 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Fact Conflicts in LLMs: Reproducibility Insights from Unifying DYNAMICQA and MULAN
Mar 16, 2026Large Language Models (LLMs) often struggle with temporal fact conflicts due to outdated or evolving information in their training data. Two recent studies with accompanying datasets report opposite conclusions on whether external context can effectively resolve such conflicts. DYNAMICQA evaluates how effective external context is in shifting the model's output distribution, finding that temporal facts are more resistant to change. In contrast, MULAN examines how often external context changes memorised facts, concluding that temporal facts are easier to update. In this reproducibility paper, we first reproduce experiments from both benchmarks. We then reproduce the experiments of each study on the dataset of the other to investigate the source of their disagreement. To enable direct comparison of findings, we standardise both datasets to align with the evaluation settings of each study. Importantly, using an LLM, we synthetically generate realistic natural language contexts to replace MULAN's programmatically constructed statements when reproducing the findings of DYNAMICQA. Our analysis reveals strong dataset dependence: MULAN's findings generalise under both methodological frameworks, whereas applying MULAN's evaluation to DYNAMICQA yields mixed outcomes. Finally, while the original studies only considered 7B LLMs, we reproduce these experiments across LLMs of varying sizes, revealing how model size influences the encoding and updating of temporal facts. Our results highlight how dataset design, evaluation metrics, and model size shape LLM behaviour in the presence of temporal knowledge conflicts.
LURE-RAG: Lightweight Utility-driven Reranking for Efficient RAG
Jan 27, 2026Most conventional Retrieval-Augmented Generation (RAG) pipelines rely on relevance-based retrieval, which often misaligns with utility -- that is, whether the retrieved passages actually improve the quality of the generated text specific to a downstream task such as question answering or query-based summarization. The limitations of existing utility-driven retrieval approaches for RAG are that, firstly, they are resource-intensive typically requiring query encoding, and that secondly, they do not involve listwise ranking loss during training. The latter limitation is particularly critical, as the relative order between documents directly affects generation in RAG. To address this gap, we propose Lightweight Utility-driven Reranking for Efficient RAG (LURE-RAG), a framework that augments any black-box retriever with an efficient LambdaMART-based reranker. Unlike prior methods, LURE-RAG trains the reranker with a listwise ranking loss guided by LLM utility, thereby directly optimizing the ordering of retrieved documents. Experiments on two standard datasets demonstrate that LURE-RAG achieves competitive performance, reaching 97-98% of the state-of-the-art dense neural baseline, while remaining efficient in both training and inference. Moreover, its dense variant, UR-RAG, significantly outperforms the best existing baseline by up to 3%.
Document Similarity Enhanced IPS Estimation for Unbiased Learning to Rank
Jul 10, 2025Learning to Rank (LTR) models learn from historical user interactions, such as user clicks. However, there is an inherent bias in the clicks of users due to position bias, i.e., users are more likely to click highly-ranked documents than low-ranked documents. To address this bias when training LTR models, many approaches from the literature re-weight the users' click data using Inverse Propensity Scoring (IPS). IPS re-weights the user's clicks proportionately to the position in the historical ranking that a document was placed when it was clicked since low-ranked documents are less likely to be seen by a user. In this paper, we argue that low-ranked documents that are similar to highly-ranked relevant documents are also likely to be relevant. Moreover, accounting for the similarity of low-ranked documents to highly ranked relevant documents when calculating IPS can more effectively mitigate the effects of position bias. Therefore, we propose an extension to IPS, called IPSsim, that takes into consideration the similarity of documents when estimating IPS. We evaluate our IPSsim estimator using two large publicly available LTR datasets under a number of simulated user click settings, and with different numbers of training clicks. Our experiments show that our IPSsim estimator is more effective than the existing IPS estimators for learning an unbiased LTR model, particularly in top-n settings when n >= 30. For example, when n = 50, our IPSsim estimator achieves a statistically significant ~3% improvement (p < 0.05) in terms of NDCG compared to the Doubly Robust estimator from the literature.
