 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Surrogates Learning and Spectral Tokens Pooling in Transformers for Few-shot Learning
Paper and Code
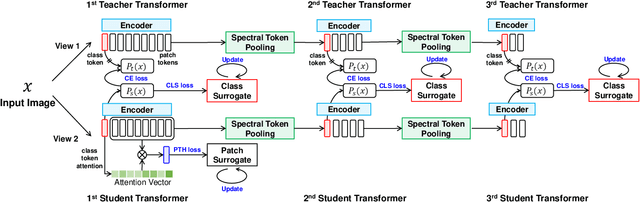
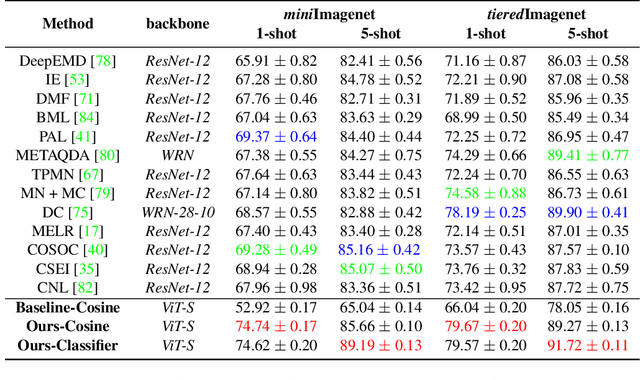
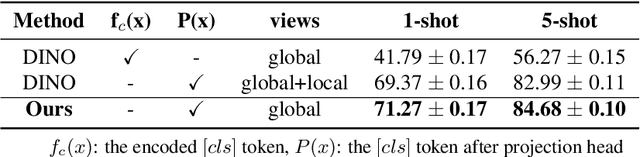

This paper presents new hierarchically cascaded transformers that can improve data efficiency through attribute surrogates learning and spectral tokens pooling. Vision transformers have recently been thought of as a promising alternative to convolutional neural networks for visual recognition. But when there is no sufficient data, it gets stuck in overfitting and shows inferior performance. To improve data efficiency, we propose hierarchically cascaded transformers that exploit intrinsic image structures through spectral tokens pooling and optimize the learnable parameters through latent attribute surrogates. The intrinsic image structure is utilized to reduce the ambiguity between foreground content and background noise by spectral tokens pooling. And the attribute surrogate learning scheme is designed to benefit from the rich visual information in image-label pairs instead of simple visual concepts assigned by their labels. Our Hierarchically Cascaded Transformers, called HCTransformers, is built upon a self-supervised learning framework DINO and is tested on several popular few-shot learning benchmarks. In the inductive setting, HCTransformers surpass the DINO baseline by a large margin of 9.7% 5-way 1-shot accuracy and 9.17% 5-way 5-shot accuracy on miniImageNet, which demonstrates HCTransformers are efficient to extract discriminative features. Also, HCTransformers show clear advantages over SOTA few-shot classification methods in both 5-way 1-shot and 5-way 5-shot settings on four popular benchmark datasets, including miniImageNet, tieredImageNet, FC100, and CIFAR-FS. The trained weights and codes are available at https://github.com/StomachCold/HCTransformers.