 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Boosting-based Autoencoder Ensembles for Outlier Detection
Oct 22, 2019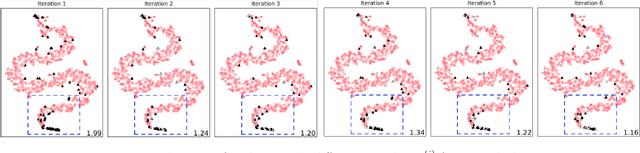


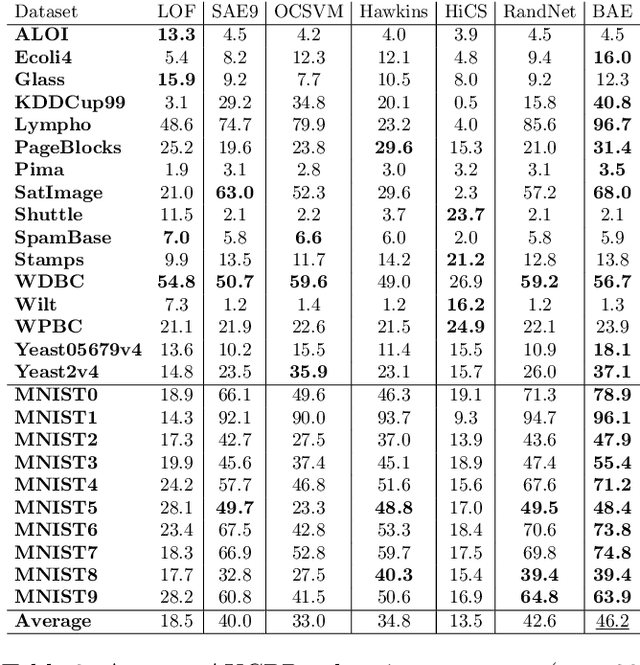
Autoencoders, as a dimensionality reduction technique, have been recently applied to outlier detection. However, neural networks are known to be vulnerable to overfitting, and therefore have limited potential in the unsupervised outlier detection setting. Current approaches to ensemble-based autoencoders do not generate a sufficient level of diversity to avoid the overfitting issue. To overcome the aforementioned limitations we develop a Boosting-based Autoencoder Ensemble approach (in short, BAE). BAE is an unsupervised ensemble method that, similarly to the boosting approach, builds an adaptive cascade of autoencoders to achieve improved and robust results. BAE trains the autoencoder components sequentially by performing a weighted sampling of the data, aimed at reducing the amount of outliers used during training, and at injecting diversity in the ensemble. We perform extensive experiments and show that the proposed methodology outperforms state-of-the-art approaches under a variety of conditions.
Graph-based Selective Outlier Ensembles
Apr 17, 2018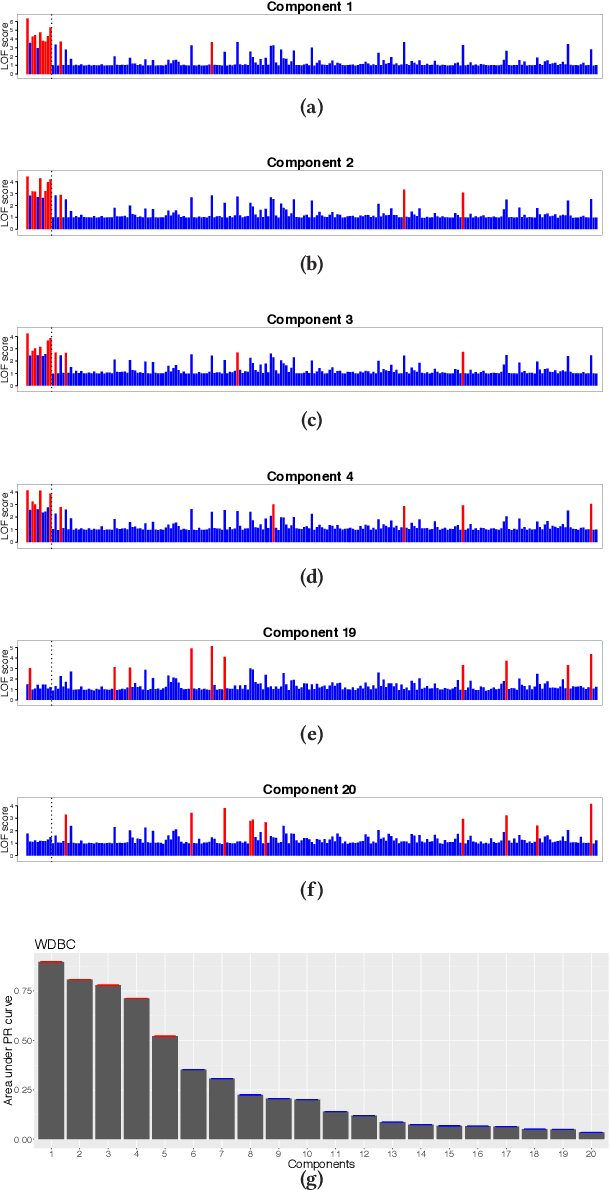

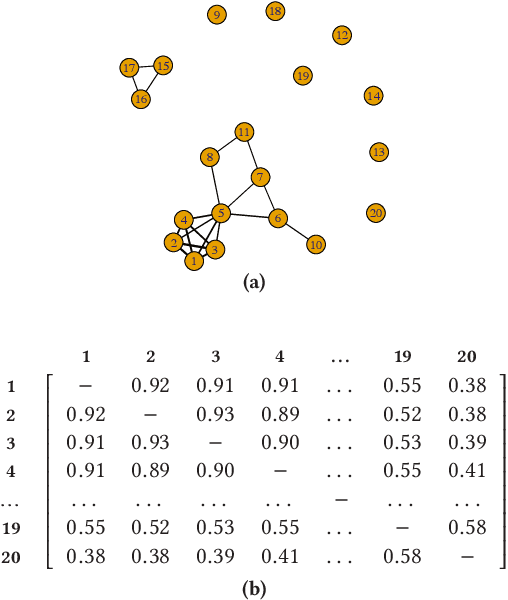
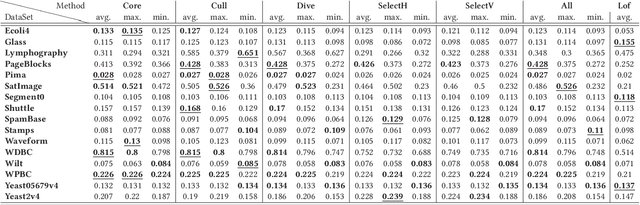
An ensemble technique is characterized by the mechanism that generates the components and by the mechanism that combines them. A common way to achieve the consensus is to enable each component to equally participate in the aggregation process. A problem with this approach is that poor components are likely to negatively affect the quality of the consensus result. To address this issue, alternatives have been explored in the literature to build selective classifier and cluster ensembles, where only a subset of the components contributes to the computation of the consensus. Of the family of ensemble methods, outlier ensembles are the least studied. Only recently, the selection problem for outlier ensembles has been discussed. In this work we define a new graph-based class of ranking selection methods. A method in this class is characterized by two main steps: (1) Mapping the rankings onto a graph structure; and (2) Mining the resulting graph to identify a subset of rankings. We define a specific instance of the graph-based ranking selection class. Specifically, we map the problem of selecting ensemble components onto a mining problem in a graph. An extensive evaluation was conducted on a variety of heterogeneous data and methods. Our empirical results show that our approach outperforms state-of-the-art selective outlier ensemble techniques.