 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
May 18, 2026Recent video generative models have greatly improved the realism of AI-generated videos, yet their outputs still exhibit artifacts such as temporal inconsistencies, structural distortions, and semantic incoherence. While Multimodal Large Language Models (MLLMs) show strong visual understanding capabilities, their ability to perceive and reason about such artifacts remains unclear. Existing benchmarks often lack systematic evaluation of artifact-aware perception and fine-grained diagnostic reasoning, especially across diverse AI-generated video domains beyond photorealistic content. To address this gap, we introduce Artifact-Bench, a comprehensive benchmark for evaluating MLLMs on AI-generated video artifact detection and analysis. We first establish a three-level hierarchical taxonomy of realism artifacts, covering photorealistic, animated, and CG-style videos. Based on this taxonomy, Artifact-Bench defines three complementary tasks: real vs. AI-generated video classification, pairwise realism comparison, and fine-grained artifact identification. Experiments on 19 leading MLLMs reveal substantial limitations in artifact perception and reasoning, with many models approaching random or even below-random performance in challenging settings. We further observe significant misalignment between MLLM judgments and human perceptual preferences, highlighting their limited reliability as general evaluators for AI-generated video realism.
Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
Apr 09, 2026The advent of agentic multimodal models has empowered systems to actively interact with external environments. However, current agents suffer from a profound meta-cognitive deficit: they struggle to arbitrate between leveraging internal knowledge and querying external utilities. Consequently, they frequently fall prey to blind tool invocation, resorting to reflexive tool execution even when queries are resolvable from the raw visual context. This pathological behavior precipitates severe latency bottlenecks and injects extraneous noise that derails sound reasoning. Existing reinforcement learning protocols attempt to mitigate this via a scalarized reward that penalizes tool usage. Yet, this coupled formulation creates an irreconcilable optimization dilemma: an aggressive penalty suppresses essential tool use, whereas a mild penalty is entirely subsumed by the variance of the accuracy reward during advantage normalization, rendering it impotent against tool overuse. To transcend this bottleneck, we propose HDPO, a framework that reframes tool efficiency from a competing scalar objective to a strictly conditional one. By eschewing reward scalarization, HDPO maintains two orthogonal optimization channels: an accuracy channel that maximizes task correctness, and an efficiency channel that enforces execution economy exclusively within accurate trajectories via conditional advantage estimation. This decoupled architecture naturally induces a cognitive curriculum-compelling the agent to first master task resolution before refining its self-reliance. Extensive evaluations demonstrate that our resulting model, Metis, reduces tool invocations by orders of magnitude while simultaneously elevating reasoning accuracy.
MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Mar 12, 2026Multimodal Large Language Models (MLLMs) are increasingly used to carry out visual workflows such as navigating GUIs, where the next step depends on verified visual compositional conditions (e.g., "if a permission dialog appears and the color of the interface is green, click Allow") and the process may branch or terminate early. Yet this capability remains under-evaluated: existing benchmarks focus on shallow-compositions or independent-constraints rather than deeply chained compositional conditionals. In this paper, we introduce MM-CondChain, a benchmark for visually grounded deep compositional reasoning. Each benchmark instance is organized as a multi-layer reasoning chain, where every layer contains a non-trivial compositional condition grounded in visual evidence and built from multiple objects, attributes, or relations. To answer correctly, an MLLM must perceive the image in detail, reason over multiple visual elements at each step, and follow the resulting execution path to the final outcome. To scalably construct such workflow-style data, we propose an agentic synthesis pipeline: a Planner orchestrates layer-by-layer generation of compositional conditions, while a Verifiable Programmatic Intermediate Representation (VPIR) ensures each layer's condition is mechanically verifiable. A Composer then assembles these verified layers into complete instructions. Using this pipeline, we construct benchmarks across three visual domains: natural images, data charts, and GUI trajectories. Experiments on a range of MLLMs show that even the strongest model attains only 53.33 Path F1, with sharp drops on hard negatives and as depth or predicate complexity grows, confirming that deep compositional reasoning remains a fundamental challenge.
