 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling in Structural-Hankel Domain for Color Image Inpainting
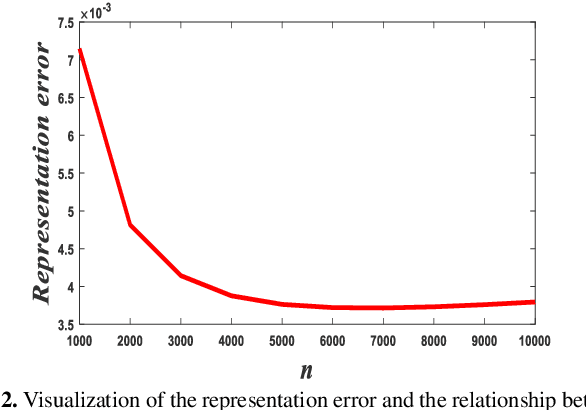
Nov 25, 2022In recent years, some researchers focused on using a single image to obtain a large number of samples through multi-scale features. This study intends to a brand-new idea that requires only ten or even fewer samples to construct the low-rank structural-Hankel matrices-assisted score-based generative model (SHGM) for color image inpainting task. During the prior learning process, a certain amount of internal-middle patches are firstly extracted from several images and then the structural-Hankel matrices are constructed from these patches. To better apply the score-based generative model to learn the internal statistical distribution within patches, the large-scale Hankel matrices are finally folded into the higher dimensional tensors for prior learning. During the iterative inpainting process, SHGM views the inpainting problem as a conditional generation procedure in low-rank environment. As a result, the intermediate restored image is acquired by alternatively performing the stochastic differential equation solver, alternating direction method of multipliers, and data consistency steps. Experimental results demonstrated the remarkable performance and diversity of SHGM.
High-dimensional Assisted Generative Model for Color Image Restoration
Aug 14, 2021


This work presents an unsupervised deep learning scheme that exploiting high-dimensional assisted score-based generative model for color image restoration tasks. Considering that the sample number and internal dimension in score-based generative model have key influence on estimating the gradients of data distribution, two different high-dimensional ways are proposed: The channel-copy transformation increases the sample number and the pixel-scale transformation decreases feasible space dimension. Subsequently, a set of high-dimensional tensors represented by these transformations are used to train the network through denoising score matching. Then, sampling is performed by annealing Langevin dynamics and alternative data-consistency update. Furthermore, to alleviate the difficulty of learning high-dimensional representation, a progressive strategy is proposed to leverage the performance. The proposed unsupervised learning and iterative restoration algo-rithm, which involves a pre-trained generative network to obtain prior, has transparent and clear interpretation compared to other data-driven approaches. Experimental results on demosaicking and inpainting conveyed the remarkable performance and diversity of our proposed method.
Text Classification with Lexicon from PreAttention Mechanism
Feb 18, 2020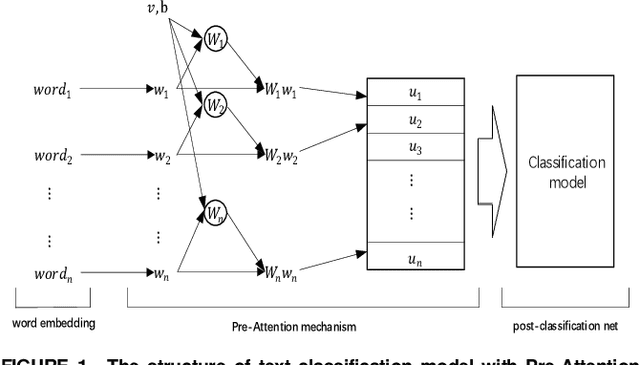


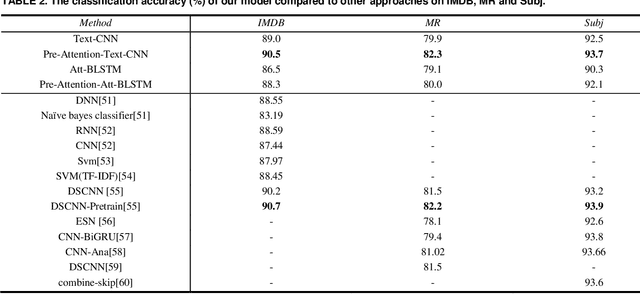
A comprehensive and high-quality lexicon plays a crucial role in traditional text classification approaches. And it improves the utilization of the linguistic knowledge. Although it is helpful for the task, the lexicon has got little attention in recent neural network models. Firstly, getting a high-quality lexicon is not easy. We lack an effective automated lexicon extraction method, and most lexicons are hand crafted, which is very inefficient for big data. What's more, there is no an effective way to use a lexicon in a neural network. To address those limitations, we propose a Pre-Attention mechanism for text classification in this paper, which can learn attention of different words according to their effects in the classification tasks. The words with different attention can form a domain lexicon. Experiments on three benchmark text classification tasks show that our models get competitive result comparing with the state-of-the-art methods. We get 90.5% accuracy on Stanford Large Movie Review dataset, 82.3% on Subjectivity dataset, 93.7% on Movie Reviews. And compared with the text classification model without Pre-Attention mechanism, those with Pre-Attention mechanism improve by 0.9%-2.4% accuracy, which proves the validity of the Pre-Attention mechanism. In addition, the Pre-Attention mechanism performs well followed by different types of neural networks (e.g., convolutional neural networks and Long Short-Term Memory networks). For the same dataset, when we use Pre-Attention mechanism to get attention value followed by different neural networks, those words with high attention values have a high degree of coincidence, which proves the versatility and portability of the Pre-Attention mechanism. we can get stable lexicons by attention values, which is an inspiring method of information extraction.