 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification with Lexicon from PreAttention Mechanism
Paper and Code
Feb 18, 2020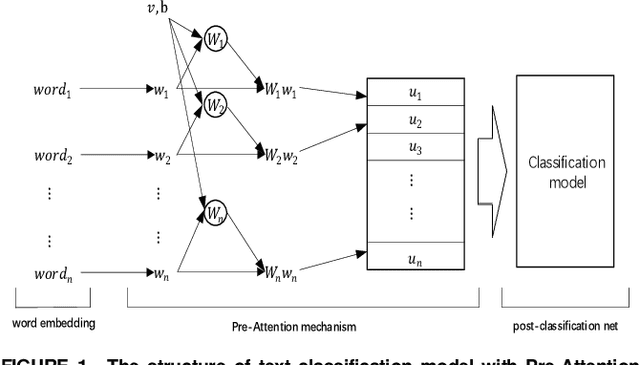


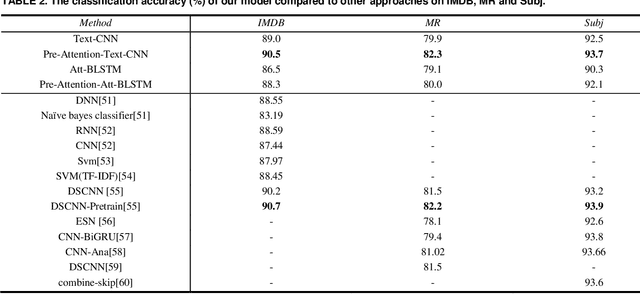
A comprehensive and high-quality lexicon plays a crucial role in traditional text classification approaches. And it improves the utilization of the linguistic knowledge. Although it is helpful for the task, the lexicon has got little attention in recent neural network models. Firstly, getting a high-quality lexicon is not easy. We lack an effective automated lexicon extraction method, and most lexicons are hand crafted, which is very inefficient for big data. What's more, there is no an effective way to use a lexicon in a neural network. To address those limitations, we propose a Pre-Attention mechanism for text classification in this paper, which can learn attention of different words according to their effects in the classification tasks. The words with different attention can form a domain lexicon. Experiments on three benchmark text classification tasks show that our models get competitive result comparing with the state-of-the-art methods. We get 90.5% accuracy on Stanford Large Movie Review dataset, 82.3% on Subjectivity dataset, 93.7% on Movie Reviews. And compared with the text classification model without Pre-Attention mechanism, those with Pre-Attention mechanism improve by 0.9%-2.4% accuracy, which proves the validity of the Pre-Attention mechanism. In addition, the Pre-Attention mechanism performs well followed by different types of neural networks (e.g., convolutional neural networks and Long Short-Term Memory networks). For the same dataset, when we use Pre-Attention mechanism to get attention value followed by different neural networks, those words with high attention values have a high degree of coincidence, which proves the versatility and portability of the Pre-Attention mechanism. we can get stable lexicons by attention values, which is an inspiring method of information extraction.