Phase-Interface Instance Segmentation as a Visual Sensor for Laboratory Process Monitoring
Mar 11, 2026Reliable visual monitoring of chemical experiments remains challenging in transparent glassware, where weak phase boundaries and optical artifacts degrade conventional segmentation. We formulate laboratory phenomena as the time evolution of phase interfaces and introduce the Chemical Transparent Glasses dataset 2.0 (CTG 2.0), a vessel-aware benchmark with 3,668 images, 23 glassware categories, and five multiphase interface types for phase-interface instance segmentation. Building on YOLO11m-seg, we propose LGA-RCM-YOLO, which combines Local-Global Attention (LGA) for robust semantic representation and a Rectangular Self-Calibration Module (RCM) for boundary refinement of thin, elongated interfaces. On CTG 2.0, the proposed model achieves 84.4% AP@0.5 and 58.43% AP@0.5-0.95, improving over the YOLO11m baseline by 6.42 and 8.75 AP points, respectively, while maintaining near real-time inference (13.67 FPS, RTX 3060). An auxiliary color-attribute head further labels liquid instances as colored or colorless with 98.71% precision and 98.32% recall. Finally, we demonstrate continuous process monitoring in separatory-funnel phase separation and crystallization, showing that phase-interface instance segmentation can serve as a practical visual sensor for laboratory automation.
Beyond Scattered Acceptance: Fast and Coherent Inference for DLMs via Longest Stable Prefixes
Mar 05, 2026Diffusion Language Models (DLMs) promise highly parallel text generation, yet their practical inference speed is often bottlenecked by suboptimal decoding schedulers. Standard approaches rely on 'scattered acceptance'-committing high confidence tokens at disjoint positions throughout the sequence. This approach inadvertently fractures the Key-Value (KV) cache, destroys memory locality, and forces the model into costly, repeated repairs across unstable token boundaries. To resolve this, we present the Longest Stable Prefix (LSP) scheduler, a training-free and model-agnostic inference paradigm based on monolithic prefix absorption. In each denoising step, LSP evaluates token stability via a single forward pass, dynamically identifies a contiguous left-aligned block of stable predictions, and snaps its boundary to natural linguistic or structural delimiters before an atomic commitment. This prefix-first topology yields dual benefits: systemically, it converts fragmented KV cache updates into efficient, contiguous appends; algorithmically, it preserves bidirectional lookahead over a geometrically shrinking active suffix, drastically reducing token flip rates and denoiser calls. Extensive evaluations on LLaDA-8B and Dream-7B demonstrate that LSP accelerates inference by up to 3.4x across rigorous benchmarks including mathematical reasoning, code generation, multilingual (CJK) tasks, and creative writing while matching or slightly improving output quality. By fundamentally restructuring the commitment topology, LSP bridges the gap between the theoretical parallelism of DLMs and practical hardware efficiency.
SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs
Feb 05, 2026Multimodal Large Language Models (MLLMs) have made remarkable progress in multimodal perception and reasoning by bridging vision and language. However, most existing MLLMs perform reasoning primarily with textual CoT, which limits their effectiveness on vision-intensive tasks. Recent approaches inject a fixed number of continuous hidden states as "visual thoughts" into the reasoning process and improve visual performance, but often at the cost of degraded text-based logical reasoning. We argue that the core limitation lies in a rigid, pre-defined reasoning pattern that cannot adaptively choose the most suitable thinking modality for different user queries. We introduce SwimBird, a reasoning-switchable MLLM that dynamically switches among three reasoning modes conditioned on the input: (1) text-only reasoning, (2) vision-only reasoning (continuous hidden states as visual thoughts), and (3) interleaved vision-text reasoning. To enable this capability, we adopt a hybrid autoregressive formulation that unifies next-token prediction for textual thoughts with next-embedding prediction for visual thoughts, and design a systematic reasoning-mode curation strategy to construct SwimBird-SFT-92K, a diverse supervised fine-tuning dataset covering all three reasoning patterns. By enabling flexible, query-adaptive mode selection, SwimBird preserves strong textual logic while substantially improving performance on vision-dense tasks. Experiments across diverse benchmarks covering textual reasoning and challenging visual understanding demonstrate that SwimBird achieves state-of-the-art results and robust gains over prior fixed-pattern multimodal reasoning methods.
AdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
Jarvis: Towards Personalized AI Assistant via Personal KV-Cache Retrieval
Oct 26, 2025
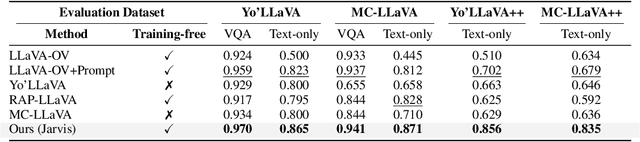
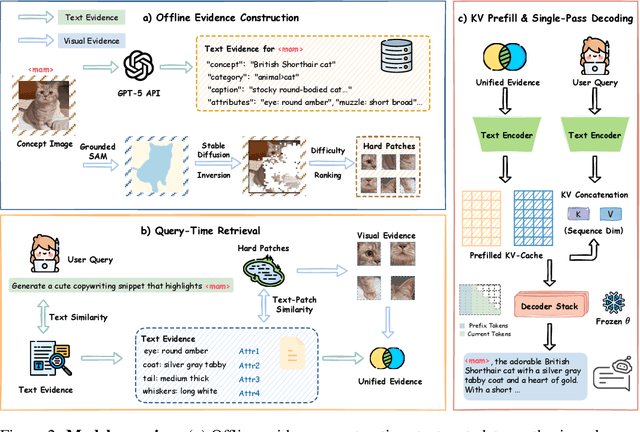
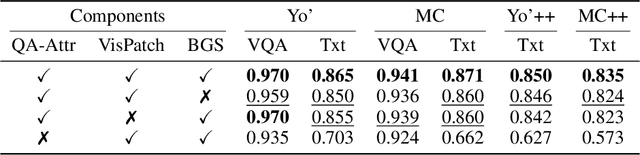
The rapid development of Vision-language models (VLMs) enables open-ended perception and reasoning. Recent works have started to investigate how to adapt general-purpose VLMs into personalized assistants. Even commercial models such as ChatGPT now support model personalization by incorporating user-specific information. However, existing methods either learn a set of concept tokens or train a VLM to utilize user-specific information. However, both pipelines struggle to generate accurate answers as personalized assistants. We introduce Jarvis, an innovative framework for a personalized AI assistant through personal KV-Cache retrieval, which stores user-specific information in the KV-Caches of both textual and visual tokens. The textual tokens are created by summarizing user information into metadata, while the visual tokens are produced by extracting distinct image patches from the user's images. When answering a question, Jarvis first retrieves related KV-Caches from personal storage and uses them to ensure accuracy in responses. We also introduce a fine-grained benchmark built with the same distinct image patch mining pipeline, emphasizing accurate question answering based on fine-grained user-specific information. Jarvis is capable of providing more accurate responses, particularly when they depend on specific local details. Jarvis achieves state-of-the-art results in both visual question answering and text-only tasks across multiple datasets, indicating a practical path toward personalized AI assistants. The code and dataset will be released.
