 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneVOS: Unifying Video Object Segmentation with All-in-One Transformer Framework
Mar 13, 2024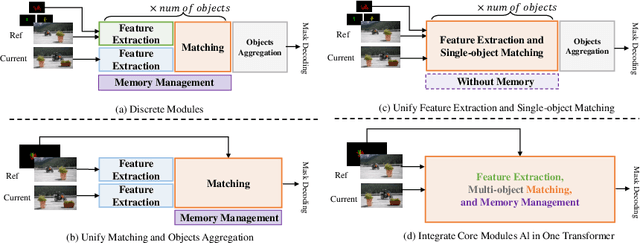



Contemporary Video Object Segmentation (VOS) approaches typically consist stages of feature extraction, matching, memory management, and multiple objects aggregation. Recent advanced models either employ a discrete modeling for these components in a sequential manner, or optimize a combined pipeline through substructure aggregation. However, these existing explicit staged approaches prevent the VOS framework from being optimized as a unified whole, leading to the limited capacity and suboptimal performance in tackling complex videos. In this paper, we propose OneVOS, a novel framework that unifies the core components of VOS with All-in-One Transformer. Specifically, to unify all aforementioned modules into a vision transformer, we model all the features of frames, masks and memory for multiple objects as transformer tokens, and integrally accomplish feature extraction, matching and memory management of multiple objects through the flexible attention mechanism. Furthermore, a Unidirectional Hybrid Attention is proposed through a double decoupling of the original attention operation, to rectify semantic errors and ambiguities of stored tokens in OneVOS framework. Finally, to alleviate the storage burden and expedite inference, we propose the Dynamic Token Selector, which unveils the working mechanism of OneVOS and naturally leads to a more efficient version of OneVOS. Extensive experiments demonstrate the superiority of OneVOS, achieving state-of-the-art performance across 7 datasets, particularly excelling in complex LVOS and MOSE datasets with 70.1% and 66.4% $J \& F$ scores, surpassing previous state-of-the-art methods by 4.2% and 7.0%, respectively. And our code will be available for reproducibility and further research.
Weakly-Supervised Salient Object Detection Using Point Supervison
Mar 22, 2022
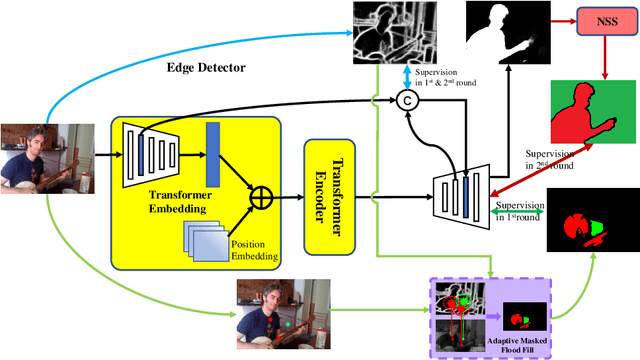
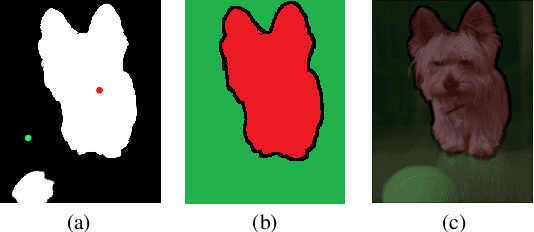
Current state-of-the-art saliency detection models rely heavily on large datasets of accurate pixel-wise annotations, but manually labeling pixels is time-consuming and labor-intensive. There are some weakly supervised methods developed for alleviating the problem, such as image label, bounding box label, and scribble label, while point label still has not been explored in this field. In this paper, we propose a novel weakly-supervised salient object detection method using point supervision. To infer the saliency map, we first design an adaptive masked flood filling algorithm to generate pseudo labels. Then we develop a transformer-based point-supervised saliency detection model to produce the first round of saliency maps. However, due to the sparseness of the label, the weakly supervised model tends to degenerate into a general foreground detection model. To address this issue, we propose a Non-Salient Suppression (NSS) method to optimize the erroneous saliency maps generated in the first round and leverage them for the second round of training. Moreover, we build a new point-supervised dataset (P-DUTS) by relabeling the DUTS dataset. In P-DUTS, there is only one labeled point for each salient object. Comprehensive experiments on five largest benchmark datasets demonstrate our method outperforms the previous state-of-the-art methods trained with the stronger supervision and even surpass several fully supervised state-of-the-art models. The code is available at: https://github.com/shuyonggao/PSOD.
