 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization of Investment Reports Using Pre-trained Model
Aug 03, 2024
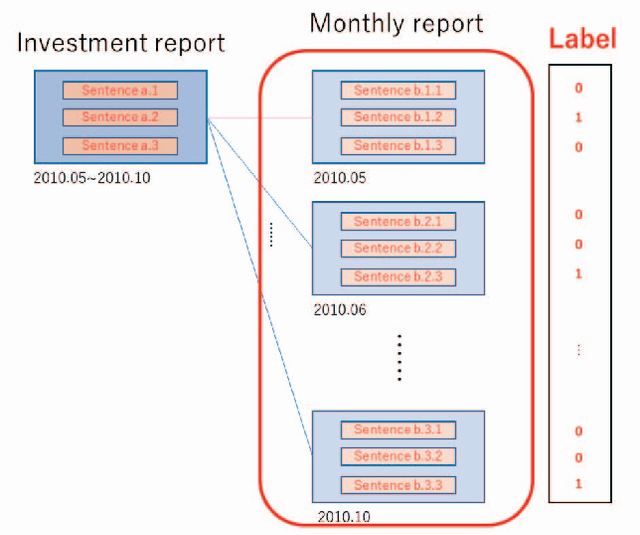
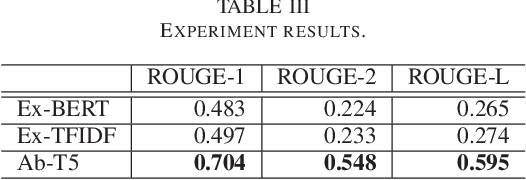

In this paper, we attempt to summarize monthly reports as investment reports. Fund managers have a wide range of tasks, one of which is the preparation of investment reports. In addition to preparing monthly reports on fund management, fund managers prepare management reports that summarize these monthly reports every six months or once a year. The preparation of fund reports is a labor-intensive and time-consuming task. Therefore, in this paper, we tackle investment summarization from monthly reports using transformer-based models. There are two main types of summarization methods: extractive summarization and abstractive summarization, and this study constructs both methods and examines which is more useful in summarizing investment reports.
Is ChatGPT the Future of Causal Text Mining? A Comprehensive Evaluation and Analysis
Feb 23, 2024Causality is fundamental in human cognition and has drawn attention in diverse research fields. With growing volumes of textual data, discerning causalities within text data is crucial, and causal text mining plays a pivotal role in extracting meaningful patterns. This study conducts comprehensive evaluations of ChatGPT's causal text mining capabilities. Firstly, we introduce a benchmark that extends beyond general English datasets, including domain-specific and non-English datasets. We also provide an evaluation framework to ensure fair comparisons between ChatGPT and previous approaches. Finally, our analysis outlines the limitations and future challenges in employing ChatGPT for causal text mining. Specifically, our analysis reveals that ChatGPT serves as a good starting point for various datasets. However, when equipped with a sufficient amount of training data, previous models still surpass ChatGPT's performance. Additionally, ChatGPT suffers from the tendency to falsely recognize non-causal sequences as causal sequences. These issues become even more pronounced with advanced versions of the model, such as GPT-4. In addition, we highlight the constraints of ChatGPT in handling complex causality types, including both intra/inter-sentential and implicit causality. The model also faces challenges with effectively leveraging in-context learning and domain adaptation. We release our code to support further research and development in this field.