 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel-Based Approach for Accurate Steady-State Detection in Performance Time Series
Jun 04, 2025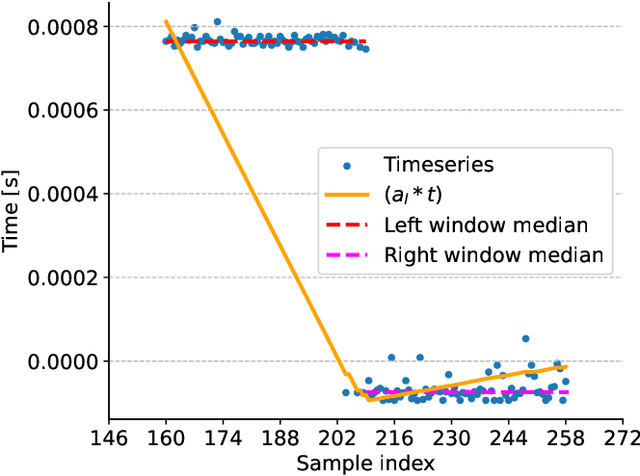
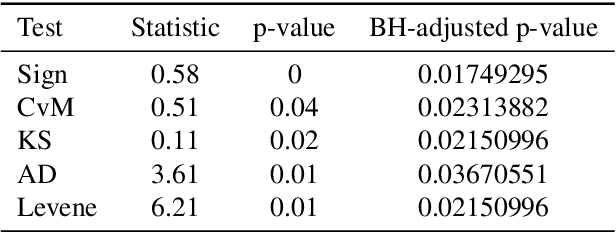

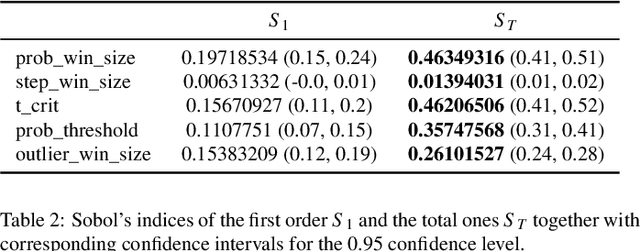
This paper addresses the challenge of accurately detecting the transition from the warmup phase to the steady state in performance metric time series, which is a critical step for effective benchmarking. The goal is to introduce a method that avoids premature or delayed detection, which can lead to inaccurate or inefficient performance analysis. The proposed approach adapts techniques from the chemical reactors domain, detecting steady states online through the combination of kernel-based step detection and statistical methods. By using a window-based approach, it provides detailed information and improves the accuracy of identifying phase transitions, even in noisy or irregular time series. Results show that the new approach reduces total error by 14.5% compared to the state-of-the-art method. It offers more reliable detection of the steady-state onset, delivering greater precision for benchmarking tasks. For users, the new approach enhances the accuracy and stability of performance benchmarking, efficiently handling diverse time series data. Its robustness and adaptability make it a valuable tool for real-world performance evaluation, ensuring consistent and reproducible results.
Investigating Execution-Aware Language Models for Code Optimization
Mar 11, 2025



