 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling in Sinogram Domain for Sparse-view CT Reconstruction
Nov 25, 2022


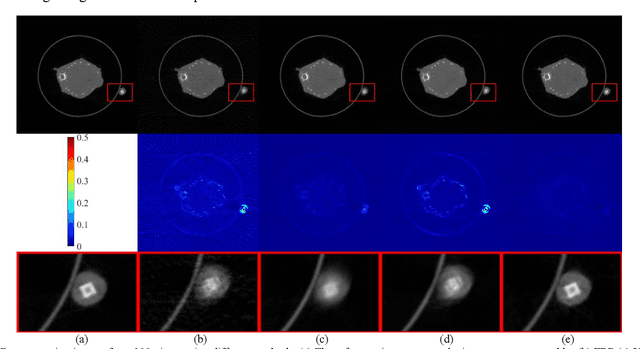
The radiation dose in computed tomography (CT) examinations is harmful for patients but can be significantly reduced by intuitively decreasing the number of projection views. Reducing projection views usually leads to severe aliasing artifacts in reconstructed images. Previous deep learning (DL) techniques with sparse-view data require sparse-view/full-view CT image pairs to train the network with supervised manners. When the number of projection view changes, the DL network should be retrained with updated sparse-view/full-view CT image pairs. To relieve this limitation, we present a fully unsupervised score-based generative model in sinogram domain for sparse-view CT reconstruction. Specifically, we first train a score-based generative model on full-view sinogram data and use multi-channel strategy to form highdimensional tensor as the network input to capture their prior distribution. Then, at the inference stage, the stochastic differential equation (SDE) solver and data-consistency step were performed iteratively to achieve fullview projection. Filtered back-projection (FBP) algorithm was used to achieve the final image reconstruction. Qualitative and quantitative studies were implemented to evaluate the presented method with several CT data. Experimental results demonstrated that our method achieved comparable or better performance than the supervised learning counterparts.
Virtual Coil Augmentation Technology for MRI via Deep Learning
Jan 19, 2022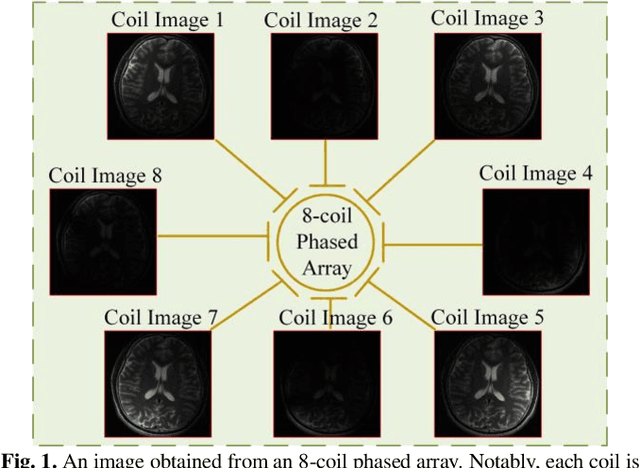
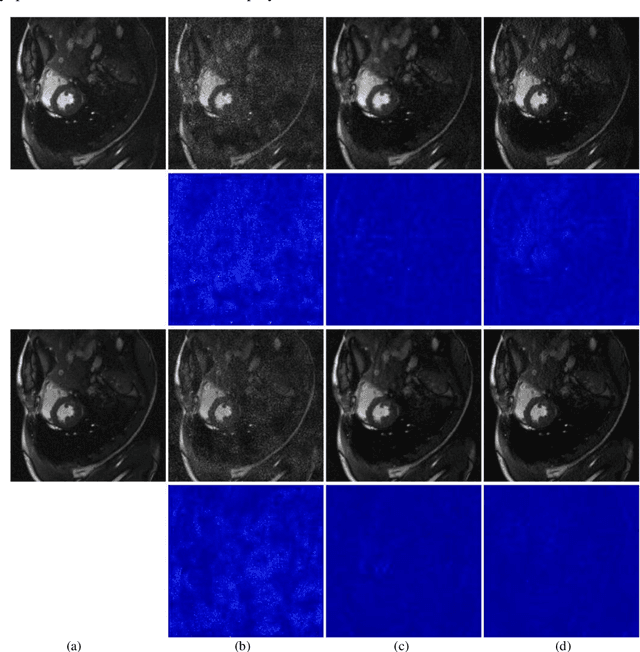
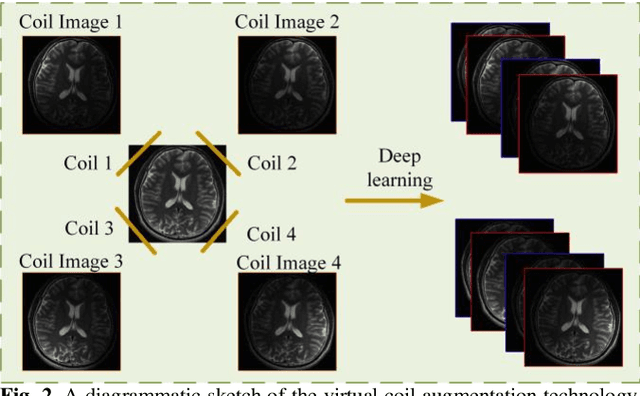
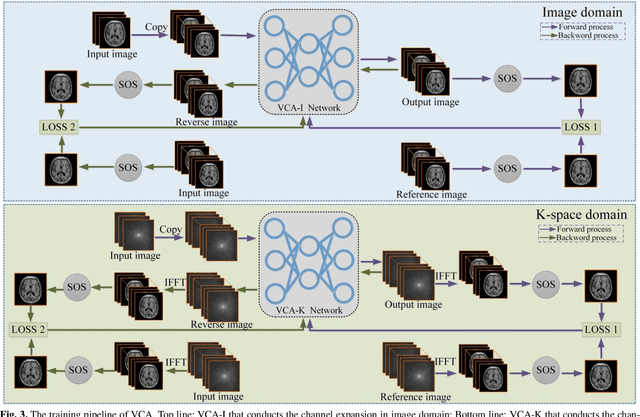
Magnetic resonance imaging (MRI) is a widely used medical imaging modality. However, due to the limitations in hardware, scan time, and throughput, it is often clinically challenging to obtain high-quality MR images. In this article, we propose a method of using artificial intelligence to expand the channel to achieve