Quantifying Query Fairness Under Unawareness
Jun 04, 2025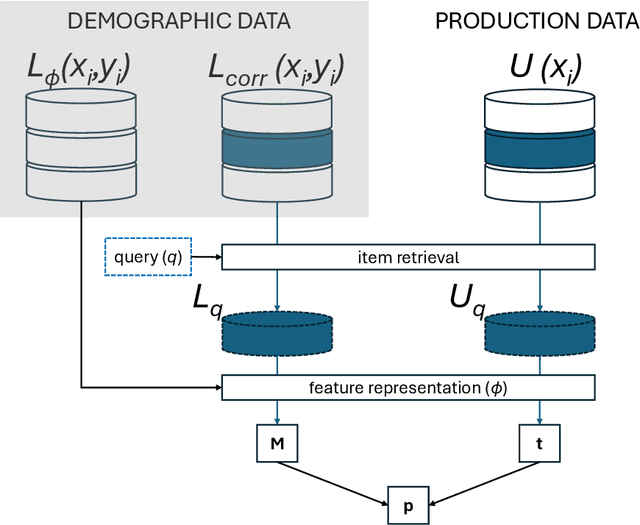

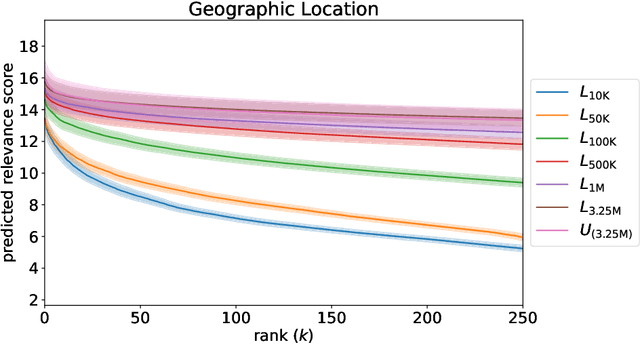

Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
Lost in Transliteration: Bridging the Script Gap in Neural IR
May 13, 2025Most human languages use scripts other than the Latin alphabet. Search users in these languages often formulate their information needs in a transliterated -- usually Latinized -- form for ease of typing. For example, Greek speakers might use Greeklish, and Arabic speakers might use Arabizi. This paper shows that current search systems, including those that use multilingual dense embeddings such as BGE-M3, do not generalise to this setting, and their performance rapidly deteriorates when exposed to transliterated queries. This creates a ``script gap" between the performance of the same queries when written in their native or transliterated form. We explore whether adapting the popular ``translate-train" paradigm to transliterations can enhance the robustness of multilingual Information Retrieval (IR) methods and bridge the gap between native and transliterated scripts. By exploring various combinations of non-Latin and Latinized query text for training, we investigate whether we can enhance the capacity of existing neural retrieval techniques and enable them to apply to this important setting. We show that by further fine-tuning IR models on an even mixture of native and Latinized text, they can perform this cross-script matching at nearly the same performance as when the query was formulated in the native script. Out-of-domain evaluation and further qualitative analysis show that transliterations can also cause queries to lose some of their nuances, motivating further research in this direction.
Are Generative AI Agents Effective Personalized Financial Advisors?
Apr 08, 2025Large language model-based agents are becoming increasingly popular as a low-cost mechanism to provide personalized, conversational advice, and have demonstrated impressive capabilities in relatively simple scenarios, such as movie recommendations. But how do these agents perform in complex high-stakes domains, where domain expertise is essential and mistakes carry substantial risk? This paper investigates the effectiveness of LLM-advisors in the finance domain, focusing on three distinct challenges: (1) eliciting user preferences when users themselves may be unsure of their needs, (2) providing personalized guidance for diverse investment preferences, and (3) leveraging advisor personality to build relationships and foster trust. Via a lab-based user study with 64 participants, we show that LLM-advisors often match human advisor performance when eliciting preferences, although they can struggle to resolve conflicting user needs. When providing personalized advice, the LLM was able to positively influence user behavior, but demonstrated clear failure modes. Our results show that accurate preference elicitation is key, otherwise, the LLM-advisor has little impact, or can even direct the investor toward unsuitable assets. More worryingly, users appear insensitive to the quality of advice being given, or worse these can have an inverse relationship. Indeed, users reported a preference for and increased satisfaction as well as emotional trust with LLMs adopting an extroverted persona, even though those agents provided worse advice.
Improving Low-Resource Retrieval Effectiveness using Zero-Shot Linguistic Similarity Transfer
Mar 28, 2025Globalisation and colonisation have led the vast majority of the world to use only a fraction of languages, such as English and French, to communicate, excluding many others. This has severely affected the survivability of many now-deemed vulnerable or endangered languages, such as Occitan and Sicilian. These languages often share some characteristics, such as elements of their grammar and lexicon, with other high-resource languages, e.g. French or Italian. They can be clustered into groups of language varieties with various degrees of mutual intelligibility. Current search systems are not usually trained on many of these low-resource varieties, leading search users to express their needs in a high-resource language instead. This problem is further complicated when most information content is expressed in a high-resource language, inhibiting even more retrieval in low-resource languages. We show that current search systems are not robust across language varieties, severely affecting retrieval effectiveness. Therefore, it would be desirable for these systems to leverage the capabilities of neural models to bridge the differences between these varieties. This can allow users to express their needs in their low-resource variety and retrieve the most relevant documents in a high-resource one. To address this, we propose fine-tuning neural rankers on pairs of language varieties, thereby exposing them to their linguistic similarities. We find that this approach improves the performance of the varieties upon which the models were directly trained, thereby regularising these models to generalise and perform better even on unseen language variety pairs. We also explore whether this approach can transfer across language families and observe mixed results that open doors for future research.
