 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization-Based Methods for Ordinal Quantification
Oct 13, 2023Quantification, i.e., the task of training predictors of the class prevalence values in sets of unlabeled data items, has received increased attention in recent years. However, most quantification research has concentrated on developing algorithms for binary and multiclass problems in which the classes are not ordered. Here, we study the ordinal case, i.e., the case in which a total order is defined on the set of n>2 classes. We give three main contributions to this field. First, we create and make available two datasets for ordinal quantification (OQ) research that overcome the inadequacies of the previously available ones. Second, we experimentally compare the most important OQ algorithms proposed in the literature so far. To this end, we bring together algorithms proposed by authors from very different research fields, such as data mining and astrophysics, who were unaware of each others' developments. Third, we propose a novel class of regularized OQ algorithms, which outperforms existing algorithms in our experiments. The key to this gain in performance is that our regularization prevents ordinally implausible estimates, assuming that ordinal distributions tend to be smooth in practice. We informally verify this assumption for several real-world applications.
Noisy Labels for Weakly Supervised Gamma Hadron Classification
Aug 30, 2021



Gamma hadron classification, a central machine learning task in gamma ray astronomy, is conventionally tackled with supervised learning. However, the supervised approach requires annotated training data to be produced in sophisticated and costly simulations. We propose to instead solve gamma hadron classification with a noisy label approach that only uses unlabeled data recorded by the real telescope. To this end, we employ the significance of detection as a learning criterion which addresses this form of weak supervision. We show that models which are based on the significance of detection deliver state-of-the-art results, despite being exclusively trained with noisy labels; put differently, our models do not require the costly simulated ground-truth labels that astronomers otherwise employ for classifier training. Our weakly supervised models exhibit competitive performances also on imbalanced data sets that stem from a variety of other application domains. In contrast to existing work on class-conditional label noise, we assume that only one of the class-wise noise rates is known.
Lessons Learned from the 1st ARIEL Machine Learning Challenge: Correcting Transiting Exoplanet Light Curves for Stellar Spots
Oct 29, 2020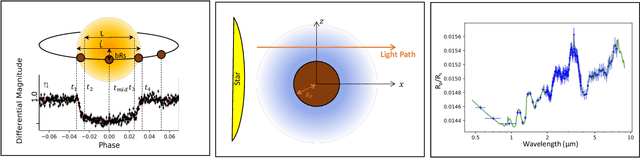

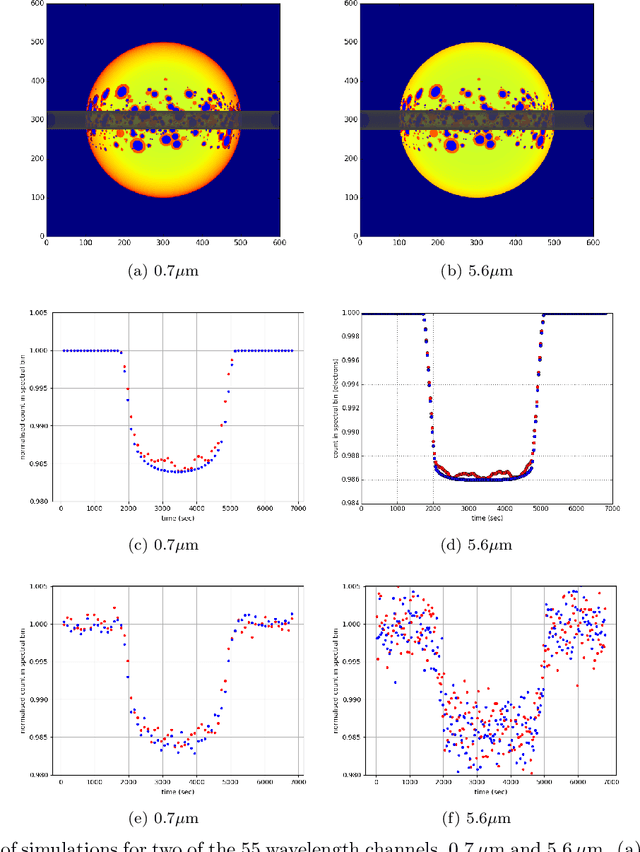
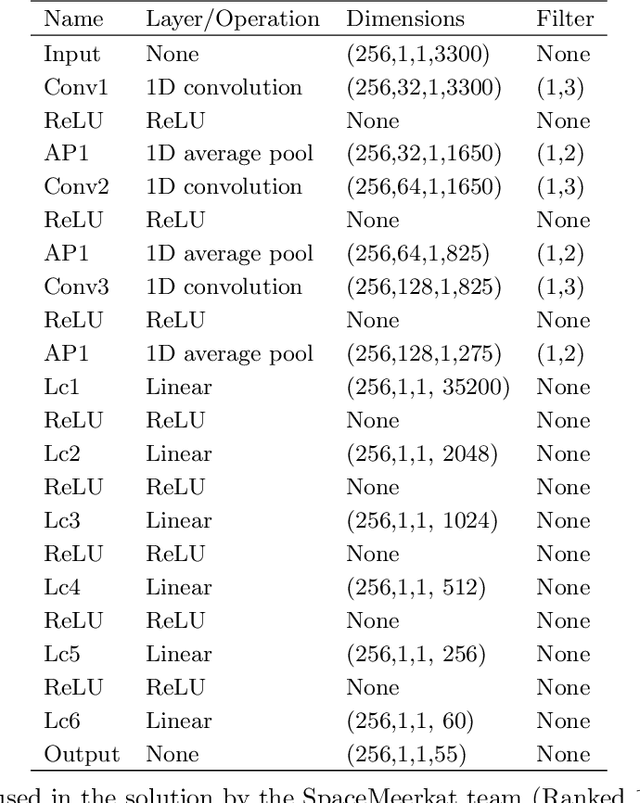
The last decade has witnessed a rapid growth of the field of exoplanet discovery and characterisation. However, several big challenges remain, many of which could be addressed using machine learning methodology. For instance, the most prolific method for detecting exoplanets and inferring several of their characteristics, transit photometry, is very sensitive to the presence of stellar spots. The current practice in the literature is to identify the effects of spots visually and correct for them manually or discard the affected data. This paper explores a first step towards fully automating the efficient and precise derivation of transit depths from transit light curves in the presence of stellar spots. The methods and results we present were obtained in the context of the 1st Machine Learning Challenge organized for the European Space Agency's upcoming Ariel mission. We first present the problem, the simulated Ariel-like data and outline the Challenge while identifying best practices for organizing similar challenges in the future. Finally, we present the solutions obtained by the top-5 winning teams, provide their code and discuss their implications. Successful solutions either construct highly non-linear (w.r.t. the raw data) models with minimal preprocessing -deep neural networks and ensemble methods- or amount to obtaining meaningful statistics from the light curves, constructing linear models on which yields comparably good predictive performance.