 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCV-Cities: Advancing Cross-View Geo-Localization in Global Cities
Nov 19, 2024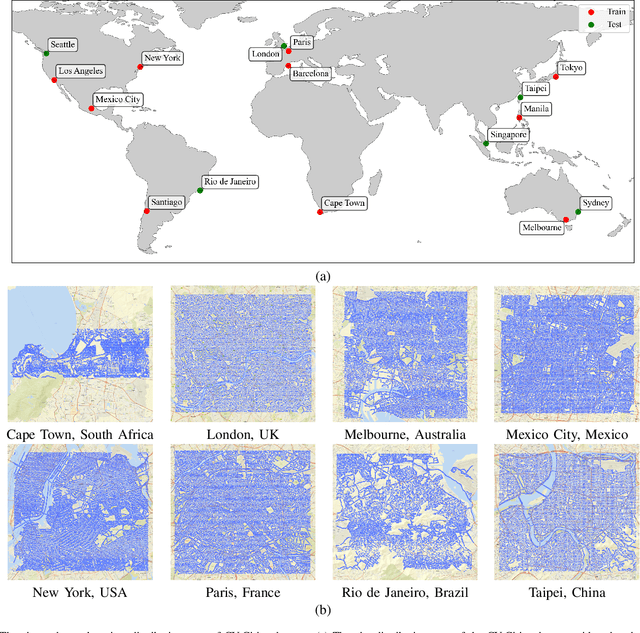
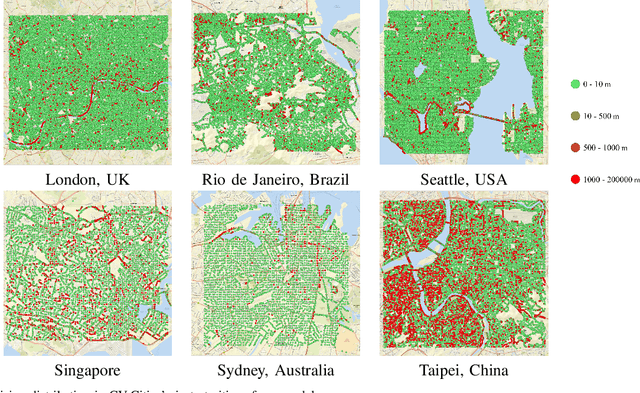
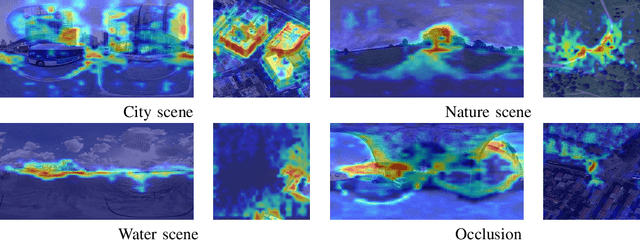

Cross-view geo-localization (CVGL), which involves matching and retrieving satellite images to determine the geographic location of a ground image, is crucial in GNSS-constrained scenarios. However, this task faces significant challenges due to substantial viewpoint discrepancies, the complexity of localization scenarios, and the need for global localization. To address these issues, we propose a novel CVGL framework that integrates the vision foundational model DINOv2 with an advanced feature mixer. Our framework introduces the symmetric InfoNCE loss and incorporates near-neighbor sampling and dynamic similarity sampling strategies, significantly enhancing localization accuracy. Experimental results show that our framework surpasses existing methods across multiple public and self-built datasets. To further improve globalscale performance, we have developed CV-Cities, a novel dataset for global CVGL. CV-Cities includes 223,736 ground-satellite image pairs with geolocation data, spanning sixteen cities across six continents and covering a wide range of complex scenarios, providing a challenging benchmark for CVGL. The framework trained with CV-Cities demonstrates high localization accuracy in various test cities, highlighting its strong globalization and generalization capabilities. Our datasets and codes are available at https://github.com/GaoShuang98/CVCities.
DINO-Mix: Enhancing Visual Place Recognition with Foundational Vision Model and Feature Mixing
Nov 01, 2023Utilizing visual place recognition (VPR) technology to ascertain the geographical location of publicly available images is a pressing issue for real-world VPR applications. Although most current VPR methods achieve favorable results under ideal conditions, their performance in complex environments, characterized by lighting variations, seasonal changes, and occlusions caused by moving objects, is generally unsatisfactory. In this study, we utilize the DINOv2 model as the backbone network for trimming and fine-tuning to extract robust image features. We propose a novel VPR architecture called DINO-Mix, which combines a foundational vision model with feature aggregation. This architecture relies on the powerful image feature extraction capabilities of foundational vision models. We employ an MLP-Mixer-based mix module to aggregate image features, resulting in globally robust and generalizable descriptors that enable high-precision VPR. We experimentally demonstrate that the proposed DINO-Mix architecture significantly outperforms current state-of-the-art (SOTA) methods. In test sets having lighting variations, seasonal changes, and occlusions (Tokyo24/7, Nordland, SF-XL-Testv1), our proposed DINO-Mix architecture achieved Top-1 accuracy rates of 91.75%, 80.18%, and 82%, respectively. Compared with SOTA methods, our architecture exhibited an average accuracy improvement of 5.14%.