 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Nov 15, 2025Multimodal Large Language Models (MLLMs) have unlocked powerful cross-modal capabilities, but still significantly suffer from hallucinations. As such, accurate detection of hallucinations in MLLMs is imperative for ensuring their reliability in practical applications. To this end, guided by the principle of "Seeing is Believing", we introduce VBackChecker, a novel reference-free hallucination detection framework that verifies the consistency of MLLMgenerated responses with visual inputs, by leveraging a pixellevel Grounding LLM equipped with reasoning and referring segmentation capabilities. This reference-free framework not only effectively handles rich-context scenarios, but also offers interpretability. To facilitate this, an innovative pipeline is accordingly designed for generating instruction-tuning data (R-Instruct), featuring rich-context descriptions, grounding masks, and hard negative samples. We further establish R^2 -HalBench, a new hallucination benchmark for MLLMs, which, unlike previous benchmarks, encompasses real-world, rich-context descriptions from 18 MLLMs with high-quality annotations, spanning diverse object-, attribute, and relationship-level details. VBackChecker outperforms prior complex frameworks and achieves state-of-the-art performance on R^2 -HalBench, even rivaling GPT-4o's capabilities in hallucination detection. It also surpasses prior methods in the pixel-level grounding task, achieving over a 10% improvement. All codes, data, and models are available at https://github.com/PinxueGuo/VBackChecker.
LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
Jun 17, 2025Multimodal Large Language Models (MLLMs) have shown great promise but require substantial computational resources during inference. Attackers can exploit this by inducing excessive output, leading to resource exhaustion and service degradation. Prior energy-latency attacks aim to increase generation time by broadly shifting the output token distribution away from the EOS token, but they neglect the influence of token-level Part-of-Speech (POS) characteristics on EOS and sentence-level structural patterns on output counts, limiting their efficacy. To address this, we propose LingoLoop, an attack designed to induce MLLMs to generate excessively verbose and repetitive sequences. First, we find that the POS tag of a token strongly affects the likelihood of generating an EOS token. Based on this insight, we propose a POS-Aware Delay Mechanism to postpone EOS token generation by adjusting attention weights guided by POS information. Second, we identify that constraining output diversity to induce repetitive loops is effective for sustained generation. We introduce a Generative Path Pruning Mechanism that limits the magnitude of hidden states, encouraging the model to produce persistent loops. Extensive experiments demonstrate LingoLoop can increase generated tokens by up to 30 times and energy consumption by a comparable factor on models like Qwen2.5-VL-3B, consistently driving MLLMs towards their maximum generation limits. These findings expose significant MLLMs' vulnerabilities, posing challenges for their reliable deployment. The code will be released publicly following the paper's acceptance.
VideoPure: Diffusion-based Adversarial Purification for Video Recognition
Jan 25, 2025



Recent work indicates that video recognition models are vulnerable to adversarial examples, posing a serious security risk to downstream applications. However, current research has primarily focused on adversarial attacks, with limited work exploring defense mechanisms. Furthermore, due to the spatial-temporal complexity of videos, existing video defense methods face issues of high cost, overfitting, and limited defense performance. Recently, diffusion-based adversarial purification methods have achieved robust defense performance in the image domain. However, due to the additional temporal dimension in videos, directly applying these diffusion-based adversarial purification methods to the video domain suffers performance and efficiency degradation. To achieve an efficient and effective video adversarial defense method, we propose the first diffusion-based video purification framework to improve video recognition models' adversarial robustness: VideoPure. Given an adversarial example, we first employ temporal DDIM inversion to transform the input distribution into a temporally consistent and trajectory-defined distribution, covering adversarial noise while preserving more video structure. Then, during DDIM denoising, we leverage intermediate results at each denoising step and conduct guided spatial-temporal optimization, removing adversarial noise while maintaining temporal consistency. Finally, we input the list of optimized intermediate results into the video recognition model for multi-step voting to obtain the predicted class. We investigate the defense performance of our method against black-box, gray-box, and adaptive attacks on benchmark datasets and models. Compared with other adversarial purification methods, our method overall demonstrates better defense performance against different attacks. Our code is available at https://github.com/deep-kaixun/VideoPure.
