 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Generative AI Agents Effective Personalized Financial Advisors?
Apr 08, 2025Large language model-based agents are becoming increasingly popular as a low-cost mechanism to provide personalized, conversational advice, and have demonstrated impressive capabilities in relatively simple scenarios, such as movie recommendations. But how do these agents perform in complex high-stakes domains, where domain expertise is essential and mistakes carry substantial risk? This paper investigates the effectiveness of LLM-advisors in the finance domain, focusing on three distinct challenges: (1) eliciting user preferences when users themselves may be unsure of their needs, (2) providing personalized guidance for diverse investment preferences, and (3) leveraging advisor personality to build relationships and foster trust. Via a lab-based user study with 64 participants, we show that LLM-advisors often match human advisor performance when eliciting preferences, although they can struggle to resolve conflicting user needs. When providing personalized advice, the LLM was able to positively influence user behavior, but demonstrated clear failure modes. Our results show that accurate preference elicitation is key, otherwise, the LLM-advisor has little impact, or can even direct the investor toward unsuitable assets. More worryingly, users appear insensitive to the quality of advice being given, or worse these can have an inverse relationship. Indeed, users reported a preference for and increased satisfaction as well as emotional trust with LLMs adopting an extroverted persona, even though those agents provided worse advice.
The Impact and Feasibility of Self-Confidence Shaping for AI-Assisted Decision-Making
Feb 20, 2025In AI-assisted decision-making, it is crucial but challenging for humans to appropriately rely on AI, especially in high-stakes domains such as finance and healthcare. This paper addresses this problem from a human-centered perspective by presenting an intervention for self-confidence shaping, designed to calibrate self-confidence at a targeted level. We first demonstrate the impact of self-confidence shaping by quantifying the upper-bound improvement in human-AI team performance. Our behavioral experiments with 121 participants show that self-confidence shaping can improve human-AI team performance by nearly 50% by mitigating both over- and under-reliance on AI. We then introduce a self-confidence prediction task to identify when our intervention is needed. Our results show that simple machine-learning models achieve 67% accuracy in predicting self-confidence. We further illustrate the feasibility of such interventions. The observed relationship between sentiment and self-confidence suggests that modifying sentiment could be a viable strategy for shaping self-confidence. Finally, we outline future research directions to support the deployment of self-confidence shaping in a real-world scenario for effective human-AI collaboration.
Beyond Turing Test: Can GPT-4 Sway Experts' Decisions?
Sep 25, 2024In the post-Turing era, evaluating large language models (LLMs) involves assessing generated text based on readers' reactions rather than merely its indistinguishability from human-produced content. This paper explores how LLM-generated text impacts readers' decisions, focusing on both amateur and expert audiences. Our findings indicate that GPT-4 can generate persuasive analyses affecting the decisions of both amateurs and professionals. Furthermore, we evaluate the generated text from the aspects of grammar, convincingness, logical coherence, and usefulness. The results highlight a high correlation between real-world evaluation through audience reactions and the current multi-dimensional evaluators commonly used for generative models. Overall, this paper shows the potential and risk of using generated text to sway human decisions and also points out a new direction for evaluating generated text, i.e., leveraging the reactions and decisions of readers. We release our dataset to assist future research.
SETN: Stock Embedding Enhanced with Textual and Network Information
Aug 06, 2024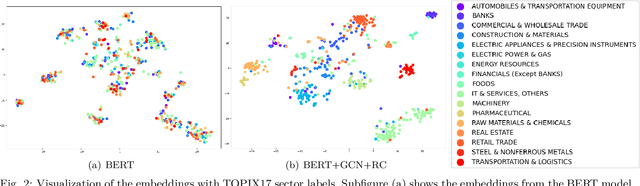
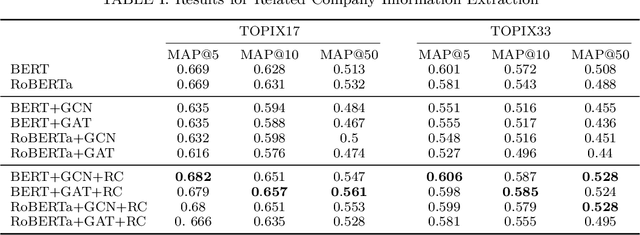
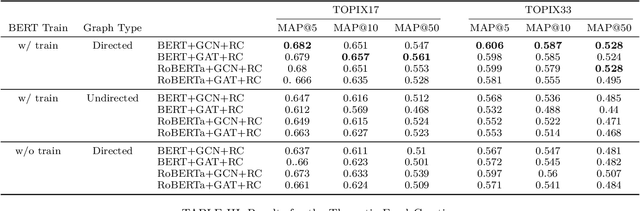
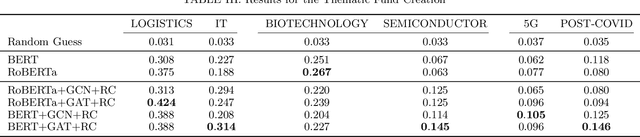
Stock embedding is a method for vector representation of stocks. There is a growing demand for vector representations of stock, i.e., stock embedding, in wealth management sectors, and the method has been applied to various tasks such as stock price prediction, portfolio optimization, and similar fund identifications. Stock embeddings have the advantage of enabling the quantification of relative relationships between stocks, and they can extract useful information from unstructured data such as text and network data. In this study, we propose stock embedding enhanced with textual and network information (SETN) using a domain-adaptive pre-trained transformer-based model to embed textual information and a graph neural network model to grasp network information. We evaluate the performance of our proposed model on related company information extraction tasks. We also demonstrate that stock embeddings obtained from the proposed model perform better in creating thematic funds than those obtained from baseline methods, providing a promising pathway for various applications in the wealth management industry.
Is ChatGPT the Future of Causal Text Mining? A Comprehensive Evaluation and Analysis
Feb 23, 2024Causality is fundamental in human cognition and has drawn attention in diverse research fields. With growing volumes of textual data, discerning causalities within text data is crucial, and causal text mining plays a pivotal role in extracting meaningful patterns. This study conducts comprehensive evaluations of ChatGPT's causal text mining capabilities. Firstly, we introduce a benchmark that extends beyond general English datasets, including domain-specific and non-English datasets. We also provide an evaluation framework to ensure fair comparisons between ChatGPT and previous approaches. Finally, our analysis outlines the limitations and future challenges in employing ChatGPT for causal text mining. Specifically, our analysis reveals that ChatGPT serves as a good starting point for various datasets. However, when equipped with a sufficient amount of training data, previous models still surpass ChatGPT's performance. Additionally, ChatGPT suffers from the tendency to falsely recognize non-causal sequences as causal sequences. These issues become even more pronounced with advanced versions of the model, such as GPT-4. In addition, we highlight the constraints of ChatGPT in handling complex causality types, including both intra/inter-sentential and implicit causality. The model also faces challenges with effectively leveraging in-context learning and domain adaptation. We release our code to support further research and development in this field.