 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Density Estimation for Multiclass Quantification
Paper and Code
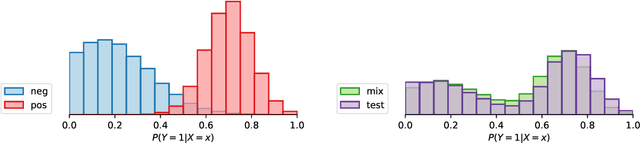

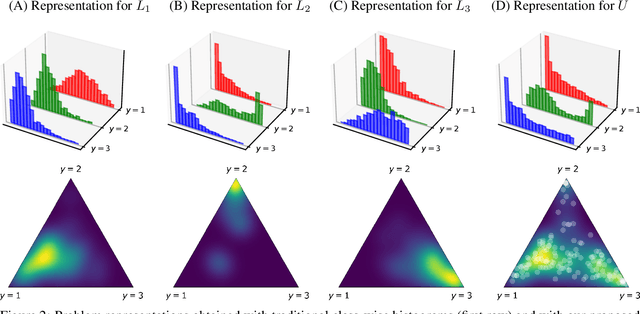
Several disciplines, like the social sciences, epidemiology, sentiment analysis, or market research, are interested in knowing the distribution of the classes in a population rather than the individual labels of the members thereof. Quantification is the supervised machine learning task concerned with obtaining accurate predictors of class prevalence, and to do so particularly in the presence of label shift. The distribution-matching (DM) approaches represent one of the most important families among the quantification methods that have been proposed in the literature so far. Current DM approaches model the involved populations by means of histograms of posterior probabilities. In this paper, we argue that their application to the multiclass setting is suboptimal since the histograms become class-specific, thus missing the opportunity to model inter-class information that may exist in the data. We propose a new representation mechanism based on multivariate densities that we model via kernel density estimation (KDE). The experiments we have carried out show our method, dubbed KDEy, yields superior quantification performance with respect to previous DM approaches. We also investigate the KDE-based representation within the maximum likelihood framework and show KDEy often shows superior performance with respect to the expectation-maximization method for quantification, arguably the strongest contender in the quantification arena to date.