DeTrack: In-model Latent Denoising Learning for Visual Object Tracking
Jan 05, 2025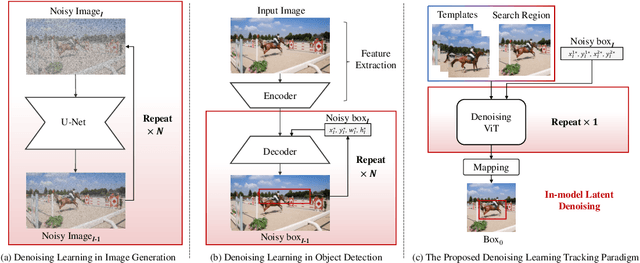

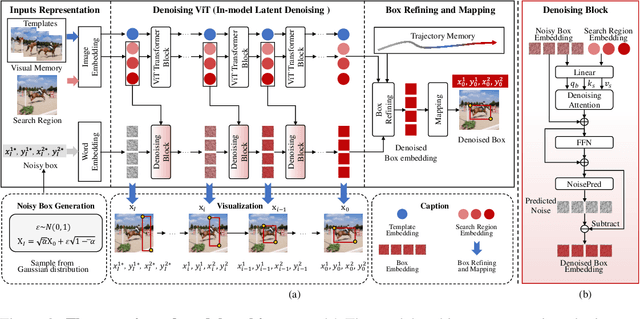
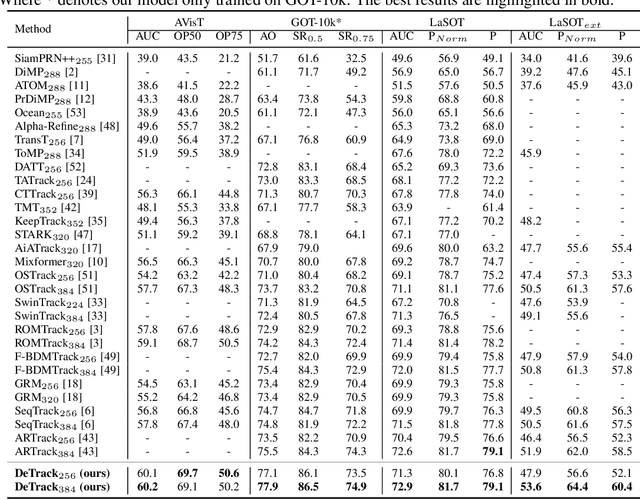
Previous visual object tracking methods employ image-feature regression models or coordinate autoregression models for bounding box prediction. Image-feature regression methods heavily depend on matching results and do not utilize positional prior, while the autoregressive approach can only be trained using bounding boxes available in the training set, potentially resulting in suboptimal performance during testing with unseen data. Inspired by the diffusion model, denoising learning enhances the model's robustness to unseen data. Therefore, We introduce noise to bounding boxes, generating noisy boxes for training, thus enhancing model robustness on testing data. We propose a new paradigm to formulate the visual object tracking problem as a denoising learning process. However, tracking algorithms are usually asked to run in real-time, directly applying the diffusion model to object tracking would severely impair tracking speed. Therefore, we decompose the denoising learning process into every denoising block within a model, not by running the model multiple times, and thus we summarize the proposed paradigm as an in-model latent denoising learning process. Specifically, we propose a denoising Vision Transformer (ViT), which is composed of multiple denoising blocks. In the denoising block, template and search embeddings are projected into every denoising block as conditions. A denoising block is responsible for removing the noise in a predicted bounding box, and multiple stacked denoising blocks cooperate to accomplish the whole denoising process. Subsequently, we utilize image features and trajectory information to refine the denoised bounding box. Besides, we also utilize trajectory memory and visual memory to improve tracking stability. Experimental results validate the effectiveness of our approach, achieving competitive performance on several challenging datasets.
