 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Saliency Guided Trunk-Collateral Network for Unsupervised Video Object Segmentation
Apr 08, 2025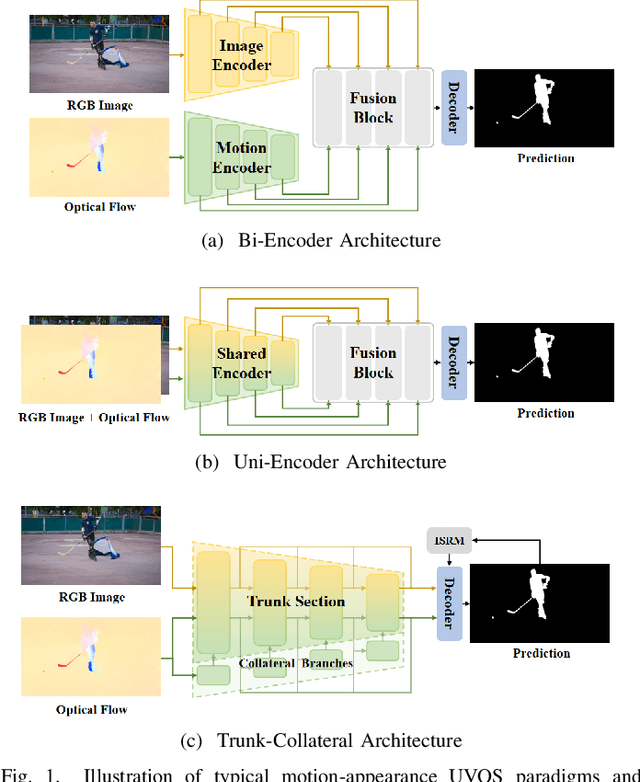

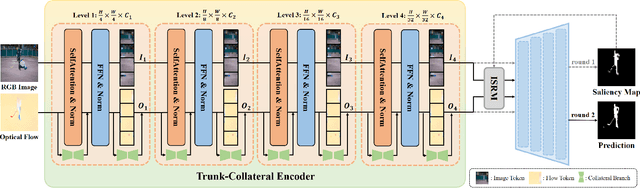
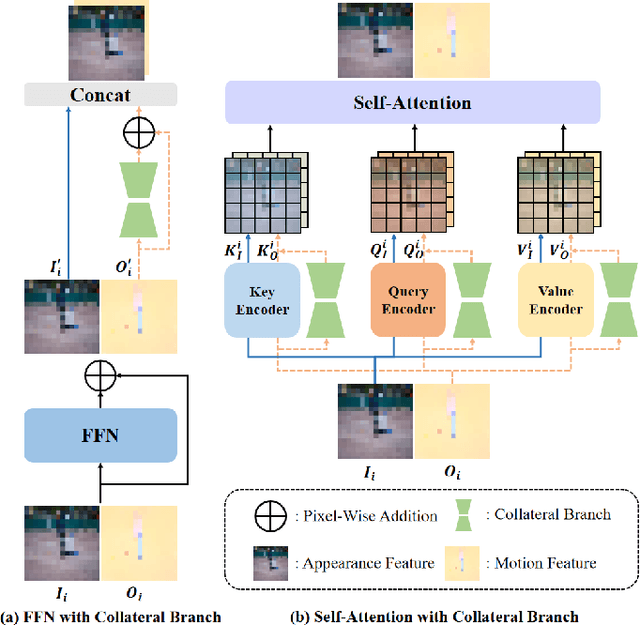
Recent unsupervised video object segmentation (UVOS) methods predominantly adopt the motion-appearance paradigm. Mainstream motion-appearance approaches use either the two-encoder structure to separately encode motion and appearance features, or the single-encoder structure for joint encoding. However, these methods fail to properly balance the motion-appearance relationship. Consequently, even with complex fusion modules for motion-appearance integration, the extracted suboptimal features degrade the models' overall performance. Moreover, the quality of optical flow varies across scenarios, making it insufficient to rely solely on optical flow to achieve high-quality segmentation results. To address these challenges, we propose the Intrinsic Saliency guided Trunk-Collateral Net}work (ISTC-Net), which better balances the motion-appearance relationship and incorporates model's intrinsic saliency information to enhance segmentation performance. Specifically, considering that optical flow maps are derived from RGB images, they share both commonalities and differences. We propose a novel Trunk-Collateral structure. The shared trunk backbone captures the motion-appearance commonality, while the collateral branch learns the uniqueness of motion features. Furthermore, an Intrinsic Saliency guided Refinement Module (ISRM) is devised to efficiently leverage the model's intrinsic saliency information to refine high-level features, and provide pixel-level guidance for motion-appearance fusion, thereby enhancing performance without additional input. Experimental results show that ISTC-Net achieved state-of-the-art performance on three UVOS datasets (89.2% J&F on DAVIS-16, 76% J on YouTube-Objects, 86.4% J on FBMS) and four standard video salient object detection (VSOD) benchmarks with the notable increase, demonstrating its effectiveness and superiority over previous methods.
