 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkshop Scientific HPC in the pre-Exascale era (part of ITADATA 2024) Proceedings
Mar 26, 2025The proceedings of Workshop Scientific HPC in the pre-Exascale era (SHPC), held in Pisa, Italy, September 18, 2024, are part of 3rd Italian Conference on Big Data and Data Science (ITADATA2024) proceedings (arXiv: 2503.14937). The main objective of SHPC workshop was to discuss how the current most critical questions in HPC emerge in astrophysics, cosmology, and other scientific contexts and experiments. In particular, SHPC workshop focused on: $\bullet$ Scientific (mainly in astrophysical and medical fields) applications toward (pre-)Exascale computing $\bullet$ Performance portability $\bullet$ Green computing $\bullet$ Machine learning $\bullet$ Big Data management $\bullet$ Programming on heterogeneous architectures $\bullet$ Programming on accelerators $\bullet$ I/O techniques
Proceedings of the 3rd Italian Conference on Big Data and Data Science (ITADATA2024)
Mar 19, 2025Proceedings of the 3rd Italian Conference on Big Data and Data Science (ITADATA2024), held in Pisa, Italy, September 17-19, 2024. The Italian Conference on Big Data and Data Science (ITADATA2024) is the annual event supported by the CINI Big Data National Laboratory and ISTI CNR that aims to put together Italian researchers and professionals from academia, industry, government, and public administration working in the field of big data and data science, as well as related fields (e.g., security and privacy, HPC, Cloud). ITADATA2024 covered research on all theoretical and practical aspects of Big Data and data science including data governance, data processing, data analysis, data reporting, data protection, as well as experimental studies and lessons learned. In particular, ITADATA2024 focused on - Data spaces - Data processing life cycle - Machine learning and Large Language Models - Applications of big data and data science in healthcare, finance, industry 5.0, and beyond - Data science for social network analysis
Robust Stochastic Graph Generator for Counterfactual Explanations
Dec 18, 2023



Counterfactual Explanation (CE) techniques have garnered attention as a means to provide insights to the users engaging with AI systems. While extensively researched in domains such as medical imaging and autonomous vehicles, Graph Counterfactual Explanation (GCE) methods have been comparatively under-explored. GCEs generate a new graph similar to the original one, with a different outcome grounded on the underlying predictive model. Among these GCE techniques, those rooted in generative mechanisms have received relatively limited investigation despite demonstrating impressive accomplishments in other domains, such as artistic styles and natural language modelling. The preference for generative explainers stems from their capacity to generate counterfactual instances during inference, leveraging autonomously acquired perturbations of the input graph. Motivated by the rationales above, our study introduces RSGG-CE, a novel Robust Stochastic Graph Generator for Counterfactual Explanations able to produce counterfactual examples from the learned latent space considering a partially ordered generation sequence. Furthermore, we undertake quantitative and qualitative analyses to compare RSGG-CE's performance against SoA generative explainers, highlighting its increased ability to engendering plausible counterfactual candidates.
Towards a Prediction of Machine Learning Training Time to Support Continuous Learning Systems Development
Sep 20, 2023



The problem of predicting the training time of machine learning (ML) models has become extremely relevant in the scientific community. Being able to predict a priori the training time of an ML model would enable the automatic selection of the best model both in terms of energy efficiency and in terms of performance in the context of, for instance, MLOps architectures. In this paper, we present the work we are conducting towards this direction. In particular, we present an extensive empirical study of the Full Parameter Time Complexity (FPTC) approach by Zheng et al., which is, to the best of our knowledge, the only approach formalizing the training time of ML models as a function of both dataset's and model's parameters. We study the formulations proposed for the Logistic Regression and Random Forest classifiers, and we highlight the main strengths and weaknesses of the approach. Finally, we observe how, from the conducted study, the prediction of training time is strictly related to the context (i.e., the involved dataset) and how the FPTC approach is not generalizable.