X-Prompt: Multi-modal Visual Prompt for Video Object Segmentation
Sep 28, 2024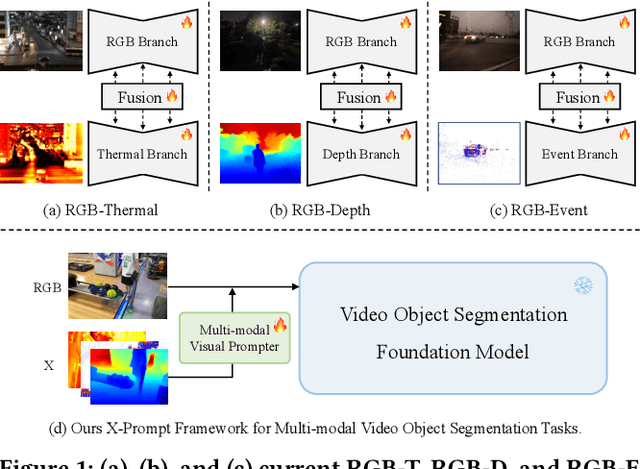
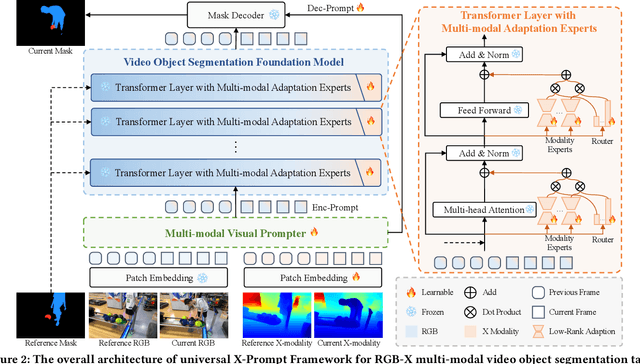
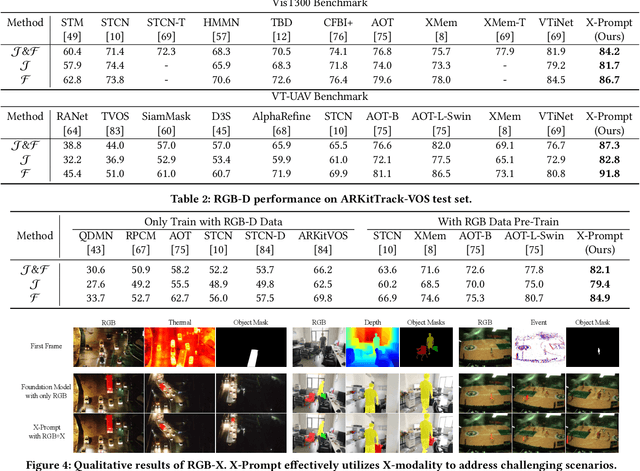
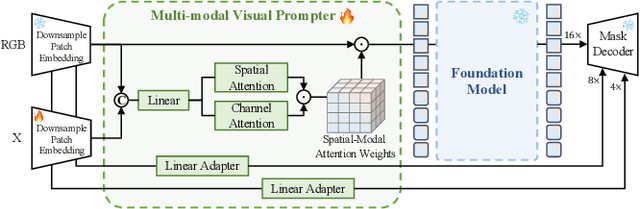
Multi-modal Video Object Segmentation (VOS), including RGB-Thermal, RGB-Depth, and RGB-Event, has garnered attention due to its capability to address challenging scenarios where traditional VOS methods struggle, such as extreme illumination, rapid motion, and background distraction. Existing approaches often involve designing specific additional branches and performing full-parameter fine-tuning for fusion in each task. However, this paradigm not only duplicates research efforts and hardware costs but also risks model collapse with the limited multi-modal annotated data. In this paper, we propose a universal framework named X-Prompt for all multi-modal video object segmentation tasks, designated as RGB+X. The X-Prompt framework first pre-trains a video object segmentation foundation model using RGB data, and then utilize the additional modality of the prompt to adapt it to downstream multi-modal tasks with limited data. Within the X-Prompt framework, we introduce the Multi-modal Visual Prompter (MVP), which allows prompting foundation model with the various modalities to segment objects precisely. We further propose the Multi-modal Adaptation Experts (MAEs) to adapt the foundation model with pluggable modality-specific knowledge without compromising the generalization capacity. To evaluate the effectiveness of the X-Prompt framework, we conduct extensive experiments on 3 tasks across 4 benchmarks. The proposed universal X-Prompt framework consistently outperforms the full fine-tuning paradigm and achieves state-of-the-art performance. Code: https://github.com/PinxueGuo/X-Prompt.git
General Compression Framework for Efficient Transformer Object Tracking
Sep 26, 2024



Transformer-based trackers have established a dominant role in the field of visual object tracking. While these trackers exhibit promising performance, their deployment on resource-constrained devices remains challenging due to inefficiencies. To improve the inference efficiency and reduce the computation cost, prior approaches have aimed to either design lightweight trackers or distill knowledge from larger teacher models into more compact student trackers. However, these solutions often sacrifice accuracy for speed. Thus, we propose a general model compression framework for efficient transformer object tracking, named CompressTracker, to reduce the size of a pre-trained tracking model into a lightweight tracker with minimal performance degradation. Our approach features a novel stage division strategy that segments the transformer layers of the teacher model into distinct stages, enabling the student model to emulate each corresponding teacher stage more effectively. Additionally, we also design a unique replacement training technique that involves randomly substituting specific stages in the student model with those from the teacher model, as opposed to training the student model in isolation. Replacement training enhances the student model's ability to replicate the teacher model's behavior. To further forcing student model to emulate teacher model, we incorporate prediction guidance and stage-wise feature mimicking to provide additional supervision during the teacher model's compression process. Our framework CompressTracker is structurally agnostic, making it compatible with any transformer architecture. We conduct a series of experiment to verify the effectiveness and generalizability of CompressTracker. Our CompressTracker-4 with 4 transformer layers, which is compressed from OSTrack, retains about 96% performance on LaSOT (66.1% AUC) while achieves 2.17x speed up.
