 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkshop Scientific HPC in the pre-Exascale era (part of ITADATA 2024) Proceedings
Mar 26, 2025The proceedings of Workshop Scientific HPC in the pre-Exascale era (SHPC), held in Pisa, Italy, September 18, 2024, are part of 3rd Italian Conference on Big Data and Data Science (ITADATA2024) proceedings (arXiv: 2503.14937). The main objective of SHPC workshop was to discuss how the current most critical questions in HPC emerge in astrophysics, cosmology, and other scientific contexts and experiments. In particular, SHPC workshop focused on: $\bullet$ Scientific (mainly in astrophysical and medical fields) applications toward (pre-)Exascale computing $\bullet$ Performance portability $\bullet$ Green computing $\bullet$ Machine learning $\bullet$ Big Data management $\bullet$ Programming on heterogeneous architectures $\bullet$ Programming on accelerators $\bullet$ I/O techniques
Proceedings of the 3rd Italian Conference on Big Data and Data Science (ITADATA2024)
Mar 19, 2025Proceedings of the 3rd Italian Conference on Big Data and Data Science (ITADATA2024), held in Pisa, Italy, September 17-19, 2024. The Italian Conference on Big Data and Data Science (ITADATA2024) is the annual event supported by the CINI Big Data National Laboratory and ISTI CNR that aims to put together Italian researchers and professionals from academia, industry, government, and public administration working in the field of big data and data science, as well as related fields (e.g., security and privacy, HPC, Cloud). ITADATA2024 covered research on all theoretical and practical aspects of Big Data and data science including data governance, data processing, data analysis, data reporting, data protection, as well as experimental studies and lessons learned. In particular, ITADATA2024 focused on - Data spaces - Data processing life cycle - Machine learning and Large Language Models - Applications of big data and data science in healthcare, finance, industry 5.0, and beyond - Data science for social network analysis
Managing ML-Based Application Non-Functional Behavior: A Multi-Model Approach
Nov 21, 2023

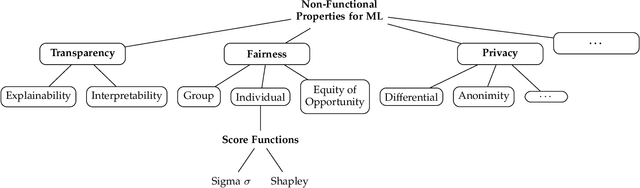
Modern applications are increasingly driven by Machine Learning (ML) models whose non-deterministic behavior is affecting the entire application life cycle from design to operation. The pervasive adoption of ML is urgently calling for approaches that guarantee a stable non-functional behavior of ML-based applications over time and across model changes. To this aim, non-functional properties of ML models, such as privacy, confidentiality, fairness, and explainability, must be monitored, verified, and maintained. This need is even more pressing when modern applications operate in the edge-cloud continuum, increasing their complexity and dynamicity. Existing approaches mostly focus on i) implementing classifier selection solutions according to the functional behavior of ML models, ii) finding new algorithmic solutions to this need, such as continuous re-training. In this paper, we propose a multi-model approach built on dynamic classifier selection, where multiple ML models showing similar non-functional properties are made available to the application and one model is selected over time according to (dynamic and unpredictable) contextual changes. Our solution goes beyond the state of the art by providing an architectural and methodological approach that continuously guarantees a stable non-functional behavior of ML-based applications, is applicable to different ML models, and is driven by non-functional properties assessed on the models themselves. It consists of a two-step process working during application operation, where model assessment verifies non-functional properties of ML models trained and selected at development time, and model substitution guarantees a continuous and stable support of non-functional properties. We experimentally evaluate our solution in a real-world scenario focusing on non-functional property fairness.
Towards Certification of Machine Learning-Based Distributed Systems
Jun 01, 2023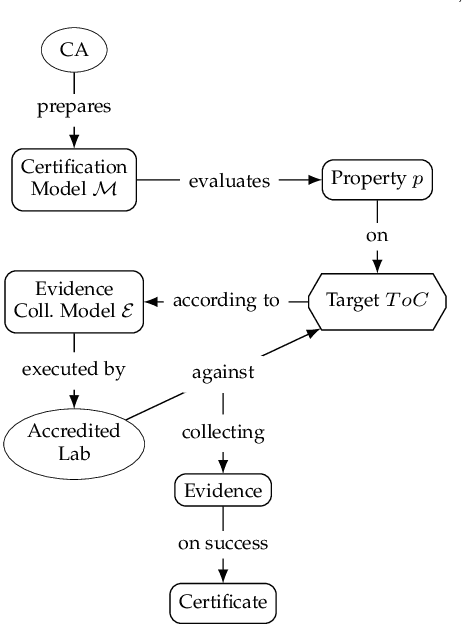
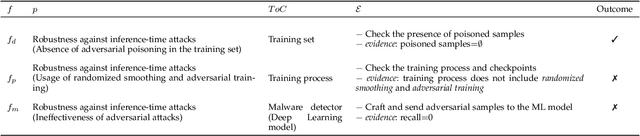
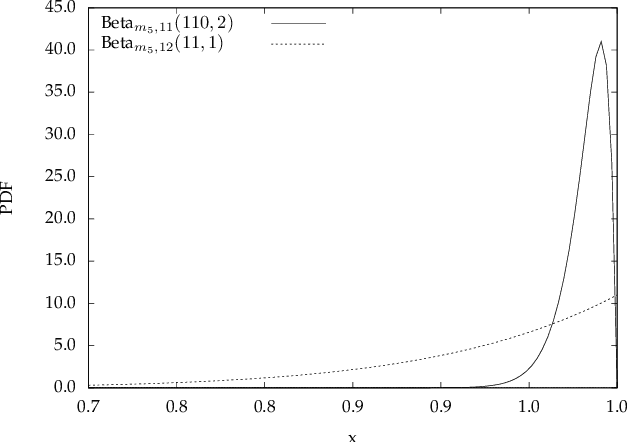
Machine Learning (ML) is increasingly used to drive the operation of complex distributed systems deployed on the cloud-edge continuum enabled by 5G. Correspondingly, distributed systems' behavior is becoming more non-deterministic in nature. This evolution of distributed systems requires the definition of new assurance approaches for the verification of non-functional properties. Certification, the most popular assurance technique for system and software verification, is not immediately applicable to systems whose behavior is determined by Machine Learning-based inference. However, there is an increasing push from policy makers, regulators, and industrial stakeholders towards the definition of techniques for the certification of non-functional properties (e.g., fairness, robustness, privacy) of ML. This article analyzes the challenges and deficiencies of current certification schemes, discusses open research issues and proposes a first certification scheme for ML-based distributed systems.
Explainable Data Poison Attacks on Human Emotion Evaluation Systems based on EEG Signals
Jan 17, 2023



