 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperational range bounding of spectroscopy models with anomaly detection
Aug 05, 2024Safe operation of machine learning models requires architectures that explicitly delimit their operational ranges. We evaluate the ability of anomaly detection algorithms to provide indicators correlated with degraded model performance. By placing acceptance thresholds over such indicators, hard boundaries are formed that define the model's coverage. As a use case, we consider the extraction of exoplanetary spectra from transit light curves, specifically within the context of ESA's upcoming Ariel mission. Isolation Forests are shown to effectively identify contexts where prediction models are likely to fail. Coverage/error trade-offs are evaluated under conditions of data and concept drift. The best performance is seen when Isolation Forests model projections of the prediction model's explainability SHAP values.
Peeking inside the Black Box: Interpreting Deep Learning Models for Exoplanet Atmospheric Retrievals
Nov 23, 2020
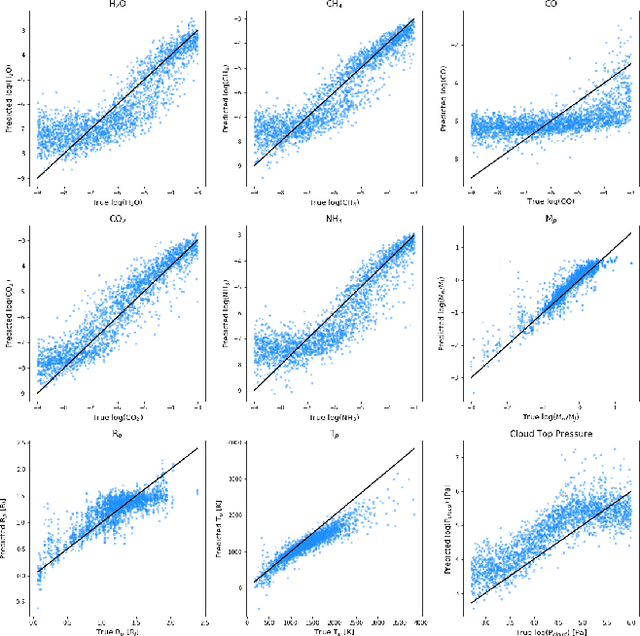
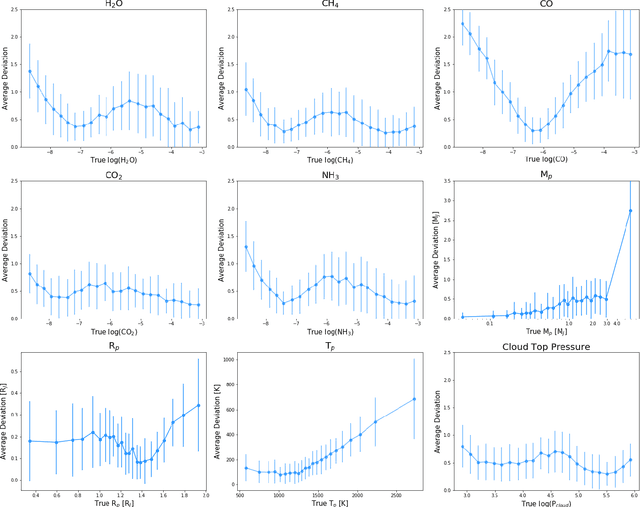

Deep learning algorithms are growing in popularity in the field of exoplanetary science due to their ability to model highly non-linear relations and solve interesting problems in a data-driven manner. Several works have attempted to perform fast retrievals of atmospheric parameters with the use of machine learning algorithms like deep neural networks (DNNs). Yet, despite their high predictive power, DNNs are also infamous for being 'black boxes'. It is their apparent lack of explainability that makes the astrophysics community reluctant to adopt them. What are their predictions based on? How confident should we be in them? When are they wrong and how wrong can they be? In this work, we present a number of general evaluation methodologies that can be applied to any trained model and answer questions like these. In particular, we train three different popular DNN architectures to retrieve atmospheric parameters from exoplanet spectra and show that all three achieve good predictive performance. We then present an extensive analysis of the predictions of DNNs, which can inform us - among other things - of the credibility limits for atmospheric parameters for a given instrument and model. Finally, we perform a perturbation-based sensitivity analysis to identify to which features of the spectrum the outcome of the retrieval is most sensitive. We conclude that for different molecules, the wavelength ranges to which the DNN's predictions are most sensitive, indeed coincide with their characteristic absorption regions. The methodologies presented in this work help to improve the evaluation of DNNs and to grant interpretability to their predictions.
PyLightcurve-torch: a transit modelling package for deep learning applications in PyTorch
Nov 03, 2020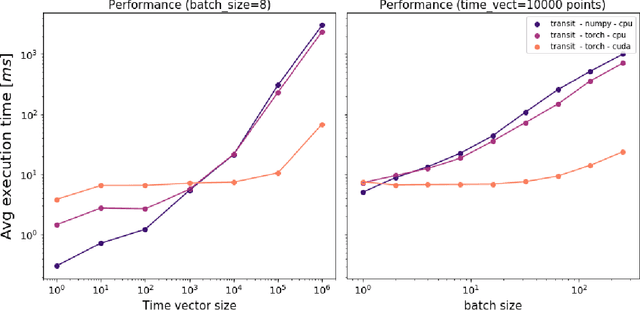
We present a new open source python package, based on PyLightcurve and PyTorch, tailored for efficient computation and automatic differentiation of exoplanetary transits. The classes and functions implemented are fully vectorised, natively GPU-compatible and differentiable with respect to the stellar and planetary parameters. This makes PyLightcurve-torch suitable for traditional forward computation of transits, but also extends the range of possible applications with inference and optimisation algorithms requiring access to the gradients of the physical model. This endeavour is aimed at fostering the use of deep learning in exoplanets research, motivated by an ever increasing amount of stellar light curves data and various incentives for the improvement of detection and characterisation techniques.