X-Prompt: Multi-modal Visual Prompt for Video Object Segmentation
Sep 28, 2024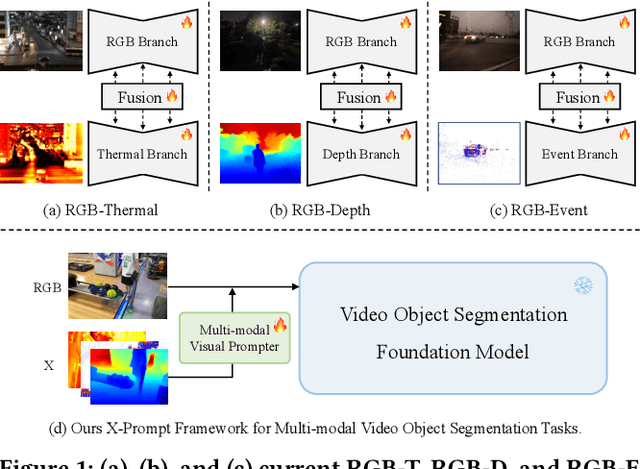
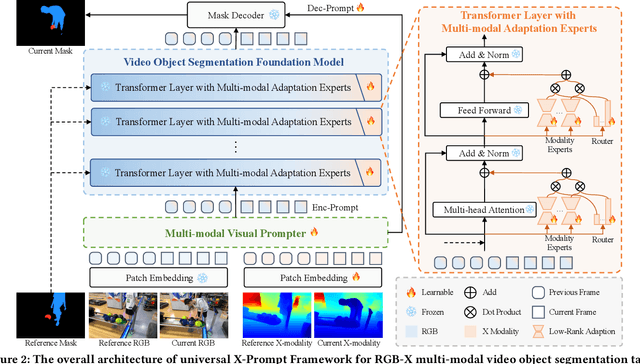
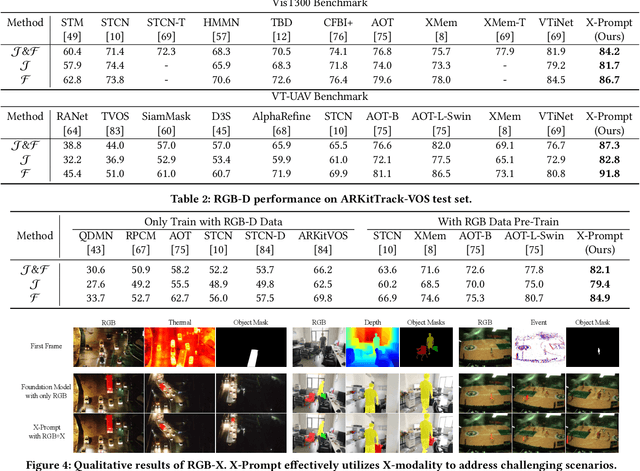
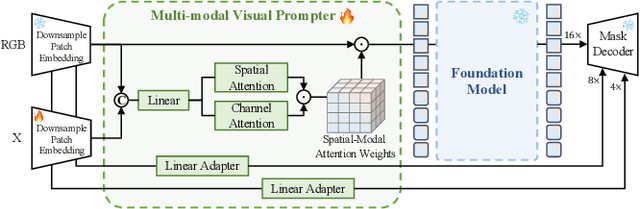
Multi-modal Video Object Segmentation (VOS), including RGB-Thermal, RGB-Depth, and RGB-Event, has garnered attention due to its capability to address challenging scenarios where traditional VOS methods struggle, such as extreme illumination, rapid motion, and background distraction. Existing approaches often involve designing specific additional branches and performing full-parameter fine-tuning for fusion in each task. However, this paradigm not only duplicates research efforts and hardware costs but also risks model collapse with the limited multi-modal annotated data. In this paper, we propose a universal framework named X-Prompt for all multi-modal video object segmentation tasks, designated as RGB+X. The X-Prompt framework first pre-trains a video object segmentation foundation model using RGB data, and then utilize the additional modality of the prompt to adapt it to downstream multi-modal tasks with limited data. Within the X-Prompt framework, we introduce the Multi-modal Visual Prompter (MVP), which allows prompting foundation model with the various modalities to segment objects precisely. We further propose the Multi-modal Adaptation Experts (MAEs) to adapt the foundation model with pluggable modality-specific knowledge without compromising the generalization capacity. To evaluate the effectiveness of the X-Prompt framework, we conduct extensive experiments on 3 tasks across 4 benchmarks. The proposed universal X-Prompt framework consistently outperforms the full fine-tuning paradigm and achieves state-of-the-art performance. Code: https://github.com/PinxueGuo/X-Prompt.git