A Unified Graph Transformer for Overcoming Isolations in Multi-modal Recommendation
Jul 29, 2024With the rapid development of online multimedia services, especially in e-commerce platforms, there is a pressing need for personalised recommendation systems that can effectively encode the diverse multi-modal content associated with each item. However, we argue that existing multi-modal recommender systems typically use isolated processes for both feature extraction and modality modelling. Such isolated processes can harm the recommendation performance. Firstly, an isolated extraction process underestimates the importance of effective feature extraction in multi-modal recommendations, potentially incorporating non-relevant information, which is harmful to item representations. Second, an isolated modality modelling process produces disjointed embeddings for item modalities due to the individual processing of each modality, which leads to a suboptimal fusion of user/item representations for effective user preferences prediction. We hypothesise that the use of a unified model for addressing both aforementioned isolated processes will enable the consistent extraction and cohesive fusion of joint multi-modal features, thereby enhancing the effectiveness of multi-modal recommender systems. In this paper, we propose a novel model, called Unified Multi-modal Graph Transformer (UGT), which firstly leverages a multi-way transformer to extract aligned multi-modal features from raw data for top-k recommendation. Subsequently, we build a unified graph neural network in our UGT model to jointly fuse the user/item representations with their corresponding multi-modal features. Using the graph transformer architecture of our UGT model, we show that the UGT model can achieve significant effectiveness gains, especially when jointly optimised with the commonly-used multi-modal recommendation losses.
FusionDTI: Fine-grained Binding Discovery with Token-level Fusion for Drug-Target Interaction
Jun 03, 2024



Predicting drug-target interaction (DTI) is critical in the drug discovery process. Despite remarkable advances in recent DTI models through the integration of representations from diverse drug and target encoders, such models often struggle to capture the fine-grained interactions between drugs and protein, i.e. the binding of specific drug atoms (or substructures) and key amino acids of proteins, which is crucial for understanding the binding mechanisms and optimising drug design. To address this issue, this paper introduces a novel model, called FusionDTI, which uses a token-level Fusion module to effectively learn fine-grained information for Drug-Target Interaction. In particular, our FusionDTI model uses the SELFIES representation of drugs to mitigate sequence fragment invalidation and incorporates the structure-aware (SA) vocabulary of target proteins to address the limitation of amino acid sequences in structural information, additionally leveraging pre-trained language models extensively trained on large-scale biomedical datasets as encoders to capture the complex information of drugs and targets. Experiments on three well-known benchmark datasets show that our proposed FusionDTI model achieves the best performance in DTI prediction compared with seven existing state-of-the-art baselines. Furthermore, our case study indicates that FusionDTI could highlight the potential binding sites, enhancing the explainability of the DTI prediction.
Generative Relevance Feedback and Convergence of Adaptive Re-Ranking: University of Glasgow Terrier Team at TREC DL 2023
May 02, 2024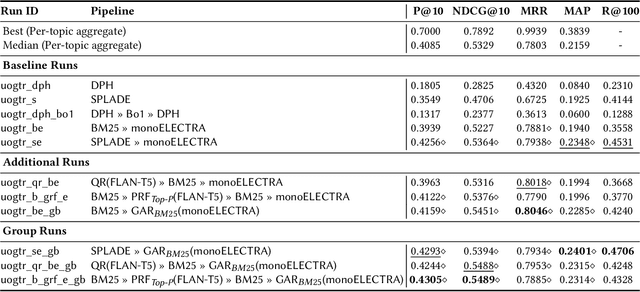
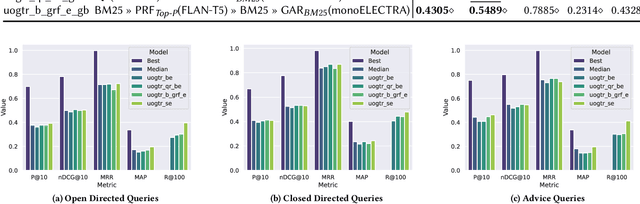
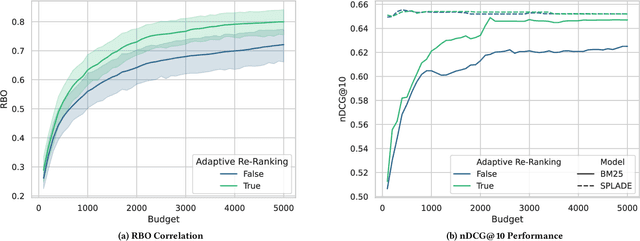
This paper describes our participation in the TREC 2023 Deep Learning Track. We submitted runs that apply generative relevance feedback from a large language model in both a zero-shot and pseudo-relevance feedback setting over two sparse retrieval approaches, namely BM25 and SPLADE. We couple this first stage with adaptive re-ranking over a BM25 corpus graph scored using a monoELECTRA cross-encoder. We investigate the efficacy of these generative approaches for different query types in first-stage retrieval. In re-ranking, we investigate operating points of adaptive re-ranking with different first stages to find the point in graph traversal where the first stage no longer has an effect on the performance of the overall retrieval pipeline. We find some performance gains from the application of generative query reformulation. However, our strongest run in terms of P@10 and nDCG@10 applied both adaptive re-ranking and generative pseudo-relevance feedback, namely uogtr_b_grf_e_gb.