 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIML-ViT: Benchmarking Image Manipulation Localization by Vision Transformer
Aug 07, 2023



Advanced image tampering techniques are increasingly challenging the trustworthiness of multimedia, leading to the development of Image Manipulation Localization (IML). But what makes a good IML model? The answer lies in the way to capture artifacts. Exploiting artifacts requires the model to extract non-semantic discrepancies between manipulated and authentic regions, necessitating explicit comparisons between the two areas. With the self-attention mechanism, naturally, the Transformer should be a better candidate to capture artifacts. However, due to limited datasets, there is currently no pure ViT-based approach for IML to serve as a benchmark, and CNNs dominate the entire task. Nevertheless, CNNs suffer from weak long-range and non-semantic modeling. To bridge this gap, based on the fact that artifacts are sensitive to image resolution, amplified under multi-scale features, and massive at the manipulation border, we formulate the answer to the former question as building a ViT with high-resolution capacity, multi-scale feature extraction capability, and manipulation edge supervision that could converge with a small amount of data. We term this simple but effective ViT paradigm IML-ViT, which has significant potential to become a new benchmark for IML. Extensive experiments on five benchmark datasets verified our model outperforms the state-of-the-art manipulation localization methods.Code and models are available at \url{https://github.com/SunnyHaze/IML-ViT}.
Explainable Label-flipping Attacks on Human Emotion Assessment System
Feb 08, 2023This paper's main goal is to provide an attacker's point of view on data poisoning assaults that use label-flipping during the training phase of systems that use electroencephalogram (EEG) signals to evaluate human emotion. To attack different machine learning classifiers such as Adaptive Boosting (AdaBoost) and Random Forest dedicated to the classification of 4 different human emotions using EEG signals, this paper proposes two scenarios of label-flipping methods. The results of the studies show that the proposed data poison attacksm based on label-flipping are successful regardless of the model, but different models show different degrees of resistance to the assaults. In addition, numerous Explainable Artificial Intelligence (XAI) techniques are used to explain the data poison attacks on EEG signal-based human emotion evaluation systems.
Data Poisoning Attacks on EEG Signal-based Risk Assessment Systems