Modeling Quality and Machine Learning Pipelines through Extended Feature Models
Jul 15, 2022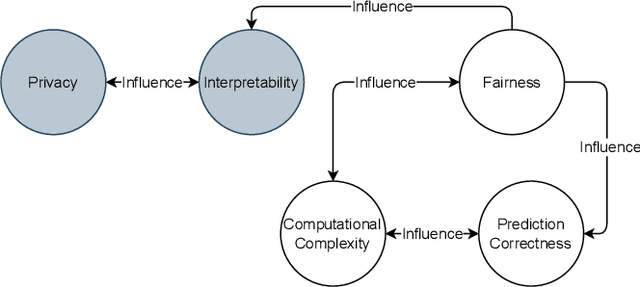

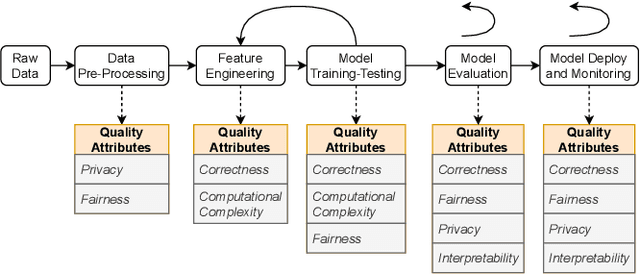
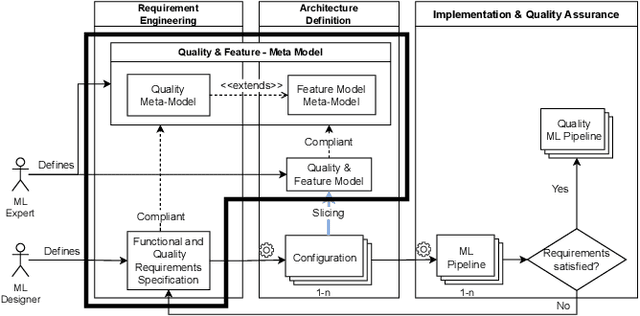
The recently increased complexity of Machine Learning (ML) methods, led to the necessity to lighten both the research and industry development processes. ML pipelines have become an essential tool for experts of many domains, data scientists and researchers, allowing them to easily put together several ML models to cover the full analytic process starting from raw datasets. Over the years, several solutions have been proposed to automate the building of ML pipelines, most of them focused on semantic aspects and characteristics of the input dataset. However, an approach taking into account the new quality concerns needed by ML systems (like fairness, interpretability, privacy, etc.) is still missing. In this paper, we first identify, from the literature, key quality attributes of ML systems. Further, we propose a new engineering approach for quality ML pipeline by properly extending the Feature Models meta-model. The presented approach allows to model ML pipelines, their quality requirements (on the whole pipeline and on single phases), and quality characteristics of algorithms used to implement each pipeline phase. Finally, we demonstrate the expressiveness of our model considering the classification problem.
GRETEL: A unified framework for Graph Counterfactual Explanation Evaluation
Jun 07, 2022
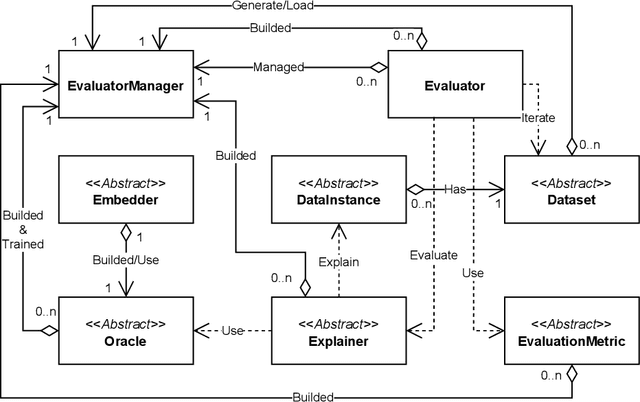
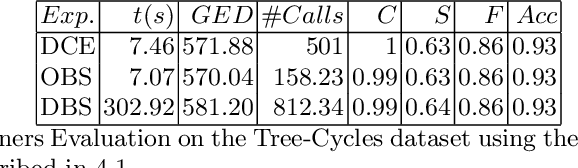
Machine Learning (ML) systems are a building part of the modern tools which impact our daily life in several application domains. Due to their black-box nature, those systems are hardly adopted in application domains (e.g. health, finance) where understanding the decision process is of paramount importance. Explanation methods were developed to explain how the ML model has taken a specific decision for a given case/instance. Graph Counterfactual Explanations (GCE) is one of the explanation techniques adopted in the Graph Learning domain. The existing works of Graph Counterfactual Explanations diverge mostly in the problem definition, application domain, test data, and evaluation metrics, and most existing works do not compare exhaustively against other counterfactual explanation techniques present in the literature. We present GRETEL, a unified framework to develop and test GCE methods in several settings. GRETEL is a highly extensible evaluation framework which promotes the Open Science and the evaluations reproducibility by providing a set of well-defined mechanisms to integrate and manage easily: both real and synthetic datasets, ML models, state-of-the-art explanation techniques, and evaluation measures. To present GRETEL, we show the experiments conducted to integrate and test several synthetic and real datasets with several existing explanation techniques and base ML models.