OneTracker: Unifying Visual Object Tracking with Foundation Models and Efficient Tuning
Mar 14, 2024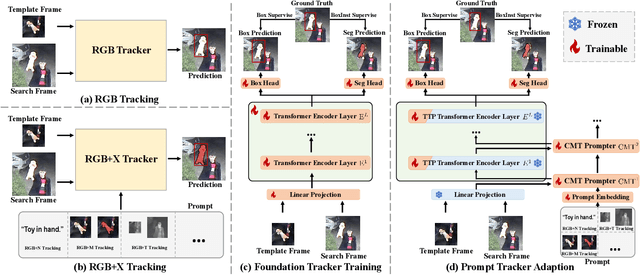
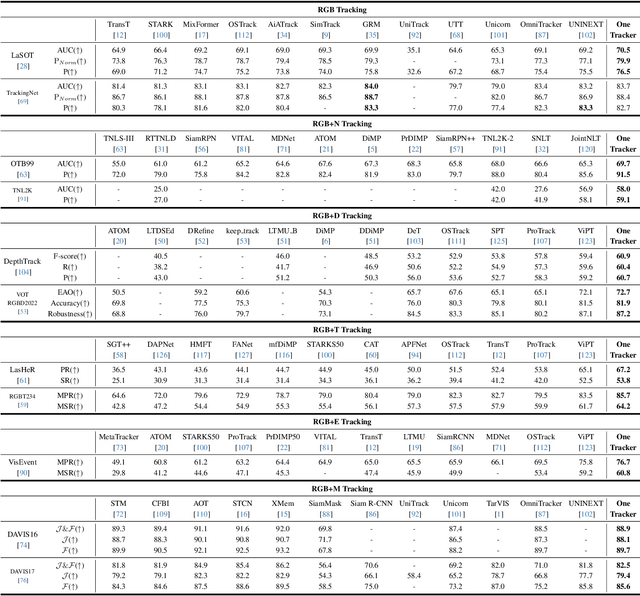
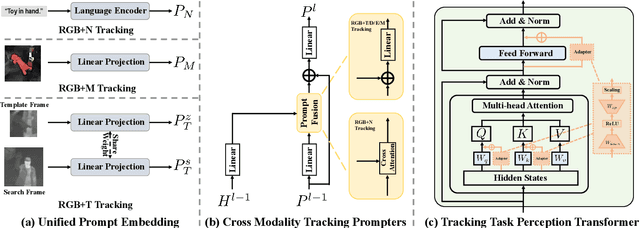

Visual object tracking aims to localize the target object of each frame based on its initial appearance in the first frame. Depending on the input modility, tracking tasks can be divided into RGB tracking and RGB+X (e.g. RGB+N, and RGB+D) tracking. Despite the different input modalities, the core aspect of tracking is the temporal matching. Based on this common ground, we present a general framework to unify various tracking tasks, termed as OneTracker. OneTracker first performs a large-scale pre-training on a RGB tracker called Foundation Tracker. This pretraining phase equips the Foundation Tracker with a stable ability to estimate the location of the target object. Then we regard other modality information as prompt and build Prompt Tracker upon Foundation Tracker. Through freezing the Foundation Tracker and only adjusting some additional trainable parameters, Prompt Tracker inhibits the strong localization ability from Foundation Tracker and achieves parameter-efficient finetuning on downstream RGB+X tracking tasks. To evaluate the effectiveness of our general framework OneTracker, which is consisted of Foundation Tracker and Prompt Tracker, we conduct extensive experiments on 6 popular tracking tasks across 11 benchmarks and our OneTracker outperforms other models and achieves state-of-the-art performance.