TagOOD: A Novel Approach to Out-of-Distribution Detection via Vision-Language Representations and Class Center Learning
Aug 28, 2024
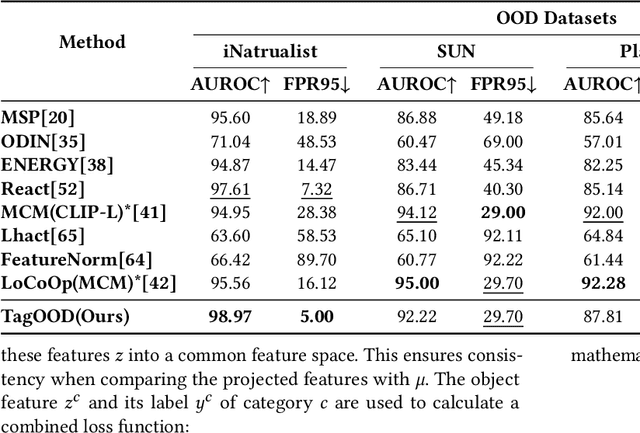
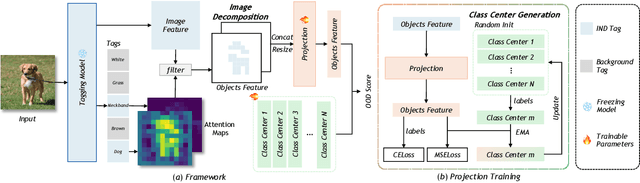

Multimodal fusion, leveraging data like vision and language, is rapidly gaining traction. This enriched data representation improves performance across various tasks. Existing methods for out-of-distribution (OOD) detection, a critical area where AI models encounter unseen data in real-world scenarios, rely heavily on whole-image features. These image-level features can include irrelevant information that hinders the detection of OOD samples, ultimately limiting overall performance. In this paper, we propose \textbf{TagOOD}, a novel approach for OOD detection that leverages vision-language representations to achieve label-free object feature decoupling from whole images. This decomposition enables a more focused analysis of object semantics, enhancing OOD detection performance. Subsequently, TagOOD trains a lightweight network on the extracted object features to learn representative class centers. These centers capture the central tendencies of IND object classes, minimizing the influence of irrelevant image features during OOD detection. Finally, our approach efficiently detects OOD samples by calculating distance-based metrics as OOD scores between learned centers and test samples. We conduct extensive experiments to evaluate TagOOD on several benchmark datasets and demonstrate its superior performance compared to existing OOD detection methods. This work presents a novel perspective for further exploration of multimodal information utilization in OOD detection, with potential applications across various tasks.