Unsupervised Boosting-based Autoencoder Ensembles for Outlier Detection
Oct 22, 2019


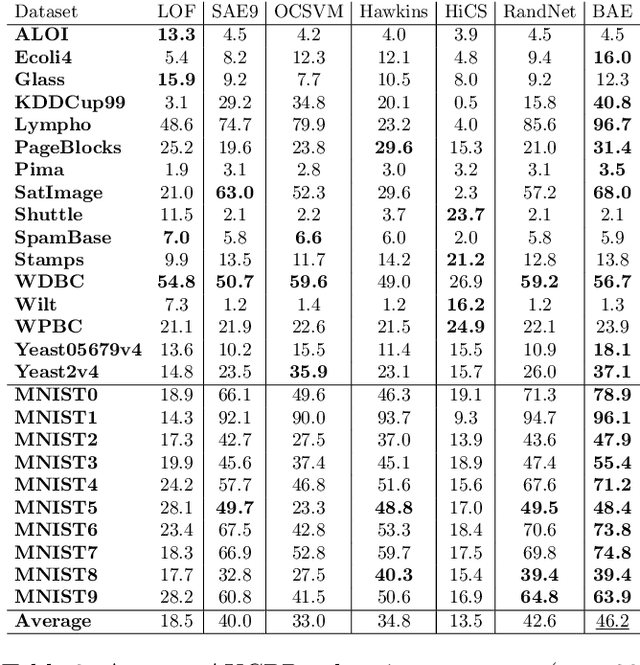
Autoencoders, as a dimensionality reduction technique, have been recently applied to outlier detection. However, neural networks are known to be vulnerable to overfitting, and therefore have limited potential in the unsupervised outlier detection setting. Current approaches to ensemble-based autoencoders do not generate a sufficient level of diversity to avoid the overfitting issue. To overcome the aforementioned limitations we develop a Boosting-based Autoencoder Ensemble approach (in short, BAE). BAE is an unsupervised ensemble method that, similarly to the boosting approach, builds an adaptive cascade of autoencoders to achieve improved and robust results. BAE trains the autoencoder components sequentially by performing a weighted sampling of the data, aimed at reducing the amount of outliers used during training, and at injecting diversity in the ensemble. We perform extensive experiments and show that the proposed methodology outperforms state-of-the-art approaches under a variety of conditions.
