 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnravelling Interlanguage Facts via Explainable Machine Learning
Paper and Code
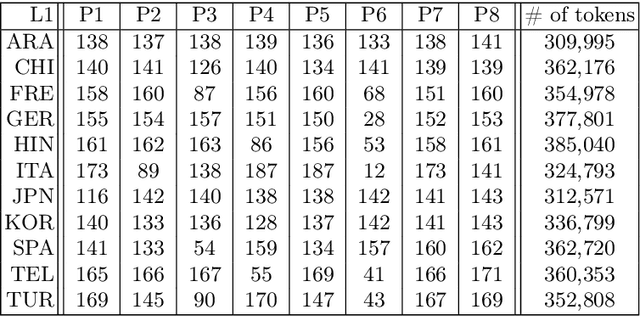
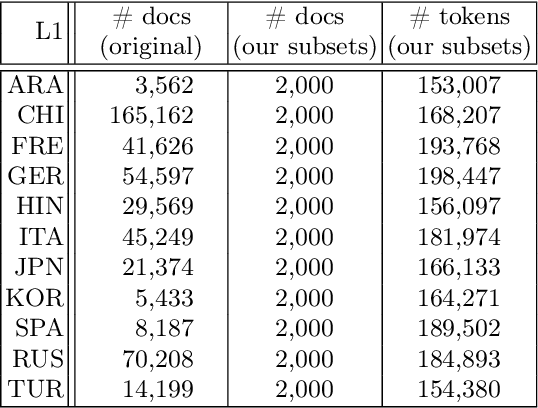
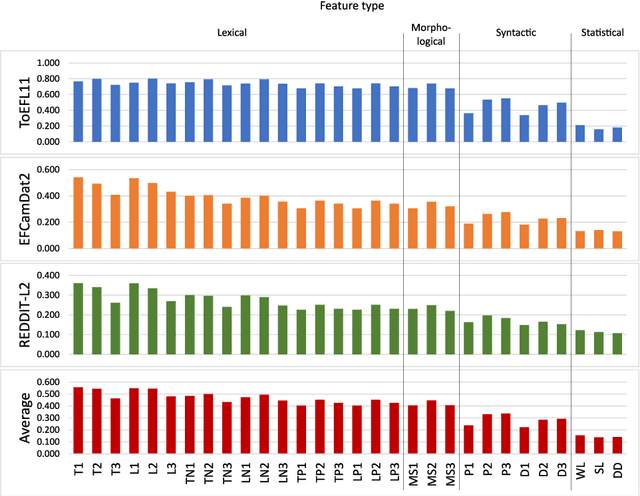
Native language identification (NLI) is the task of training (via supervised machine learning) a classifier that guesses the native language of the author of a text. This task has been extensively researched in the last decade, and the performance of NLI systems has steadily improved over the years. We focus on a different facet of the NLI task, i.e., that of analysing the internals of an NLI classifier trained by an \emph{explainable} machine learning algorithm, in order to obtain explanations of its classification decisions, with the ultimate goal of gaining insight into which linguistic phenomena ``give a speaker's native language away''. We use this perspective in order to tackle both NLI and a (much less researched) companion task, i.e., guessing whether a text has been written by a native or a non-native speaker. Using three datasets of different provenance (two datasets of English learners' essays and a dataset of social media posts), we investigate which kind of linguistic traits (lexical, morphological, syntactic, and statistical) are most effective for solving our two tasks, namely, are most indicative of a speaker's L1. We also present two case studies, one on Spanish and one on Italian learners of English, in which we analyse individual linguistic traits that the classifiers have singled out as most important for spotting these L1s. Overall, our study shows that the use of explainable machine learning can be a valuable tool for th