The major aim of this paper is to explain the data poisoning attacks using label-flipping during the training stage of the electroencephalogram (EEG) signal-based human emotion evaluation systems deploying Machine Learning models from the attackers' perspective. Human emotion evaluation using EEG signals has consistently attracted a lot of research attention. The identification of human emotional states based on EEG signals is effective to detect potential internal threats caused by insider individuals. Nevertheless, EEG signal-based human emotion evaluation systems have shown several vulnerabilities to data poison attacks. The findings of the experiments demonstrate that the suggested data poison assaults are model-independently successful, although various models exhibit varying levels of resilience to the attacks. In addition, the data poison attacks on the EEG signal-based human emotion evaluation systems are explained with several Explainable Artificial Intelligence (XAI) methods, including Shapley Additive Explanation (SHAP) values, Local Interpretable Model-agnostic Explanations (LIME), and Generated Decision Trees. And the codes of this paper are publicly available on GitHub.
On the Robustness of Ensemble-Based Machine Learning Against Data Poisoning
Sep 28, 2022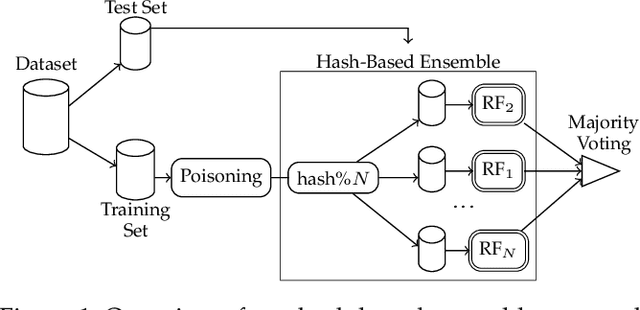


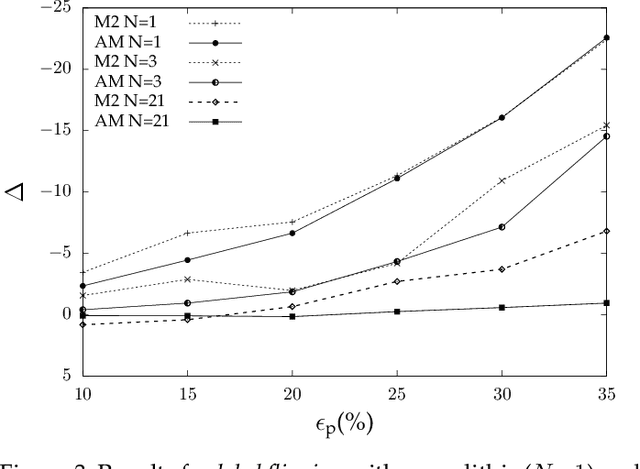
Machine learning is becoming ubiquitous. From financial to medicine, machine learning models are boosting decision-making processes and even outperforming humans in some tasks. This huge progress in terms of prediction quality does not however find a counterpart in the security of such models and corresponding predictions, where perturbations of fractions of the training set (poisoning) can seriously undermine the model accuracy. Research on poisoning attacks and defenses even predates the introduction of deep neural networks, leading to several promising solutions. Among them, ensemble-based defenses, where different models are trained on portions of the training set and their predictions are then aggregated, are getting significant attention, due to their relative simplicity and theoretical and practical guarantees. The work in this paper designs and implements a hash-based ensemble approach for ML robustness and evaluates its applicability and performance on random forests, a machine learning model proved to be more resistant to poisoning attempts on tabular datasets. An extensive experimental evaluation is carried out to evaluate the robustness of our approach against a variety of attacks, and compare it with a traditional monolithic model based on random forests.