Code optimization is the process of enhancing code efficiency, while preserving its intended functionality. This process often requires a deep understanding of the code execution behavior at run-time to identify and address inefficiencies effectively. Recent studies have shown that language models can play a significant role in automating code optimization. However, these models may have insufficient knowledge of how code execute at run-time. To address this limitation, researchers have developed strategies that integrate code execution information into language models. These strategies have shown promise, enhancing the effectiveness of language models in various software engineering tasks. However, despite the close relationship between code execution behavior and efficiency, the specific impact of these strategies on code optimization remains largely unexplored. This study investigates how incorporating code execution information into language models affects their ability to optimize code. Specifically, we apply three different training strategies to incorporate four code execution aspects -- line executions, line coverage, branch coverage, and variable states -- into CodeT5+, a well-known language model for code. Our results indicate that execution-aware models provide limited benefits compared to the standard CodeT5+ model in optimizing code.
On the Compression of Language Models for Code: An Empirical Study on CodeBERT
Dec 18, 2024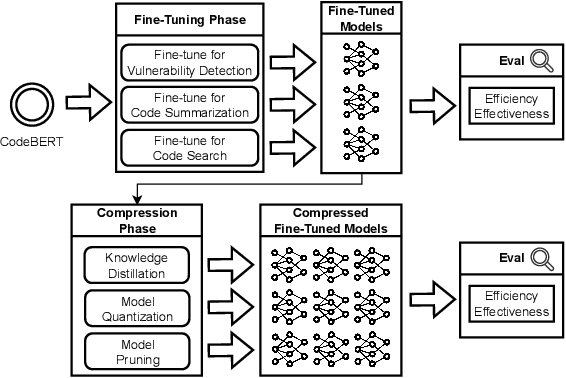
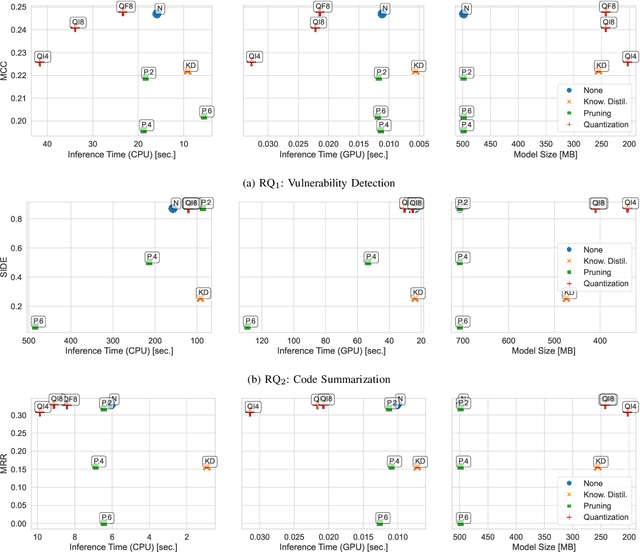
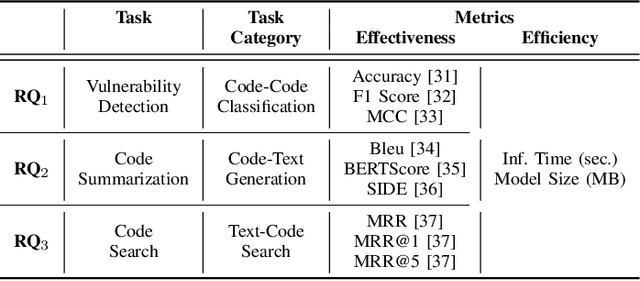
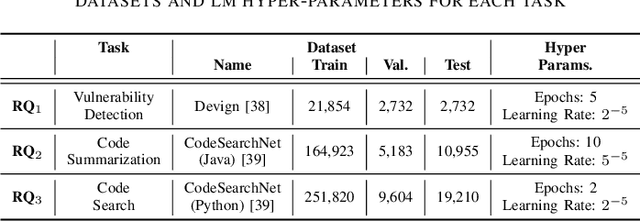
Language models have proven successful across a wide range of software engineering tasks, but their significant computational costs often hinder their practical adoption. To address this challenge, researchers have begun applying various compression strategies to improve the efficiency of language models for code. These strategies aim to optimize inference latency and memory usage, though often at the cost of reduced model effectiveness. However, there is still a significant gap in understanding how these strategies influence the efficiency and effectiveness of language models for code. Here, we empirically investigate the impact of three well-known compression strategies -- knowledge distillation, quantization, and pruning -- across three different classes of software engineering tasks: vulnerability detection, code summarization, and code search. Our findings reveal that the impact of these strategies varies greatly depending on the task and the specific compression method employed. Practitioners and researchers can use these insights to make informed decisions when selecting the most appropriate compression strategy, balancing both efficiency and effectiveness based on their specific needs.
AI-driven Java Performance Testing: Balancing Result Quality with Testing Time
Aug 09, 2024Performance testing aims at uncovering efficiency issues of software systems. In order to be both effective and practical, the design of a performance test must achieve a reasonable trade-off between result quality and testing time. This becomes particularly challenging in Java context, where the software undergoes a warm-up phase of execution, due to just-in-time compilation. During this phase, performance measurements are subject to severe fluctuations, which may adversely affect quality of performance test results. However, these approaches often provide suboptimal estimates of the warm-up phase, resulting in either insufficient or excessive warm-up iterations, which may degrade result quality or increase testing time. There is still a lack of consensus on how to properly address this problem. Here, we propose and study an AI-based framework to dynamically halt warm-up iterations at runtime. Specifically, our framework leverages recent advances in AI for Time Series Classification (TSC) to predict the end of the warm-up phase during test execution. We conduct experiments by training three different TSC models on half a million of measurement segments obtained from JMH microbenchmark executions. We find that our framework significantly improves the accuracy of the warm-up estimates provided by state-of-practice and state-of-the-art methods. This higher estimation accuracy results in a net improvement in either result quality or testing time for up to +35.3% of the microbenchmarks. Our study highlights that integrating AI to dynamically estimate the end of the warm-up phase can enhance the cost-effectiveness of Java performance testing.
DeLag: Detecting Latency Degradation Patterns in Service-based Systems
Oct 21, 2021

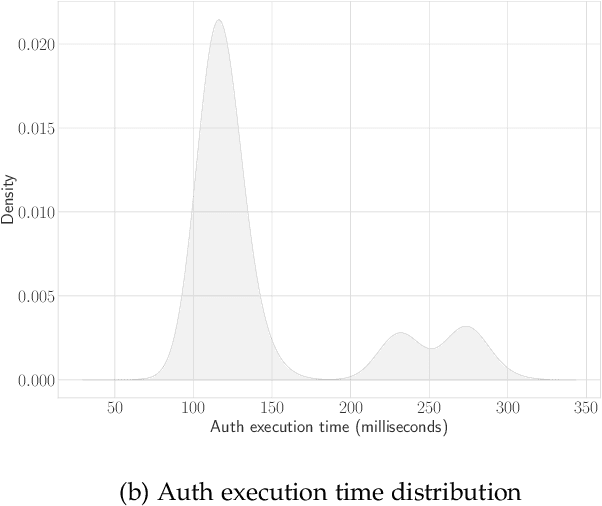

Performance debugging in production is a fundamental activity in modern service-based systems. The diagnosis of performance issues is often time-consuming, since it requires thorough inspection of large volumes of traces and performance indices. In this paper we present DeLag, a novel automated search-based approach for diagnosing performance issues in service-based systems. DeLag identifies subsets of requests that show, in the combination of their Remote Procedure Call execution times, symptoms of potentially relevant performance issues. We call such symptoms Latency Degradation Patterns. DeLag simultaneously search for multiple latency degradation patterns while optimizing precision, recall and latency dissimilarity. Experimentation on 700 datasets of requests generated from two microservice-based systems shows that our approach provide better and more stable effectiveness than three state-of-the-art approaches and general purpose machine learning clustering algorithms. Moreover, DeLag outperforms in terms of efficiency the second and the third most effective baseline techniques on the largest datasets used in our evaluation.