Diffusion Language Models Know the Answer Before Decoding
Aug 27, 2025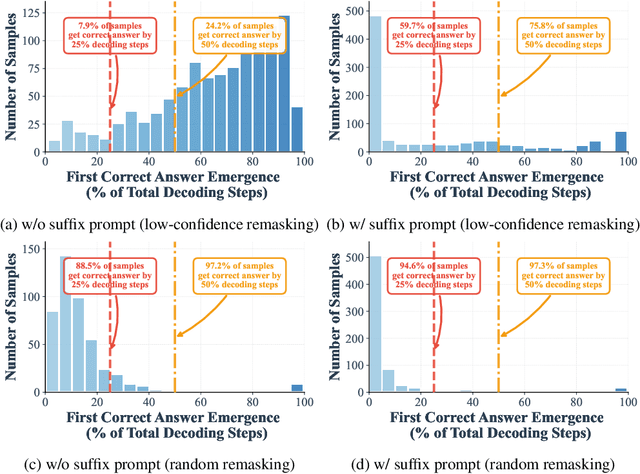
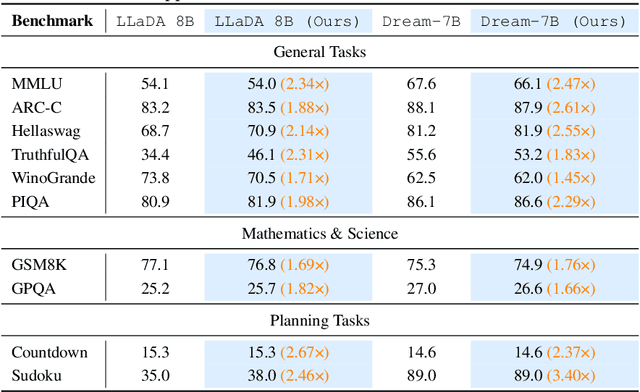
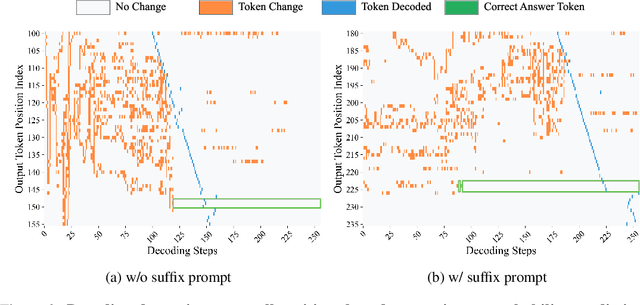
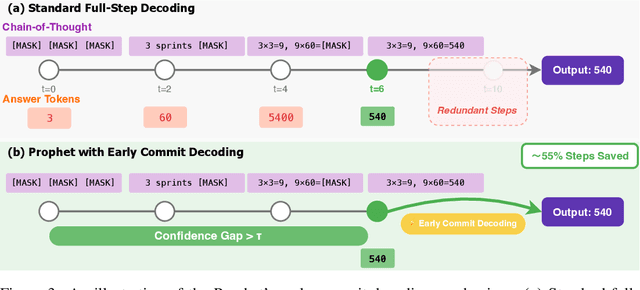
Diffusion language models (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high quality outputs. In this work, we highlight and leverage an overlooked property of DLMs early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random remasking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go "all-in" (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4x while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is publicly available at https://github.com/pixeli99/Prophet.
MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
Jun 05, 2025Chain-of-Thought (CoT) has widely enhanced mathematical reasoning in Large Language Models (LLMs), but it still remains challenging for extending it to multimodal domains. Existing works either adopt a similar textual reasoning for image input, or seek to interleave visual signals into mathematical CoT. However, they face three key limitations for math problem-solving: reliance on coarse-grained box-shaped image regions, limited perception of vision encoders on math content, and dependence on external capabilities for visual modification. In this paper, we propose MINT-CoT, introducing Mathematical INterleaved Tokens for Chain-of-Thought visual reasoning. MINT-CoT adaptively interleaves relevant visual tokens into textual reasoning steps via an Interleave Token, which dynamically selects visual regions of any shapes within math figures. To empower this capability, we construct the MINT-CoT dataset, containing 54K mathematical problems aligning each reasoning step with visual regions at the token level, accompanied by a rigorous data generation pipeline. We further present a three-stage MINT-CoT training strategy, progressively combining text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL, which derives our MINT-CoT-7B model. Extensive experiments demonstrate the effectiveness of our method for effective visual interleaved reasoning in mathematical domains, where MINT-CoT-7B outperforms the baseline model by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar, respectively. Our code and data are available at https://github.com/xinyan-cxy/MINT-CoT