 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagOOD: A Novel Approach to Out-of-Distribution Detection via Vision-Language Representations and Class Center Learning
Paper and Code

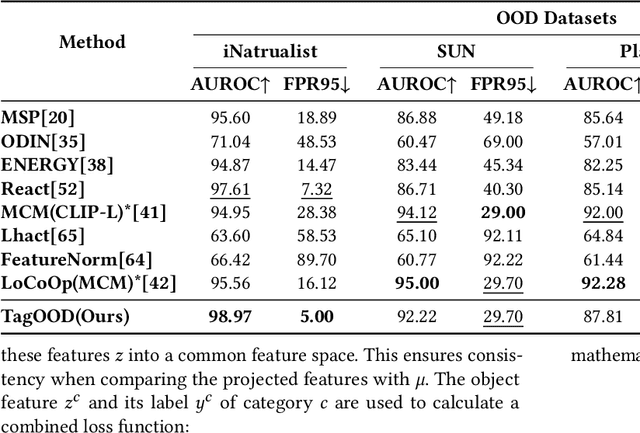
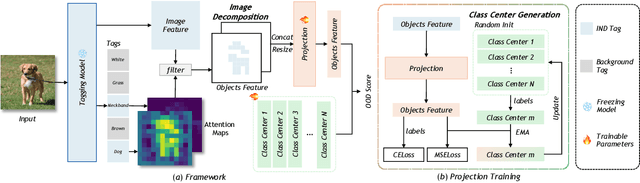

Multimodal fusion, leveraging data like vision and language, is rapidly gaining traction. This enriched data representation improves performance across various tasks. Existing methods for out-of-distribution (OOD) detection, a critical area where AI models encounter unseen data in real-world scenarios, rely heavily on whole-image features. These image-level features can include irrelevant information that hinders the detection of OOD samples, ultimately limiting overall performance. In this paper, we propose \textbf{TagOOD}, a novel approach for OOD detection that leverages vision-language representations to achieve label-free object feature decoupling from whole images. This decomposition enables a more focused analysis of object semantics, enhancing OOD detection performance. Subsequently, TagOOD trains a lightweight network on the extracted object features to learn representative class centers. These centers capture the central tendencies of IND object classes, minimizing the influence of irrelevant image features during OOD detection. Finally, our approach efficiently detects OOD samples by calculating distance-based metrics as OOD scores between learned centers and test samples. We conduct extensive experiments to evaluate TagOOD on several benchmark datasets and demonstrate its superior performance compared to existing OOD detection methods. This work presents a novel perspective for further exploration of multimodal information utilization in OOD detection, with potential applications across various tasks.