OneVOS: Unifying Video Object Segmentation with All-in-One Transformer Framework
Mar 13, 2024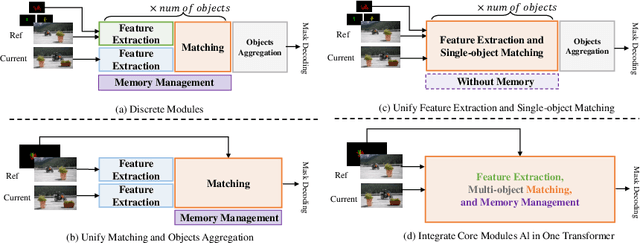



Contemporary Video Object Segmentation (VOS) approaches typically consist stages of feature extraction, matching, memory management, and multiple objects aggregation. Recent advanced models either employ a discrete modeling for these components in a sequential manner, or optimize a combined pipeline through substructure aggregation. However, these existing explicit staged approaches prevent the VOS framework from being optimized as a unified whole, leading to the limited capacity and suboptimal performance in tackling complex videos. In this paper, we propose OneVOS, a novel framework that unifies the core components of VOS with All-in-One Transformer. Specifically, to unify all aforementioned modules into a vision transformer, we model all the features of frames, masks and memory for multiple objects as transformer tokens, and integrally accomplish feature extraction, matching and memory management of multiple objects through the flexible attention mechanism. Furthermore, a Unidirectional Hybrid Attention is proposed through a double decoupling of the original attention operation, to rectify semantic errors and ambiguities of stored tokens in OneVOS framework. Finally, to alleviate the storage burden and expedite inference, we propose the Dynamic Token Selector, which unveils the working mechanism of OneVOS and naturally leads to a more efficient version of OneVOS. Extensive experiments demonstrate the superiority of OneVOS, achieving state-of-the-art performance across 7 datasets, particularly excelling in complex LVOS and MOSE datasets with 70.1% and 66.4% $J \& F$ scores, surpassing previous state-of-the-art methods by 4.2% and 7.0%, respectively. And our code will be available for reproducibility and further research.
ClickVOS: Click Video Object Segmentation
Mar 10, 2024
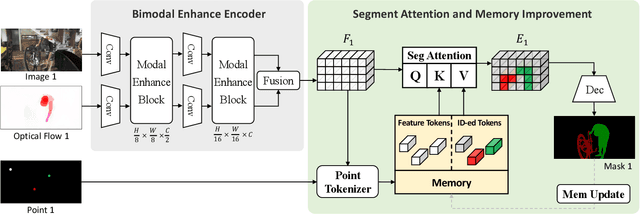


Video Object Segmentation (VOS) task aims to segment objects in videos. However, previous settings either require time-consuming manual masks of target objects at the first frame during inference or lack the flexibility to specify arbitrary objects of interest. To address these limitations, we propose the setting named Click Video Object Segmentation (ClickVOS) which segments objects of interest across the whole video according to a single click per object in the first frame. And we provide the extended datasets DAVIS-P and YouTubeVOSP that with point annotations to support this task. ClickVOS is of significant practical applications and research implications due to its only 1-2 seconds interaction time for indicating an object, comparing annotating the mask of an object needs several minutes. However, ClickVOS also presents increased challenges. To address this task, we propose an end-to-end baseline approach named called Attention Before Segmentation (ABS), motivated by the attention process of humans. ABS utilizes the given point in the first frame to perceive the target object through a concise yet effective segmentation attention. Although the initial object mask is possibly inaccurate, in our ABS, as the video goes on, the initially imprecise object mask can self-heal instead of deteriorating due to error accumulation, which is attributed to our designed improvement memory that continuously records stable global object memory and updates detailed dense memory. In addition, we conduct various baseline explorations utilizing off-the-shelf algorithms from related fields, which could provide insights for the further exploration of ClickVOS. The experimental results demonstrate the superiority of the proposed ABS approach. Extended datasets and codes will be available at https://github.com/PinxueGuo/ClickVOS.