the effect of increasing the virtual coil. The main feature of our work is utilizing dummy variable technology to expand the channel in both the image and k-space domains. The high-dimensional information formed by channel expansion is used as the prior information of parallel imaging to improve the reconstruction effect of parallel imaging. Two features are introduced, namely variable enhancement and sum of squares (SOS) objective function. Variable argumentation provides the network with more high-dimensional prior information, which is helpful for the network to extract the deep feature in-formation of the image. The SOS objective function is employed to solve the problem that k-space data is difficult to train while speeding up the convergence speed. Ablation studies and experimental results demonstrate that our method achieves significantly higher image reconstruction performance than current state-of-the-art techniques.
Variable Augmented Network for Invertible Modality Synthesis-Fusion
Sep 02, 2021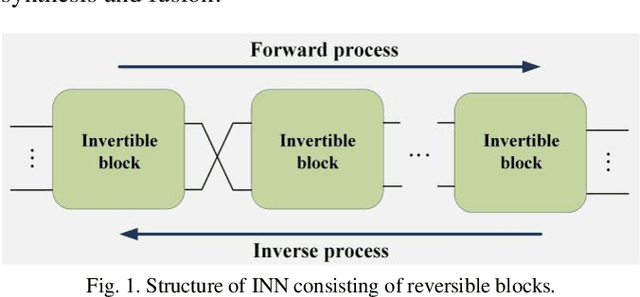



As an effective way to integrate the information contained in multiple medical images under different modalities, medical image synthesis and fusion have emerged in various clinical applications such as disease diagnosis and treatment planning. In this paper, an invertible and variable augmented network (iVAN) is proposed for medical image synthesis and fusion. In iVAN, the channel number of the network input and output is the same through variable augmentation technology, and data relevance is enhanced, which is conducive to the generation of characterization information. Meanwhile, the invertible network is used to achieve the bidirectional inference processes. Due to the invertible and variable augmentation schemes, iVAN can not only be applied to the mappings of multi-input to one-output and multi-input to multi-output, but also be applied to one-input to multi-output. Experimental results demonstrated that the proposed method can obtain competitive or superior performance in comparison to representative medical image synthesis and fusion methods.