Attribute Surrogates Learning and Spectral Tokens Pooling in Transformers for Few-shot Learning
Mar 17, 2022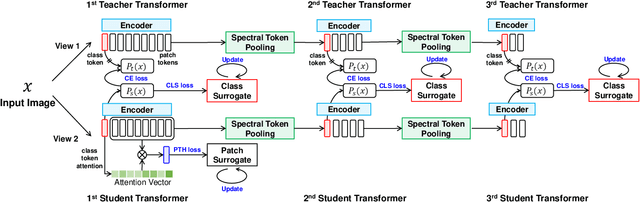
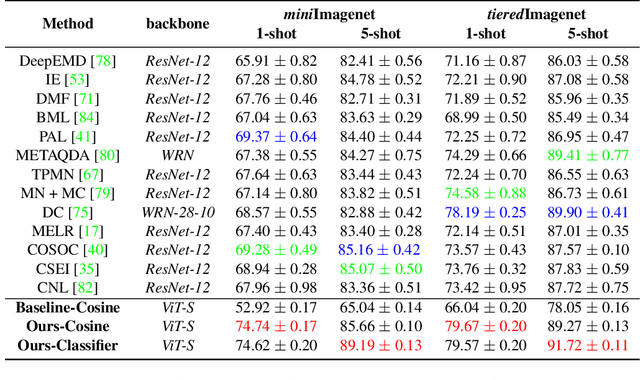
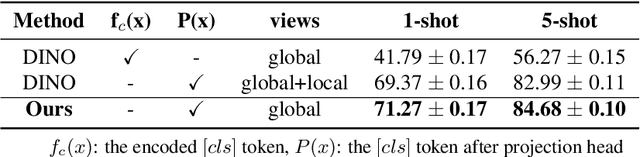

This paper presents new hierarchically cascaded transformers that can improve data efficiency through attribute surrogates learning and spectral tokens pooling. Vision transformers have recently been thought of as a promising alternative to convolutional neural networks for visual recognition. But when there is no sufficient data, it gets stuck in overfitting and shows inferior performance. To improve data efficiency, we propose hierarchically cascaded transformers that exploit intrinsic image structures through spectral tokens pooling and optimize the learnable parameters through latent attribute surrogates. The intrinsic image structure is utilized to reduce the ambiguity between foreground content and background noise by spectral tokens pooling. And the attribute surrogate learning scheme is designed to benefit from the rich visual information in image-label pairs instead of simple visual concepts assigned by their labels. Our Hierarchically Cascaded Transformers, called HCTransformers, is built upon a self-supervised learning framework DINO and is tested on several popular few-shot learning benchmarks. In the inductive setting, HCTransformers surpass the DINO baseline by a large margin of 9.7% 5-way 1-shot accuracy and 9.17% 5-way 5-shot accuracy on miniImageNet, which demonstrates HCTransformers are efficient to extract discriminative features. Also, HCTransformers show clear advantages over SOTA few-shot classification methods in both 5-way 1-shot and 5-way 5-shot settings on four popular benchmark datasets, including miniImageNet, tieredImageNet, FC100, and CIFAR-FS. The trained weights and codes are available at https://github.com/StomachCold/HCTransformers.