Hierarchical Visual Categories Modeling: A Joint Representation Learning and Density Estimation Framework for Out-of-Distribution Detection
Aug 28, 2024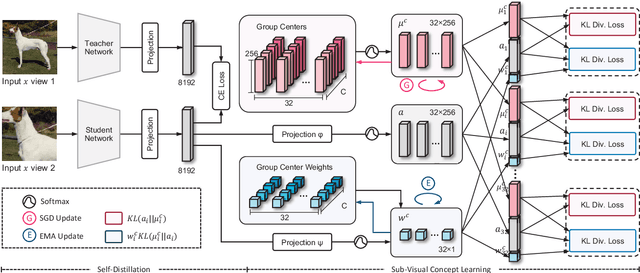
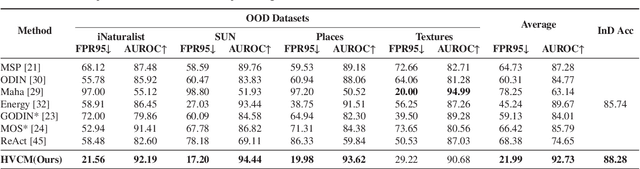
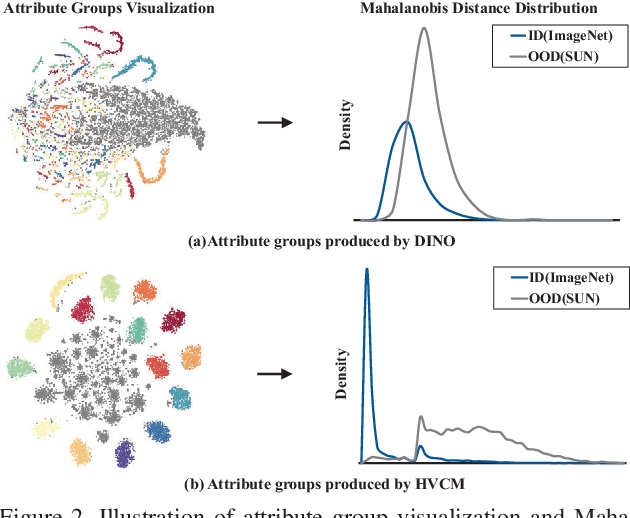
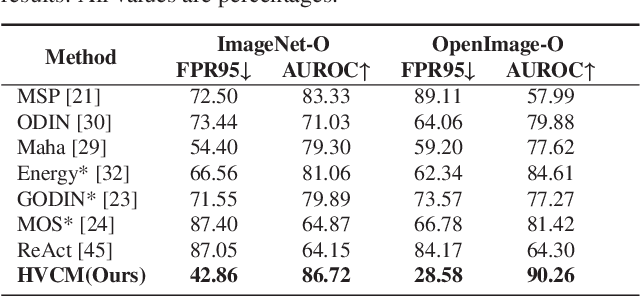
Detecting out-of-distribution inputs for visual recognition models has become critical in safe deep learning. This paper proposes a novel hierarchical visual category modeling scheme to separate out-of-distribution data from in-distribution data through joint representation learning and statistical modeling. We learn a mixture of Gaussian models for each in-distribution category. There are many Gaussian mixture models to model different visual categories. With these Gaussian models, we design an in-distribution score function by aggregating multiple Mahalanobis-based metrics. We don't use any auxiliary outlier data as training samples, which may hurt the generalization ability of out-of-distribution detection algorithms. We split the ImageNet-1k dataset into ten folds randomly. We use one fold as the in-distribution dataset and the others as out-of-distribution datasets to evaluate the proposed method. We also conduct experiments on seven popular benchmarks, including CIFAR, iNaturalist, SUN, Places, Textures, ImageNet-O, and OpenImage-O. Extensive experiments indicate that the proposed method outperforms state-of-the-art algorithms clearly. Meanwhile, we find that our visual representation has a competitive performance when compared with features learned by classical methods. These results demonstrate that the proposed method hasn't weakened the discriminative ability of visual recognition models and keeps high efficiency in detecting out-of-distribution samples.
LVOS: A Benchmark for Large-scale Long-term Video Object Segmentation
May 01, 2024
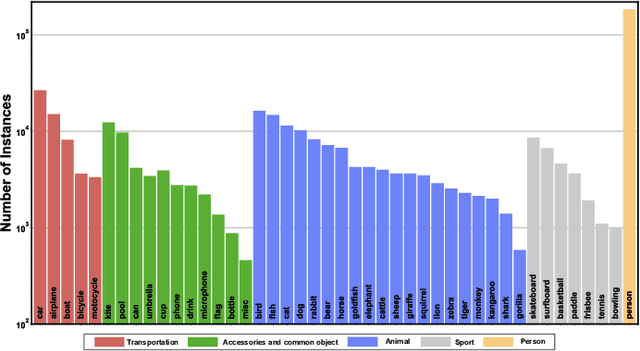

Video object segmentation (VOS) aims to distinguish and track target objects in a video. Despite the excellent performance achieved by off-the-shell VOS models, existing VOS benchmarks mainly focus on short-term videos lasting about 5 seconds, where objects remain visible most of the time. However, these benchmarks poorly represent practical applications, and the absence of long-term datasets restricts further investigation of VOS in realistic scenarios. Thus, we propose a novel benchmark named LVOS, comprising 720 videos with 296,401 frames and 407,945 high-quality annotations. Videos in LVOS last 1.14 minutes on average, approximately 5 times longer than videos in existing datasets. Each video includes various attributes, especially challenges deriving from the wild, such as long-term reappearing and cross-temporal similar objects. Compared to previous benchmarks, our LVOS better reflects VOS models' performance in real scenarios. Based on LVOS, we evaluate 20 existing VOS models under 4 different settings and conduct a comprehensive analysis. On LVOS, these models suffer a large performance drop, highlighting the challenge of achieving precise tracking and segmentation in real-world scenarios. Attribute-based analysis indicates that key factor to accuracy decline is the increased video length, emphasizing LVOS's crucial role. We hope our LVOS can advance development of VOS in real scenes. Data and code are available at https://lingyihongfd.github.io/lvos.github.io/.