High-dimensional Assisted Generative Model for Color Image Restoration
Aug 14, 2021


This work presents an unsupervised deep learning scheme that exploiting high-dimensional assisted score-based generative model for color image restoration tasks. Considering that the sample number and internal dimension in score-based generative model have key influence on estimating the gradients of data distribution, two different high-dimensional ways are proposed: The channel-copy transformation increases the sample number and the pixel-scale transformation decreases feasible space dimension. Subsequently, a set of high-dimensional tensors represented by these transformations are used to train the network through denoising score matching. Then, sampling is performed by annealing Langevin dynamics and alternative data-consistency update. Furthermore, to alleviate the difficulty of learning high-dimensional representation, a progressive strategy is proposed to leverage the performance. The proposed unsupervised learning and iterative restoration algo-rithm, which involves a pre-trained generative network to obtain prior, has transparent and clear interpretation compared to other data-driven approaches. Experimental results on demosaicking and inpainting conveyed the remarkable performance and diversity of our proposed method.
Joint Intensity-Gradient Guided Generative Modeling for Colorization
Dec 28, 2020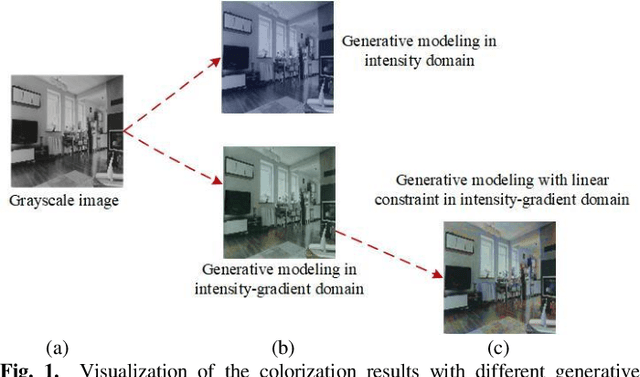


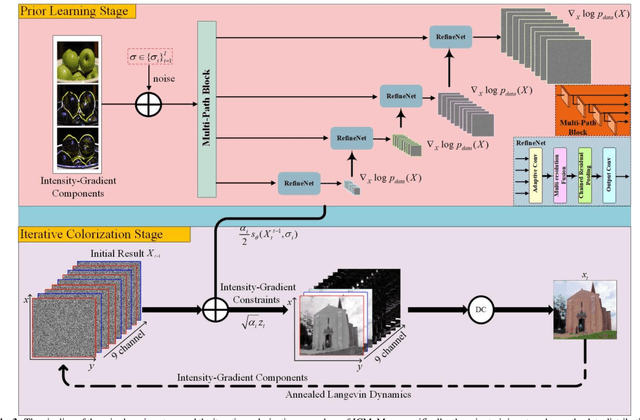
This paper proposes an iterative generative model for solving the automatic colorization problem. Although previous researches have shown the capability to generate plausible color, the edge color overflow and the requirement of the reference images still exist. The starting point of the unsupervised learning in this study is the observation that the gradient map possesses latent information of the image. Therefore, the inference process of the generative modeling is conducted in joint intensity-gradient domain. Specifically, a set of intensity-gradient formed high-dimensional tensors, as the network input, are used to train a powerful noise conditional score network at the training phase. Furthermore, the joint intensity-gradient constraint in data-fidelity term is proposed to limit the degree of freedom within generative model at the iterative colorization stage, and it is conducive to edge-preserving. Extensive experiments demonstrated that the system outperformed state-of-the-art methods whether in quantitative comparisons or user study.