 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Surrogates Learning and Spectral Tokens Pooling in Transformers for Few-shot Learning
Mar 17, 2022
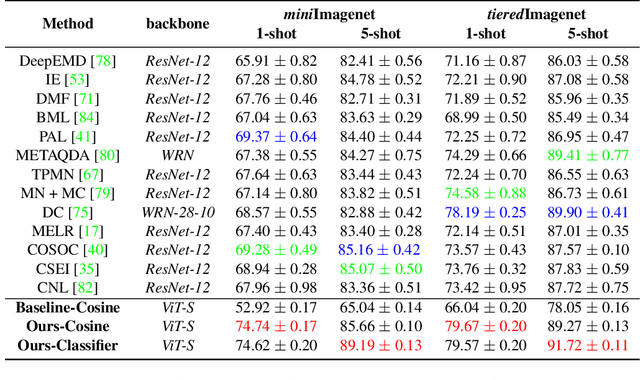
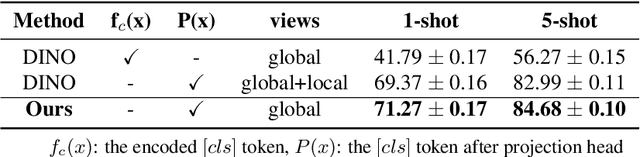

This paper presents new hierarchically cascaded transformers that can improve data efficiency through attribute surrogates learning and spectral tokens pooling. Vision transformers have recently been thought of as a promising alternative to convolutional neural networks for visual recognition. But when there is no sufficient data, it gets stuck in overfitting and shows inferior performance. To improve data efficiency, we propose hierarchically cascaded transformers that exploit intrinsic image structures through spectral tokens pooling and optimize the learnable parameters through latent attribute surrogates. The intrinsic image structure is utilized to reduce the ambiguity between foreground content and background noise by spectral tokens pooling. And the attribute surrogate learning scheme is designed to benefit from the rich visual information in image-label pairs instead of simple visual concepts assigned by their labels. Our Hierarchically Cascaded Transformers, called HCTransformers, is built upon a self-supervised learning framework DINO and is tested on several popular few-shot learning benchmarks. In the inductive setting, HCTransformers surpass the DINO baseline by a large margin of 9.7% 5-way 1-shot accuracy and 9.17% 5-way 5-shot accuracy on miniImageNet, which demonstrates HCTransformers are efficient to extract discriminative features. Also, HCTransformers show clear advantages over SOTA few-shot classification methods in both 5-way 1-shot and 5-way 5-shot settings on four popular benchmark datasets, including miniImageNet, tieredImageNet, FC100, and CIFAR-FS. The trained weights and codes are available at https://github.com/StomachCold/HCTransformers.
Multi-scale Matching Networks for Semantic Correspondence
Jul 31, 2021
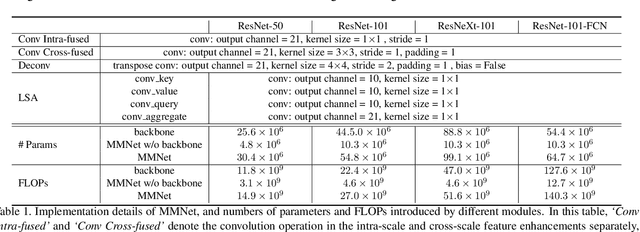

