 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalised Exponentiated Gradient Approach to Enhance Fairness in Binary and Multi-class Classification Tasks
Mar 22, 2026The widespread use of AI and ML models in sensitive areas raises significant concerns about fairness. While the research community has introduced various methods for bias mitigation in binary classification tasks, the issue remains under-explored in multi-class classification settings. To address this limitation, in this paper, we first formulate the problem of fair learning in multi-class classification as a multi-objective problem between effectiveness (i.e., prediction correctness) and multiple linear fairness constraints. Next, we propose a Generalised Exponentiated Gradient (GEG) algorithm to solve this task. GEG is an in-processing algorithm that enhances fairness in binary and multi-class classification settings under multiple fairness definitions. We conduct an extensive empirical evaluation of GEG against six baselines across seven multi-class and three binary datasets, using four widely adopted effectiveness metrics and three fairness definitions. GEG overcomes existing baselines, with fairness improvements up to 92% and a decrease in accuracy up to 14%.
REPAIR Approach for Social-based City Reconstruction Planning in case of natural disasters
Oct 21, 2025Natural disasters always have several effects on human lives. It is challenging for governments to tackle these incidents and to rebuild the economic, social and physical infrastructures and facilities with the available resources (mainly budget and time). Governments always define plans and policies according to the law and political strategies that should maximise social benefits. The severity of damage and the vast resources needed to bring life back to normality make such reconstruction a challenge. This article is the extension of our previously published work by conducting comprehensive comparative analysis by integrating additional deep learning models plus random agent which is used as a baseline. Our prior research introduced a decision support system by using the Deep Reinforcement Learning technique for the planning of post-disaster city reconstruction, maximizing the social benefit of the reconstruction process, considering available resources, meeting the needs of the broad community stakeholders (like citizens' social benefits and politicians' priorities) and keeping in consideration city's structural constraints (like dependencies among roads and buildings). The proposed approach, named post disaster REbuilding plAn ProvIdeR (REPAIR) is generic. It can determine a set of alternative plans for local administrators who select the ideal one to implement, and it can be applied to areas of any extension. We show the application of REPAIR in a real use case, i.e., to the L'Aquila reconstruction process, damaged in 2009 by a major earthquake.
How Do Generative Models Draw a Software Engineer? A Case Study on Stable Diffusion Bias
Jan 15, 2025



Generative models are nowadays widely used to generate graphical content used for multiple purposes, e.g. web, art, advertisement. However, it has been shown that the images generated by these models could reinforce societal biases already existing in specific contexts. In this paper, we focus on understanding if this is the case when one generates images related to various software engineering tasks. In fact, the Software Engineering (SE) community is not immune from gender and ethnicity disparities, which could be amplified by the use of these models. Hence, if used without consciousness, artificially generated images could reinforce these biases in the SE domain. Specifically, we perform an extensive empirical evaluation of the gender and ethnicity bias exposed by three versions of the Stable Diffusion (SD) model (a very popular open-source text-to-image model) - SD 2, SD XL, and SD 3 - towards SE tasks. We obtain 6,720 images by feeding each model with two sets of prompts describing different software-related tasks: one set includes the Software Engineer keyword, and one set does not include any specification of the person performing the task. Next, we evaluate the gender and ethnicity disparities in the generated images. Results show how all models are significantly biased towards male figures when representing software engineers. On the contrary, while SD 2 and SD XL are strongly biased towards White figures, SD 3 is slightly more biased towards Asian figures. Nevertheless, all models significantly under-represent Black and Arab figures, regardless of the prompt style used. The results of our analysis highlight severe concerns about adopting those models to generate content for SE tasks and open the field for future research on bias mitigation in this context.
On the Compression of Language Models for Code: An Empirical Study on CodeBERT
Dec 18, 2024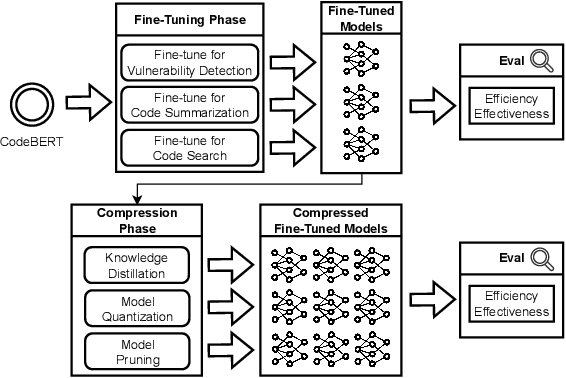
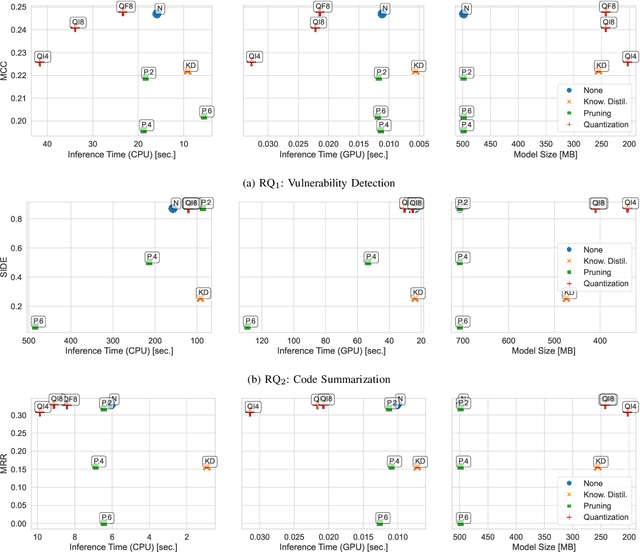
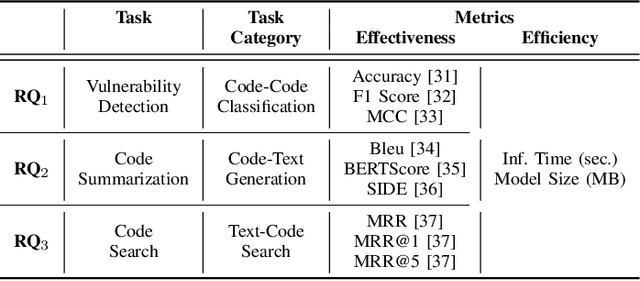
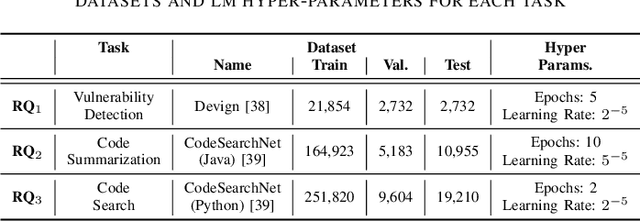
Language models have proven successful across a wide range of software engineering tasks, but their significant computational costs often hinder their practical adoption. To address this challenge, researchers have begun applying various compression strategies to improve the efficiency of language models for code. These strategies aim to optimize inference latency and memory usage, though often at the cost of reduced model effectiveness. However, there is still a significant gap in understanding how these strategies influence the efficiency and effectiveness of language models for code. Here, we empirically investigate the impact of three well-known compression strategies -- knowledge distillation, quantization, and pruning -- across three different classes of software engineering tasks: vulnerability detection, code summarization, and code search. Our findings reveal that the impact of these strategies varies greatly depending on the task and the specific compression method employed. Practitioners and researchers can use these insights to make informed decisions when selecting the most appropriate compression strategy, balancing both efficiency and effectiveness based on their specific needs.
Towards a Prediction of Machine Learning Training Time to Support Continuous Learning Systems Development
Sep 20, 2023



