 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Double Auction
Apr 07, 2025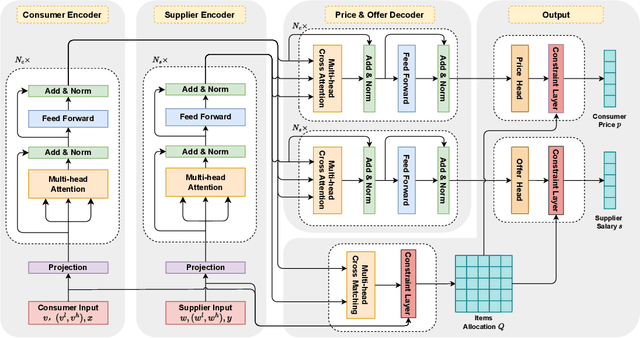



Auctions are important mechanisms extensively implemented in various markets, e.g., search engines' keyword auctions, antique auctions, etc. Finding an optimal auction mechanism is extremely difficult due to the constraints of imperfect information, incentive compatibility (IC), and individual rationality (IR). In addition to the traditional economic methods, some recently attempted to find the optimal (single) auction using deep learning methods. Unlike those attempts focusing on single auctions, we develop deep learning methods for double auctions, where imperfect information exists on both the demand and supply sides. The previous attempts on single auction cannot directly apply to our contexts and those attempts additionally suffer from limited generalizability, inefficiency in ensuring the constraints, and learning fluctuations. We innovate in designing deep learning models for solving the more complex problem and additionally addressing the previous models' three limitations. Specifically, we achieve generalizability by leveraging a transformer-based architecture to model market participants as sequences for varying market sizes; we utilize the numerical features of the constraints and pre-treat them for a higher learning efficiency; we develop a gradient-conflict-elimination scheme to address the problem of learning fluctuation. Extensive experimental evaluations demonstrate the superiority of our approach to classical and machine learning baselines.
DINO-Mix: Enhancing Visual Place Recognition with Foundational Vision Model and Feature Mixing
Nov 01, 2023Utilizing visual place recognition (VPR) technology to ascertain the geographical location of publicly available images is a pressing issue for real-world VPR applications. Although most current VPR methods achieve favorable results under ideal conditions, their performance in complex environments, characterized by lighting variations, seasonal changes, and occlusions caused by moving objects, is generally unsatisfactory. In this study, we utilize the DINOv2 model as the backbone network for trimming and fine-tuning to extract robust image features. We propose a novel VPR architecture called DINO-Mix, which combines a foundational vision model with feature aggregation. This architecture relies on the powerful image feature extraction capabilities of foundational vision models. We employ an MLP-Mixer-based mix module to aggregate image features, resulting in globally robust and generalizable descriptors that enable high-precision VPR. We experimentally demonstrate that the proposed DINO-Mix architecture significantly outperforms current state-of-the-art (SOTA) methods. In test sets having lighting variations, seasonal changes, and occlusions (Tokyo24/7, Nordland, SF-XL-Testv1), our proposed DINO-Mix architecture achieved Top-1 accuracy rates of 91.75%, 80.18%, and 82%, respectively. Compared with SOTA methods, our architecture exhibited an average accuracy improvement of 5.14%.
Weakly-Supervised Salient Object Detection Using Point Supervison
Mar 22, 2022
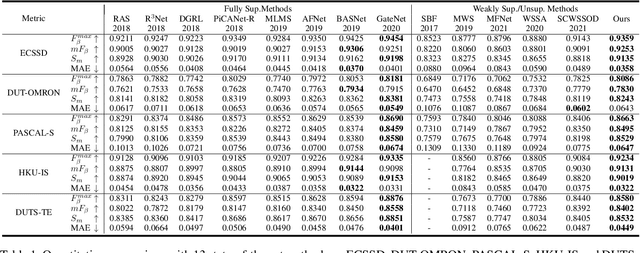
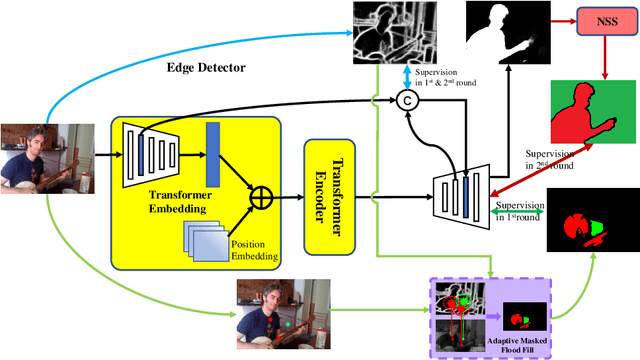
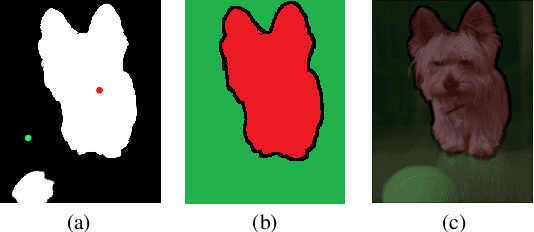
Current state-of-the-art saliency detection models rely heavily on large datasets of accurate pixel-wise annotations, but manually labeling pixels is time-consuming and labor-intensive. There are some weakly supervised methods developed for alleviating the problem, such as image label, bounding box label, and scribble label, while point label still has not been explored in this field. In this paper, we propose a novel weakly-supervised salient object detection method using point supervision. To infer the saliency map, we first design an adaptive masked flood filling algorithm to generate pseudo labels. Then we develop a transformer-based point-supervised saliency detection model to produce the first round of saliency maps. However, due to the sparseness of the label, the weakly supervised model tends to degenerate into a general foreground detection model. To address this issue, we propose a Non-Salient Suppression (NSS) method to optimize the erroneous saliency maps generated in the first round and leverage them for the second round of training. Moreover, we build a new point-supervised dataset (P-DUTS) by relabeling the DUTS dataset. In P-DUTS, there is only one labeled point for each salient object. Comprehensive experiments on five largest benchmark datasets demonstrate our method outperforms the previous state-of-the-art methods trained with the stronger supervision and even surpass several fully supervised state-of-the-art models. The code is available at: https://github.com/shuyonggao/PSOD.
Parallel Spectral Clustering Algorithm Based on Hadoop
May 31, 2015Spectral clustering and cloud computing is emerging branch of computer science or related discipline. It overcome the shortcomings of some traditional clustering algorithm and guarantee the convergence to the optimal solution, thus have to the widespread attention. This article first introduced the parallel spectral clustering algorithm research background and significance, and then to Hadoop the cloud computing Framework has carried on the detailed introduction, then has carried on the related to spectral clustering is introduced, then introduces the spectral clustering arithmetic Method of parallel and relevant steps, finally made the related experiments, and the experiment are summarized.