby setting the new state of the art for this challenging task. Simultaneously, it provides a training speed-up of up to 10x-100x over other graph learning based methods.
Misspellings in Natural Language Processing: A survey
Jan 28, 2025This survey provides an overview of the challenges of misspellings in natural language processing (NLP). While often unintentional, misspellings have become ubiquitous in digital communication, especially with the proliferation of Web 2.0, user-generated content, and informal text mediums such as social media, blogs, and forums. Even if humans can generally interpret misspelled text, NLP models frequently struggle to handle it: this causes a decline in performance in common tasks like text classification and machine translation. In this paper, we reconstruct a history of misspellings as a scientific problem. We then discuss the latest advancements to address the challenge of misspellings in NLP. Main strategies to mitigate the effect of misspellings include data augmentation, double step, character-order agnostic, and tuple-based methods, among others. This survey also examines dedicated data challenges and competitions to spur progress in the field. Critical safety and ethical concerns are also examined, for example, the voluntary use of misspellings to inject malicious messages and hate speech on social networks. Furthermore, the survey explores psycholinguistic perspectives on how humans process misspellings, potentially informing innovative computational techniques for text normalization and representation. Finally, the misspelling-related challenges and opportunities associated with modern large language models are also analyzed, including benchmarks, datasets, and performances of the most prominent language models against misspellings. This survey aims to be an exhaustive resource for researchers seeking to mitigate the impact of misspellings in the rapidly evolving landscape of NLP.
The \textit{Questio de aqua et terra}: A Computational Authorship Verification Study
Jan 07, 2025



The Questio de aqua et terra is a cosmological treatise traditionally attributed to Dante Alighieri. However, the authenticity of this text is controversial, due to discrepancies with Dante's established works and to the absence of contemporary references. This study investigates the authenticity of the Questio via computational authorship verification (AV), a class of techniques which combine supervised machine learning and stylometry. We build a family of AV systems and assemble a corpus of 330 13th- and 14th-century Latin texts, which we use to comparatively evaluate the AV systems through leave-one-out cross-validation. Our best-performing system achieves high verification accuracy (F1=0.970) despite the heterogeneity of the corpus in terms of textual genre. The key contribution to the accuracy of this system is shown to come from Distributional Random Oversampling (DRO), a technique specially tailored to text classification which is here used for the first time in AV. The application of the AV system to the Questio returns a highly confident prediction concerning its authenticity. These findings contribute to the debate on the authorship of the Questio, and highlight DRO's potential in the application of AV to cultural heritage.
Quantification using Permutation-Invariant Networks based on Histograms
Mar 22, 2024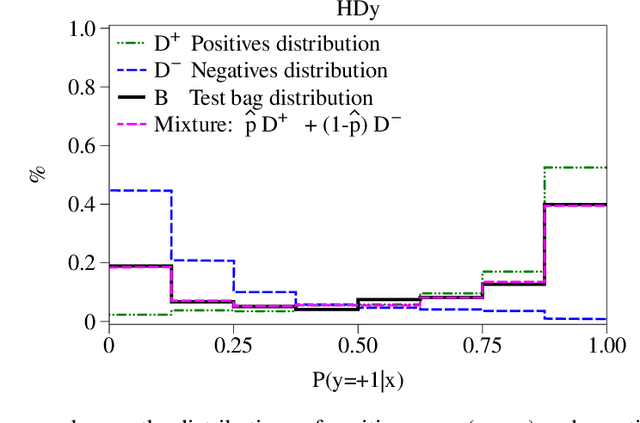
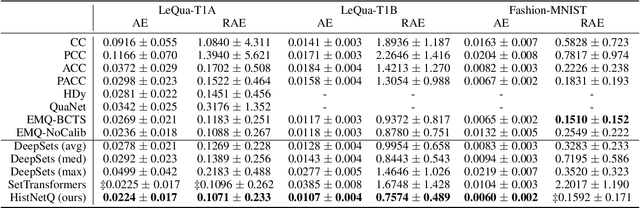
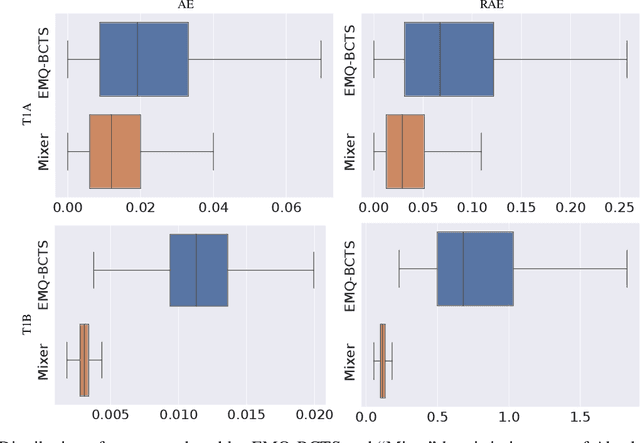
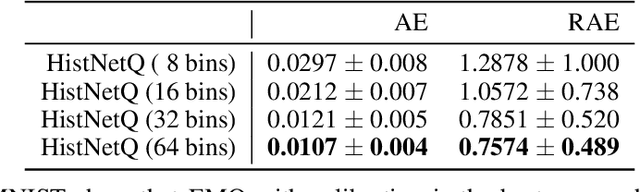
Quantification, also known as class prevalence estimation, is the supervised learning task in which a model is trained to predict the prevalence of each class in a given bag of examples. This paper investigates the application of deep neural networks to tasks of quantification in scenarios where it is possible to apply a symmetric supervised approach that eliminates the need for classification as an intermediary step, directly addressing the quantification problem. Additionally, it discusses existing permutation-invariant layers designed for set processing and assesses their suitability for quantification. In light of our analysis, we propose HistNetQ, a novel neural architecture that relies on a permutation-invariant representation based on histograms that is specially suited for quantification problems. Our experiments carried out in the only quantification competition held to date, show that HistNetQ outperforms other deep neural architectures devised for set processing, as well as the state-of-the-art quantification methods. Furthermore, HistNetQ offers two significant advantages over traditional quantification methods: i) it does not require the labels of the training examples but only the prevalence values of a collection of training bags, making it applicable to new scenarios; and ii) it is able to optimize any custom quantification-oriented loss function.
Forging the Forger: An Attempt to Improve Authorship Verification via Data Augmentation
Mar 17, 2024