OneTracker: Unifying Visual Object Tracking with Foundation Models and Efficient Tuning
Mar 14, 2024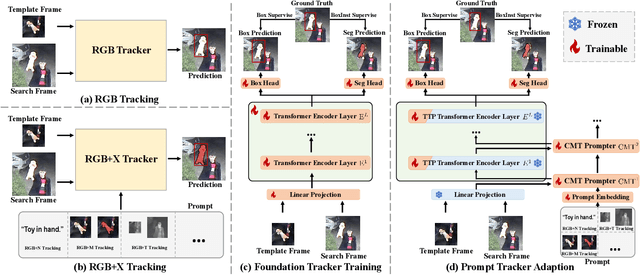
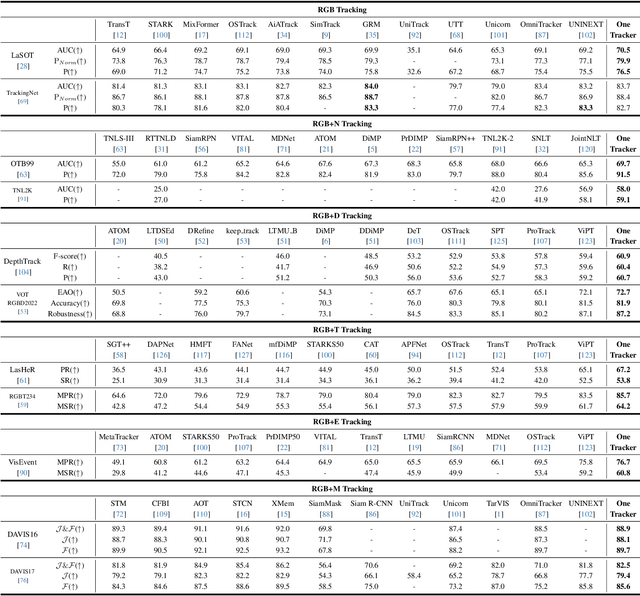
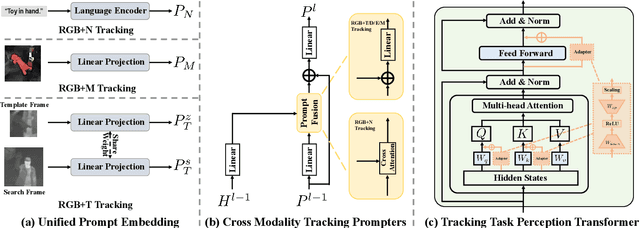

Visual object tracking aims to localize the target object of each frame based on its initial appearance in the first frame. Depending on the input modility, tracking tasks can be divided into RGB tracking and RGB+X (e.g. RGB+N, and RGB+D) tracking. Despite the different input modalities, the core aspect of tracking is the temporal matching. Based on this common ground, we present a general framework to unify various tracking tasks, termed as OneTracker. OneTracker first performs a large-scale pre-training on a RGB tracker called Foundation Tracker. This pretraining phase equips the Foundation Tracker with a stable ability to estimate the location of the target object. Then we regard other modality information as prompt and build Prompt Tracker upon Foundation Tracker. Through freezing the Foundation Tracker and only adjusting some additional trainable parameters, Prompt Tracker inhibits the strong localization ability from Foundation Tracker and achieves parameter-efficient finetuning on downstream RGB+X tracking tasks. To evaluate the effectiveness of our general framework OneTracker, which is consisted of Foundation Tracker and Prompt Tracker, we conduct extensive experiments on 6 popular tracking tasks across 11 benchmarks and our OneTracker outperforms other models and achieves state-of-the-art performance.