 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Prompt: Multi-modal Visual Prompt for Video Object Segmentation
Paper and Code
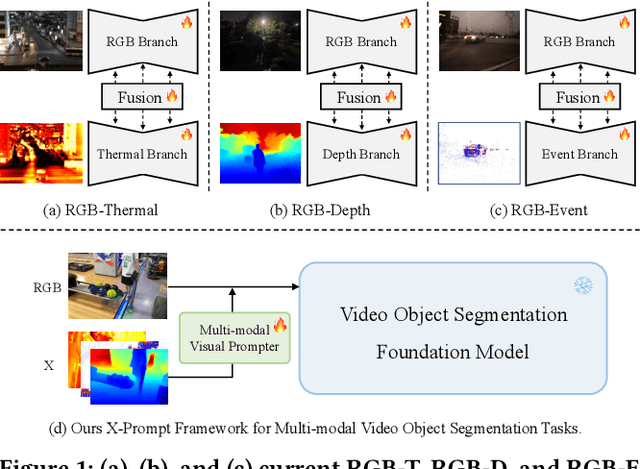
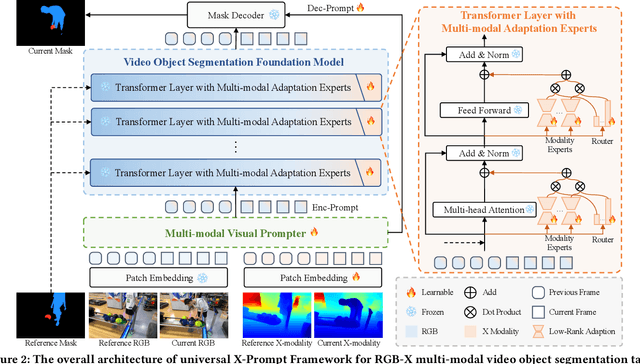
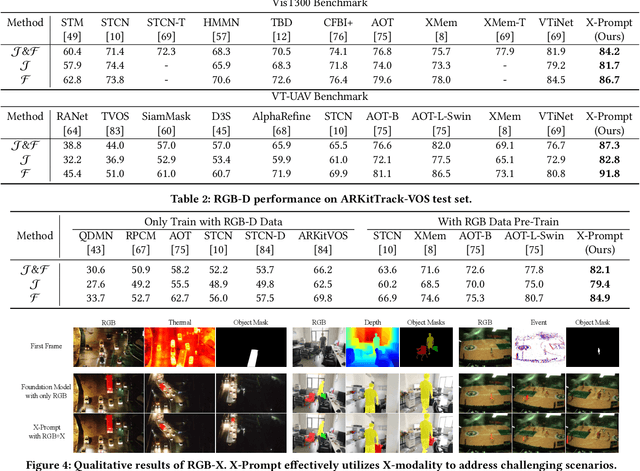
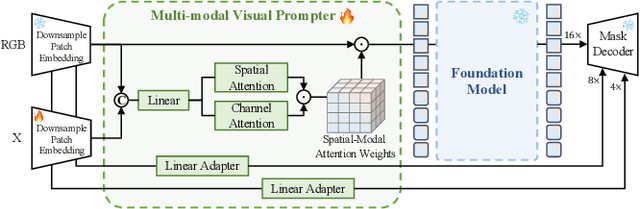
Multi-modal Video Object Segmentation (VOS), including RGB-Thermal, RGB-Depth, and RGB-Event, has garnered attention due to its capability to address challenging scenarios where traditional VOS methods struggle, such as extreme illumination, rapid motion, and background distraction. Existing approaches often involve designing specific additional branches and performing full-parameter fine-tuning for fusion in each task. However, this paradigm not only duplicates research efforts and hardware costs but also risks model collapse with the limited multi-modal annotated data. In this paper, we propose a universal framework named X-Prompt for all multi-modal video object segmentation tasks, designated as RGB+X. The X-Prompt framework first pre-trains a video object segmentation foundation model using RGB data, and then utilize the additional modality of the prompt to adapt it to downstream multi-modal tasks with limited data. Within the X-Prompt framework, we introduce the Multi-modal Visual Prompter (MVP), which allows prompting foundation model with the various modalities to segment objects precisely. We further propose the Multi-modal Adaptation Experts (MAEs) to adapt the foundation model with pluggable modality-specific knowledge without compromising the generalization capacity. To evaluate the effectiveness of the X-Prompt framework, we conduct extensive experiments on 3 tasks across 4 benchmarks. The proposed universal X-Prompt framework consistently outperforms the full fine-tuning paradigm and achieves state-of-the-art performance. Code: https://github.com/PinxueGuo/X-Prompt.git