Authorship Verification (AV) is a text classification task concerned with inferring whether a candidate text has been written by one specific author or by someone else. It has been shown that many AV systems are vulnerable to adversarial attacks, where a malicious author actively tries to fool the classifier by either concealing their writing style, or by imitating the style of another author. In this paper, we investigate the potential benefits of augmenting the classifier training set with (negative) synthetic examples. These synthetic examples are generated to imitate the style of the author of interest. We analyze the improvements in classifier prediction that this augmentation brings to bear in the task of AV in an adversarial setting. In particular, we experiment with three different generator architectures (one based on Recurrent Neural Networks, another based on small-scale transformers, and another based on the popular GPT model) and with two training strategies (one inspired by standard Language Models, and another inspired by Wasserstein Generative Adversarial Networks). We evaluate our hypothesis on five datasets (three of which have been specifically collected to represent an adversarial setting) and using two learning algorithms for the AV classifier (Support Vector Machines and Convolutional Neural Networks). This experimentation has yielded negative results, revealing that, although our methodology proves effective in many adversarial settings, its benefits are too sporadic for a pragmatical application.
Kernel Density Estimation for Multiclass Quantification
Jan 02, 2024

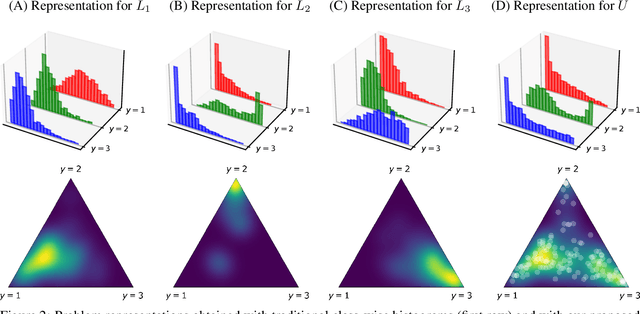
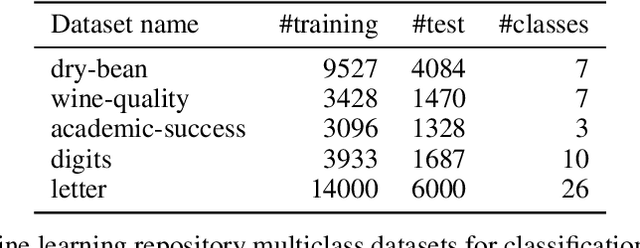
Several disciplines, like the social sciences, epidemiology, sentiment analysis, or market research, are interested in knowing the distribution of the classes in a population rather than the individual labels of the members thereof. Quantification is the supervised machine learning task concerned with obtaining accurate predictors of class prevalence, and to do so particularly in the presence of label shift. The distribution-matching (DM) approaches represent one of the most important families among the quantification methods that have been proposed in the literature so far. Current DM approaches model the involved populations by means of histograms of posterior probabilities. In this paper, we argue that their application to the multiclass setting is suboptimal since the histograms become class-specific, thus missing the opportunity to model inter-class information that may exist in the data. We propose a new representation mechanism based on multivariate densities that we model via kernel density estimation (KDE). The experiments we have carried out show our method, dubbed KDEy, yields superior quantification performance with respect to previous DM approaches. We also investigate the KDE-based representation within the maximum likelihood framework and show KDEy often shows superior performance with respect to the expectation-maximization method for quantification, arguably the strongest contender in the quantification arena to date.
Explainable Authorship Identification in Cultural Heritage Applications: Analysis of a New Perspective
Nov 03, 2023



While a substantial amount of work has recently been devoted to enhance the performance of computational Authorship Identification (AId) systems, little to no attention has been paid to endowing AId systems with the ability to explain the reasons behind their predictions. This lacking substantially hinders the practical employment of AId methodologies, since the predictions returned by such systems are hardly useful unless they are supported with suitable explanations. In this paper, we explore the applicability of existing general-purpose eXplainable Artificial Intelligence (XAI) techniques to AId, with a special focus on explanations addressed to scholars working in cultural heritage. In particular, we assess the relative merits of three different types of XAI techniques (feature ranking, probing, factuals and counterfactual selection) on three different AId tasks (authorship attribution, authorship verification, same-authorship verification) by running experiments on real AId data. Our analysis shows that, while these techniques make important first steps towards explainable Authorship Identification, more work remains to be done in order to provide tools that can be profitably integrated in the workflows of scholars.