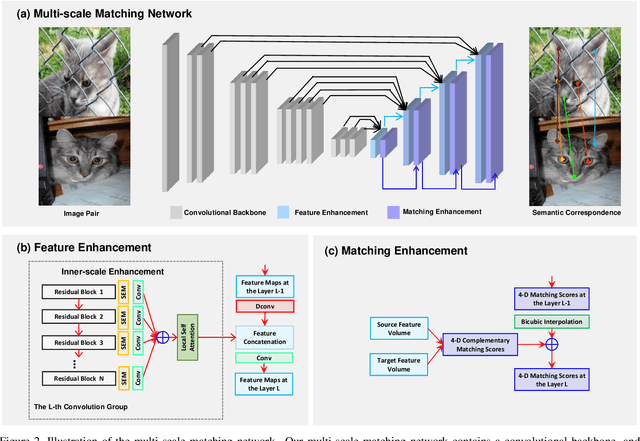
Deep features have been proven powerful in building accurate dense semantic correspondences in various previous works. However, the multi-scale and pyramidal hierarchy of convolutional neural networks has not been well studied to learn discriminative pixel-level features for semantic correspondence. In this paper, we propose a multi-scale matching network that is sensitive to tiny semantic differences between neighboring pixels. We follow the coarse-to-fine matching strategy and build a top-down feature and matching enhancement scheme that is coupled with the multi-scale hierarchy of deep convolutional neural networks. During feature enhancement, intra-scale enhancement fuses same-resolution feature maps from multiple layers together via local self-attention and cross-scale enhancement hallucinates higher-resolution feature maps along the top-down hierarchy. Besides, we learn complementary matching details at different scales thus the overall matching score is refined by features of different semantic levels gradually. Our multi-scale matching network can be trained end-to-end easily with few additional learnable parameters. Experimental results demonstrate that the proposed method achieves state-of-the-art performance on three popular benchmarks with high computational efficiency.
Deep Hierarchical Reinforcement Learning Based Recommendations via Multi-goals Abstraction
Mar 22, 2019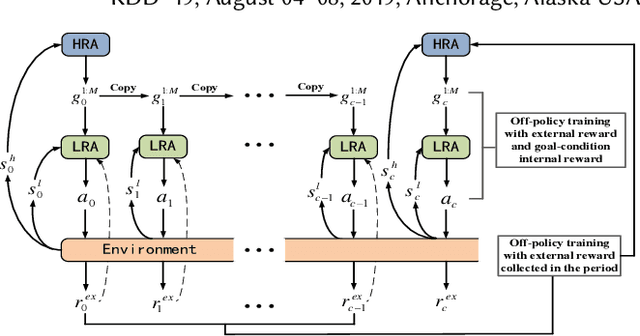


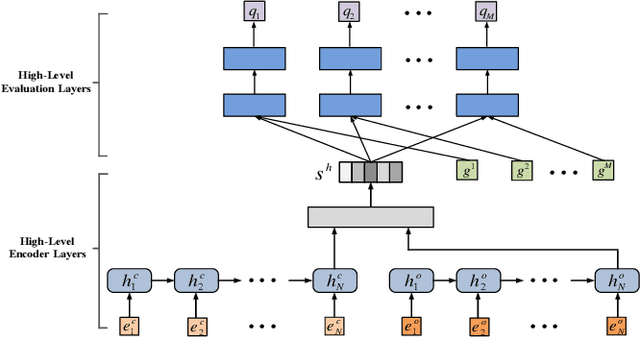
The recommender system is an important form of intelligent application, which assists users to alleviate from information redundancy. Among the metrics used to evaluate a recommender system, the metric of conversion has become more and more important. The majority of existing recommender systems perform poorly on the metric of conversion due to its extremely sparse feedback signal. To tackle this challenge, we propose a deep hierarchical reinforcement learning based recommendation framework, which consists of two components, i.e., high-level agent and low-level agent. The high-level agent catches long-term sparse conversion signals, and automatically sets abstract goals for low-level agent, while the low-level agent follows the abstract goals and interacts with real-time environment. To solve the inherent problem in hierarchical reinforcement learning, we propose a novel deep hierarchical reinforcement learning algorithm via multi-goals abstraction (HRL-MG). Our proposed algorithm contains three characteristics: 1) the high-level agent generates multiple goals to guide the low-level agent in different stages, which reduces the difficulty of approaching high-level goals; 2) different goals share the same state encoder parameters, which increases the update frequency of the high-level agent and thus accelerates the convergence of our proposed algorithm; 3) an appreciate benefit assignment function is designed to allocate rewards in each goal so as to coordinate different goals in a consistent direction. We evaluate our proposed algorithm based on a real-world e-commerce dataset and validate its effectiveness.