Wavelet Transform-assisted Adaptive Generative Modeling for Colorization
Jul 09, 2021


Unsupervised deep learning has recently demonstrated the promise to produce high-quality samples. While it has tremendous potential to promote the image colorization task, the performance is limited owing to the manifold hypothesis in machine learning. This study presents a novel scheme that exploiting the score-based generative model in wavelet domain to address the issue. By taking advantage of the multi-scale and multi-channel representation via wavelet transform, the proposed model learns the priors from stacked wavelet coefficient components, thus learns the image characteristics under coarse and detail frequency spectrums jointly and effectively. Moreover, such a highly flexible generative model without adversarial optimization can execute colorization tasks better under dual consistency terms in wavelet domain, namely data-consistency and structure-consistency. Specifically, in the training phase, a set of multi-channel tensors consisting of wavelet coefficients are used as the input to train the network by denoising score matching. In the test phase, samples are iteratively generated via annealed Langevin dynamics with data and structure consistencies. Experiments demonstrated remarkable improvements of the proposed model on colorization quality, particularly on colorization robustness and diversity.
Joint Intensity-Gradient Guided Generative Modeling for Colorization
Dec 28, 2020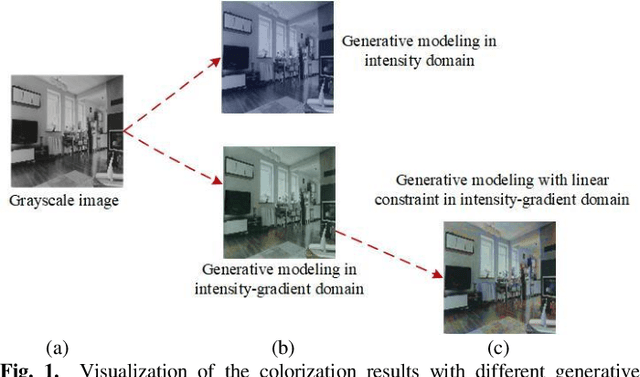


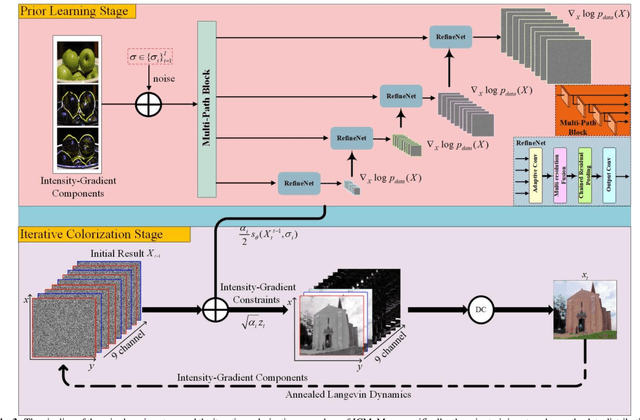
This paper proposes an iterative generative model for solving the automatic colorization problem. Although previous researches have shown the capability to generate plausible color, the edge color overflow and the requirement of the reference images still exist. The starting point of the unsupervised learning in this study is the observation that the gradient map possesses latent information of the image. Therefore, the inference process of the generative modeling is conducted in joint intensity-gradient domain. Specifically, a set of intensity-gradient formed high-dimensional tensors, as the network input, are used to train a powerful noise conditional score network at the training phase. Furthermore, the joint intensity-gradient constraint in data-fidelity term is proposed to limit the degree of freedom within generative model at the iterative colorization stage, and it is conducive to edge-preserving. Extensive experiments demonstrated that the system outperformed state-of-the-art methods whether in quantitative comparisons or user study.