Graph-based Selective Outlier Ensembles
Apr 17, 2018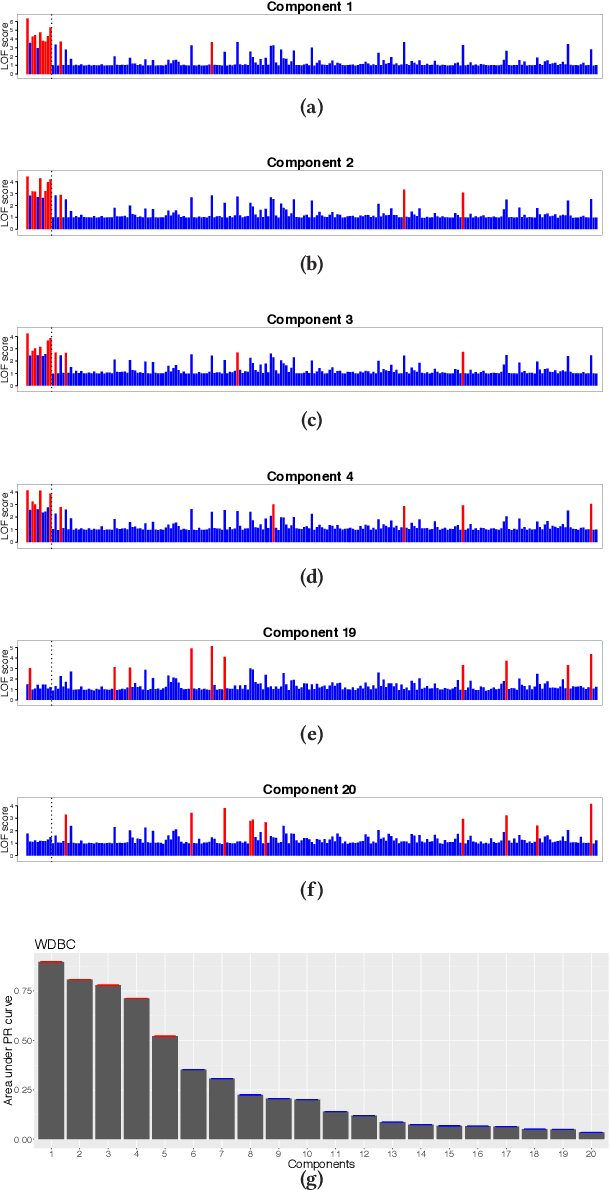

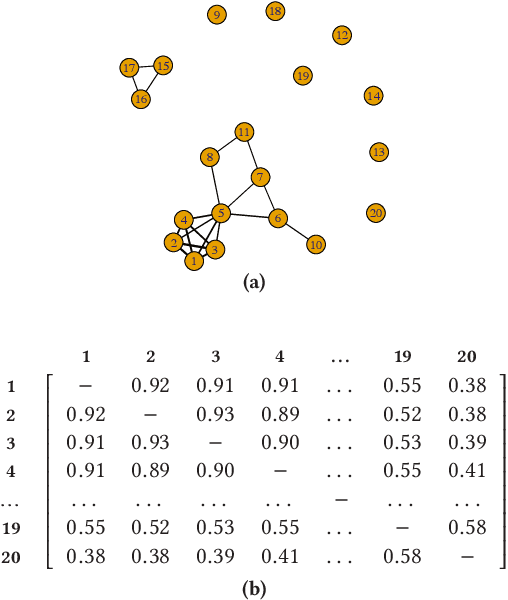
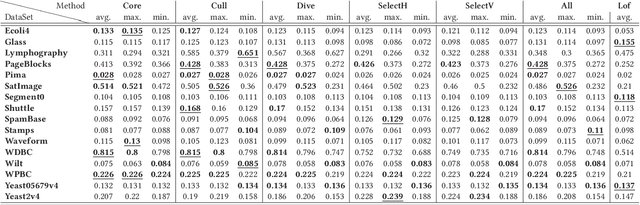
An ensemble technique is characterized by the mechanism that generates the components and by the mechanism that combines them. A common way to achieve the consensus is to enable each component to equally participate in the aggregation process. A problem with this approach is that poor components are likely to negatively affect the quality of the consensus result. To address this issue, alternatives have been explored in the literature to build selective classifier and cluster ensembles, where only a subset of the components contributes to the computation of the consensus. Of the family of ensemble methods, outlier ensembles are the least studied. Only recently, the selection problem for outlier ensembles has been discussed. In this work we define a new graph-based class of ranking selection methods. A method in this class is characterized by two main steps: (1) Mapping the rankings onto a graph structure; and (2) Mining the resulting graph to identify a subset of rankings. We define a specific instance of the graph-based ranking selection class. Specifically, we map the problem of selecting ensemble components onto a mining problem in a graph. An extensive evaluation was conducted on a variety of heterogeneous data and methods. Our empirical results show that our approach outperforms state-of-the-art selective outlier ensemble techniques.