Lessons Learned from the 1st ARIEL Machine Learning Challenge: Correcting Transiting Exoplanet Light Curves for Stellar Spots
Oct 29, 2020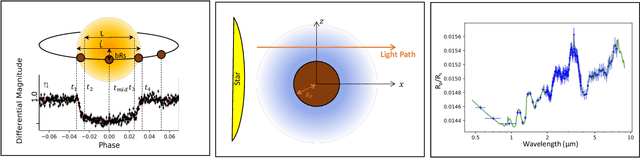

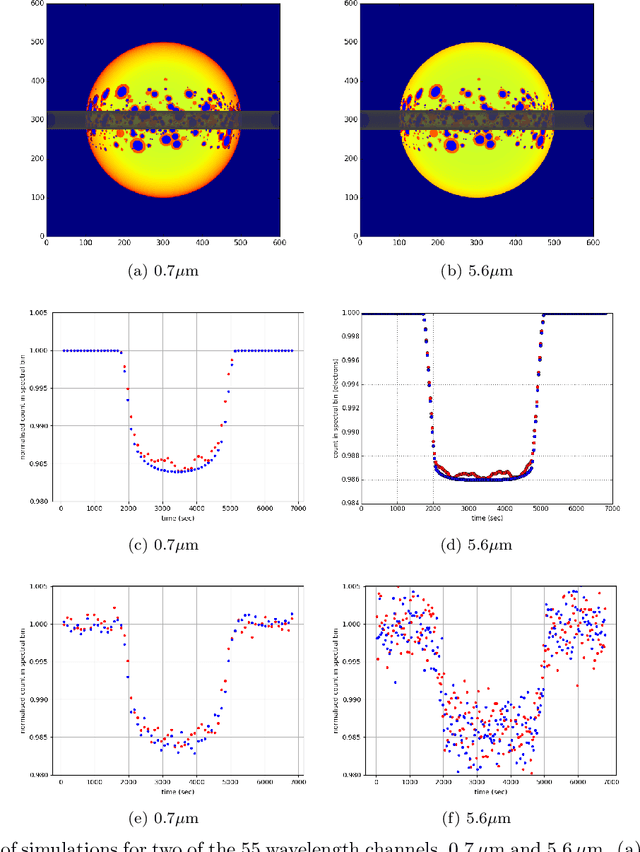
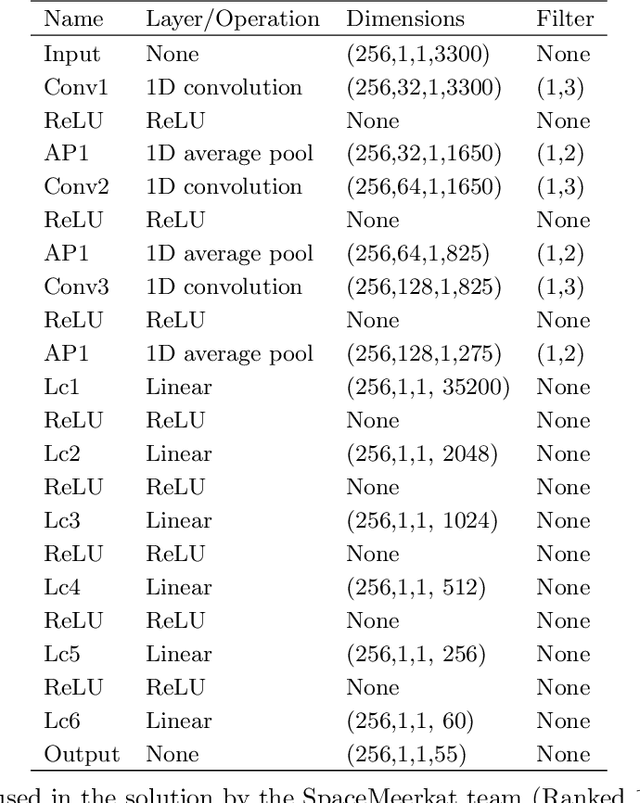
The last decade has witnessed a rapid growth of the field of exoplanet discovery and characterisation. However, several big challenges remain, many of which could be addressed using machine learning methodology. For instance, the most prolific method for detecting exoplanets and inferring several of their characteristics, transit photometry, is very sensitive to the presence of stellar spots. The current practice in the literature is to identify the effects of spots visually and correct for them manually or discard the affected data. This paper explores a first step towards fully automating the efficient and precise derivation of transit depths from transit light curves in the presence of stellar spots. The methods and results we present were obtained in the context of the 1st Machine Learning Challenge organized for the European Space Agency's upcoming Ariel mission. We first present the problem, the simulated Ariel-like data and outline the Challenge while identifying best practices for organizing similar challenges in the future. Finally, we present the solutions obtained by the top-5 winning teams, provide their code and discuss their implications. Successful solutions either construct highly non-linear (w.r.t. the raw data) models with minimal preprocessing -deep neural networks and ensemble methods- or amount to obtaining meaningful statistics from the light curves, constructing linear models on which yields comparably good predictive performance.