Feb 08, 2023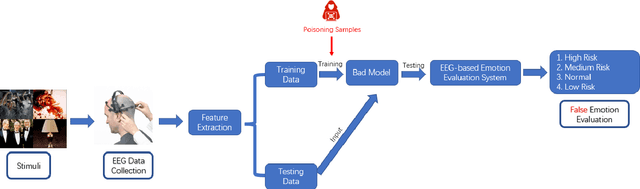
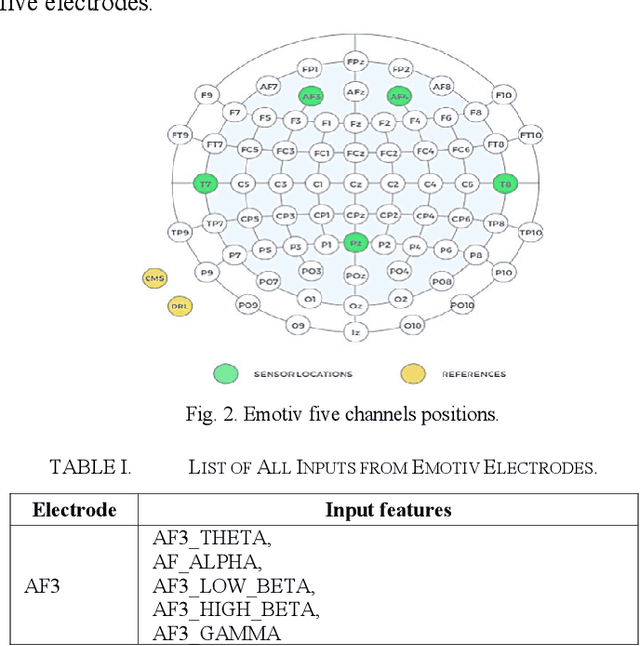
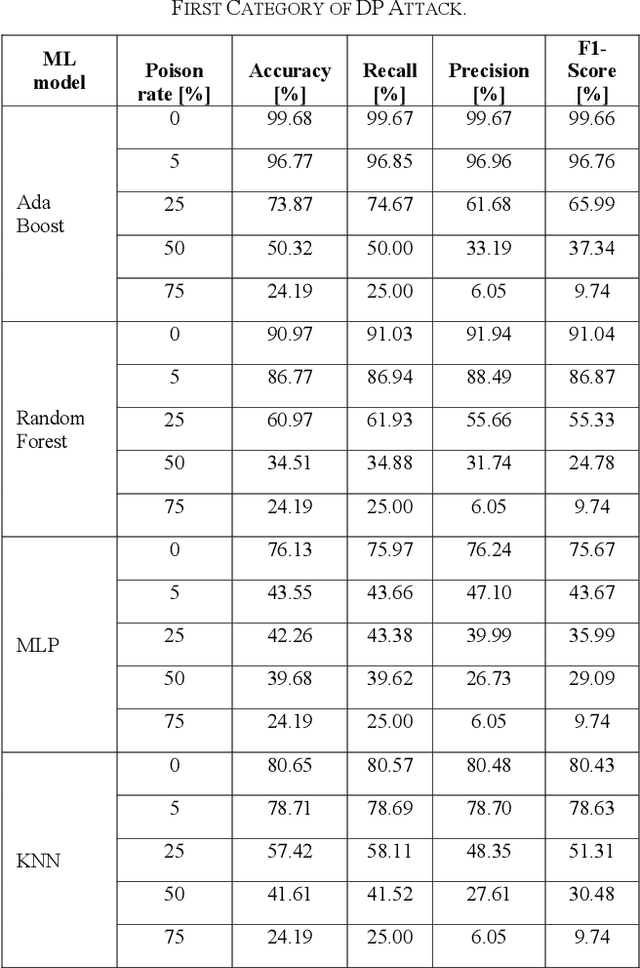
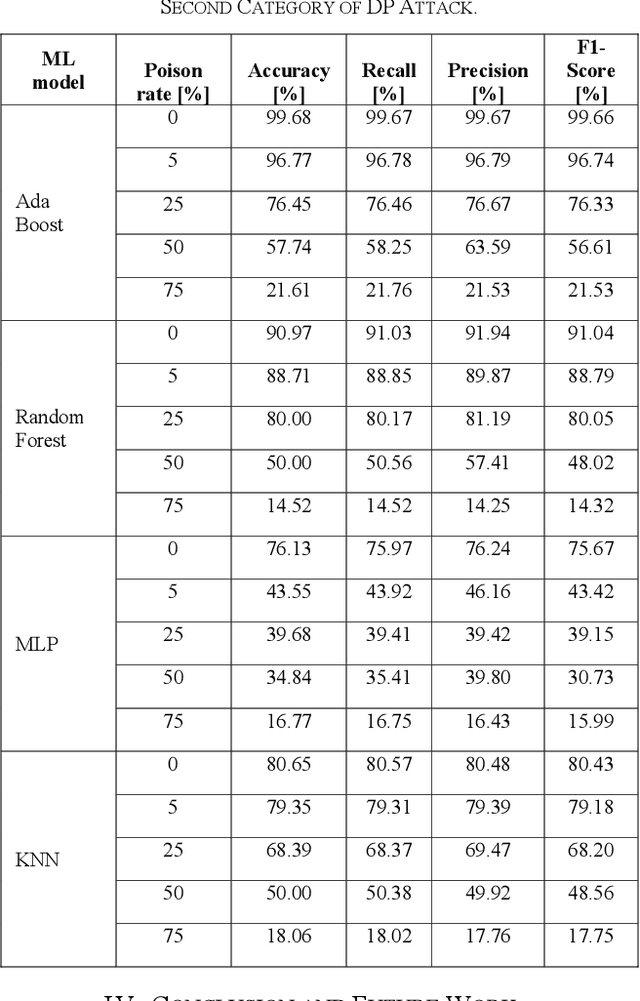
Industrial insider risk assessment using electroencephalogram (EEG) signals has consistently attracted a lot of research attention. However, EEG signal-based risk assessment systems, which could evaluate the emotional states of humans, have shown several vulnerabilities to data poison attacks. In this paper, from the attackers' perspective, data poison attacks involving label-flipping occurring in the training stages of different machine learning models intrude on the EEG signal-based risk assessment systems using these machine learning models. This paper aims to propose two categories of label-flipping methods to attack different machine learning classifiers including Adaptive Boosting (AdaBoost), Multilayer Perceptron (MLP), Random Forest, and K-Nearest Neighbors (KNN) dedicated to the classification of 4 different human emotions using EEG signals. This aims to degrade the performance of the aforementioned machine learning models concerning the classification task. The experimental results show that the proposed data poison attacks are model-agnostically effective whereas different models have different resilience to the data poison attacks.
Explainable Data Poison Attacks on Human Emotion Evaluation Systems based on EEG Signals
Jan 17, 2023



The major aim of this paper is to explain the data poisoning attacks using label-flipping during the training stage of the electroencephalogram (EEG) signal-based human emotion evaluation systems deploying Machine Learning models from the attackers' perspective. Human emotion evaluation using EEG signals has consistently attracted a lot of research attention. The identification of human emotional states based on EEG signals is effective to detect potential internal threats caused by insider individuals. Nevertheless, EEG signal-based human emotion evaluation systems have shown several vulnerabilities to data poison attacks. The findings of the experiments demonstrate that the suggested data poison assaults are model-independently successful, although various models exhibit varying levels of resilience to the attacks. In addition, the data poison attacks on the EEG signal-based human emotion evaluation systems are explained with several Explainable Artificial Intelligence (XAI) methods, including Shapley Additive Explanation (SHAP) values, Local Interpretable Model-agnostic Explanations (LIME), and Generated Decision Trees. And the codes of this paper are publicly available on GitHub.