 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Quantification
Nov 15, 2022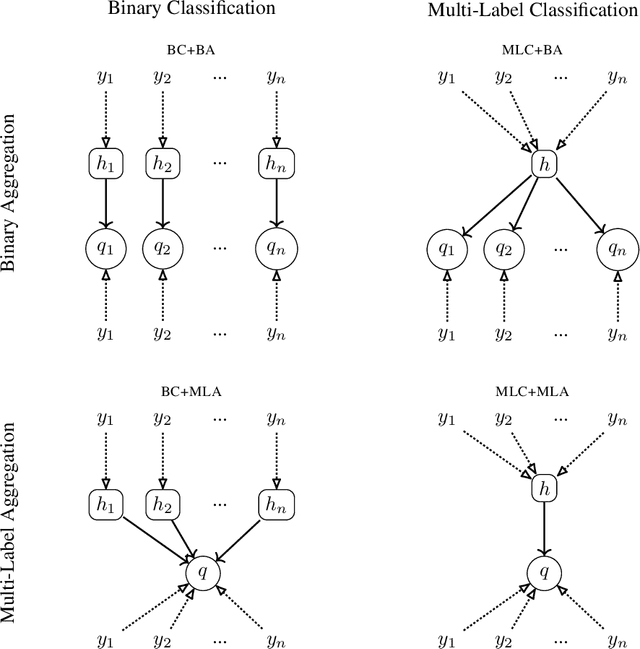
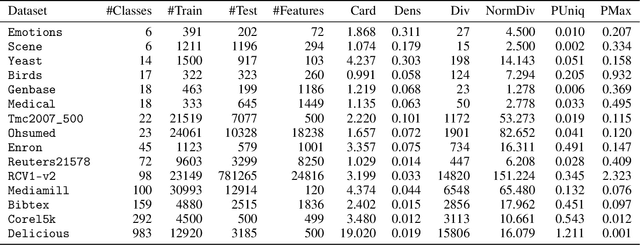
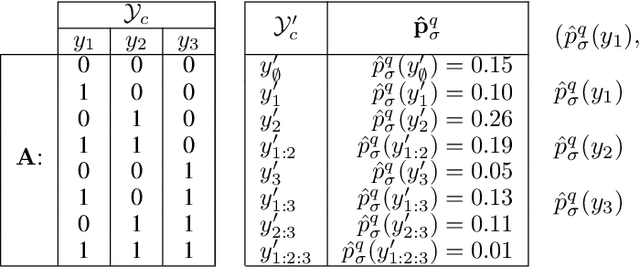

Quantification, variously called "supervised prevalence estimation" or "learning to quantify", is the supervised learning task of generating predictors of the relative frequencies (a.k.a. "prevalence values") of the classes of interest in unlabelled data samples. While many quantification methods have been proposed in the past for binary problems and, to a lesser extent, single-label multiclass problems, the multi-label setting (i.e., the scenario in which the classes of interest are not mutually exclusive) remains by and large unexplored. A straightforward solution to the multi-label quantification problem could simply consist of recasting the problem as a set of independent binary quantification problems. Such a solution is simple but na\"ive, since the independence assumption upon which it rests is, in most cases, not satisfied. In these cases, knowing the relative frequency of one class could be of help in determining the prevalence of other related classes. We propose the first truly multi-label quantification methods, i.e., methods for inferring estimators of class prevalence values that strive to leverage the stochastic dependencies among the classes of interest in order to predict their relative frequencies more accurately. We show empirical evidence that natively multi-label solutions outperform the na\"ive approaches by a large margin. The code to reproduce all our experiments is available online.
Discriminatory Expressions to Produce Interpretable Models in Microblogging Context
Nov 27, 2020
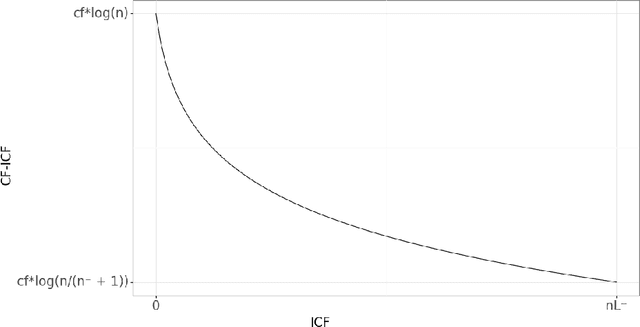

Social Networking Sites (SNS) are one of the most important ways of communication. In particular, microblogging sites are being used as analysis avenues due to their peculiarities (promptness, short texts...). There are countless researches that use SNS in novel manners, but machine learning (ML) has focused mainly in classification performance rather than interpretability and/or other goodness metrics. Thus, state-of-the-art models are black boxes that should not be used to solve problems that may have a social impact. When the problem requires transparency, it is necessary to build interpretable pipelines. Arguably, the most decisive component in the pipeline is the classifier, but it is not the only thing that we need to consider. Despite that the classifier may be interpretable, resulting models are too complex to be considered comprehensible, making it impossible for humans to comprehend the actual decisions. The purpose of this paper is to present a feature selection mechanism (the first step in the pipeline) that is able to improve comprehensibility by using less but more meaningful features while achieving a good performance in microblogging contexts where interpretability is mandatory. Moreover, we present a ranking method to evaluate features in terms of statistical relevance and bias. We conducted exhaustive tests with five different datasets in order to evaluate classification performance, generalisation capacity and actual interpretability of the model. Our results shows that our proposal is better and, by far, the most stable in terms of accuracy, generalisation and comprehensibility.