The problem of predicting the training time of machine learning (ML) models has become extremely relevant in the scientific community. Being able to predict a priori the training time of an ML model would enable the automatic selection of the best model both in terms of energy efficiency and in terms of performance in the context of, for instance, MLOps architectures. In this paper, we present the work we are conducting towards this direction. In particular, we present an extensive empirical study of the Full Parameter Time Complexity (FPTC) approach by Zheng et al., which is, to the best of our knowledge, the only approach formalizing the training time of ML models as a function of both dataset's and model's parameters. We study the formulations proposed for the Logistic Regression and Random Forest classifiers, and we highlight the main strengths and weaknesses of the approach. Finally, we observe how, from the conducted study, the prediction of training time is strictly related to the context (i.e., the involved dataset) and how the FPTC approach is not generalizable.
Modeling Quality and Machine Learning Pipelines through Extended Feature Models
Jul 15, 2022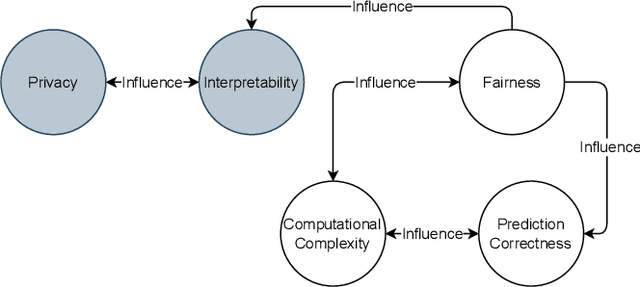

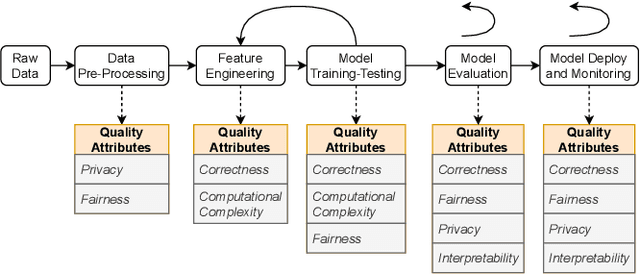
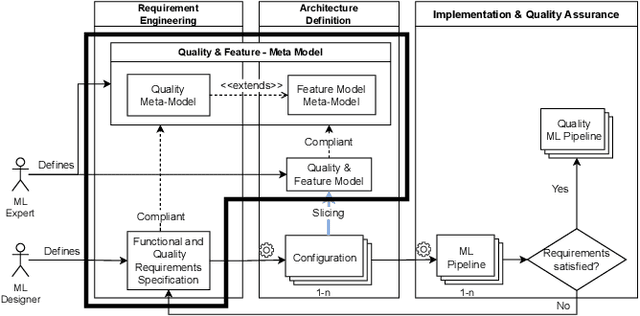
The recently increased complexity of Machine Learning (ML) methods, led to the necessity to lighten both the research and industry development processes. ML pipelines have become an essential tool for experts of many domains, data scientists and researchers, allowing them to easily put together several ML models to cover the full analytic process starting from raw datasets. Over the years, several solutions have been proposed to automate the building of ML pipelines, most of them focused on semantic aspects and characteristics of the input dataset. However, an approach taking into account the new quality concerns needed by ML systems (like fairness, interpretability, privacy, etc.) is still missing. In this paper, we first identify, from the literature, key quality attributes of ML systems. Further, we propose a new engineering approach for quality ML pipeline by properly extending the Feature Models meta-model. The presented approach allows to model ML pipelines, their quality requirements (on the whole pipeline and on single phases), and quality characteristics of algorithms used to implement each pipeline phase. Finally, we demonstrate the expressiveness of our model considering the classification problem.