 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARPO: Token-Wise Latent-Explicit Reasoning via Action-Routing Policy Optimization
Jun 04, 2026Latent reasoning has emerged as a promising alternative to discrete Chain-of-Thought (CoT) in large language models (LLMs), enabling more expressive reasoning by operating over continuous representations. However, the inherently deterministic nature of continuous representations limits policy exploration in reinforcement learning (RL). To address this, we propose TARPO (Token-Wise Latent-Explicit Reasoning via Action-Routing Policy Optimization), a pure RL framework that adaptively switches between discrete token generation and continuous latent reasoning at each step. TARPO introduces a lightweight action head router that observes the current hidden state and samples a routing decision from a binary mode-selection space, preserving the stochasticity of discrete token sampling from the vocabulary. The LLM backbone and router are jointly optimized end-to-end with a shared group-relative advantage signal. Extensive experiments across Qwen2.5 (from 1.5B to 7B) and Llama-3.1-8B backbones demonstrate that TARPO consistently outperforms existing explicit and latent reasoning RL baselines across diverse benchmarks. Further analysis shows that TARPO learns adaptive token-wise switching behaviors while maintaining stable training dynamics. Our code is available at https://github.com/NKU-LITI/TARPO-master.
Large Language Model Post-Training: A Unified View of Off-Policy and On-Policy Learning
Apr 09, 2026Post-training has become central to turning pretrained large language models (LLMs) into aligned and deployable systems. Recent progress spans supervised fine-tuning (SFT), preference optimization, reinforcement learning (RL), process supervision, verifier-guided methods, distillation, and multi-stage pipelines. Yet these methods are often discussed in fragmented ways, organized by labels or objective families rather than by the behavioral bottlenecks they address. This survey argues that LLM post-training is best understood as structured intervention on model behavior. We organize the field first by trajectory provenance, which defines two primary learning regimes: off-policy learning on externally supplied trajectories, and on-policy learning on learner-generated rollouts. We then interpret methods through two recurring roles -- effective support expansion, which makes useful behaviors more reachable, and policy reshaping, which improves behavior within already reachable regions -- together with a complementary systems-level role, behavioral consolidation, which preserves, transfers, and amortizes behavior across stages and model transitions. This perspective yields a unified reading of major paradigms. SFT may serve either support expansion or policy reshaping, whereas preference-based methods are usually off-policy reshaping. On-policy RL often improves behavior on learner-generated states, though under stronger guidance it can also make hard-to-reach reasoning paths reachable. Distillation is often best understood as consolidation rather than only compression, and hybrid pipelines emerge as coordinated multi-stage compositions. Overall, the framework helps diagnose post-training bottlenecks and reason about stage composition, suggesting that progress in LLM post-training increasingly depends on coordinated system design rather than any single dominant objective.
Wavelet Transform-assisted Adaptive Generative Modeling for Colorization
Jul 09, 2021


Unsupervised deep learning has recently demonstrated the promise to produce high-quality samples. While it has tremendous potential to promote the image colorization task, the performance is limited owing to the manifold hypothesis in machine learning. This study presents a novel scheme that exploiting the score-based generative model in wavelet domain to address the issue. By taking advantage of the multi-scale and multi-channel representation via wavelet transform, the proposed model learns the priors from stacked wavelet coefficient components, thus learns the image characteristics under coarse and detail frequency spectrums jointly and effectively. Moreover, such a highly flexible generative model without adversarial optimization can execute colorization tasks better under dual consistency terms in wavelet domain, namely data-consistency and structure-consistency. Specifically, in the training phase, a set of multi-channel tensors consisting of wavelet coefficients are used as the input to train the network by denoising score matching. In the test phase, samples are iteratively generated via annealed Langevin dynamics with data and structure consistencies. Experiments demonstrated remarkable improvements of the proposed model on colorization quality, particularly on colorization robustness and diversity.
A Local Similarity-Preserving Framework for Nonlinear Dimensionality Reduction with Neural Networks
Mar 10, 2021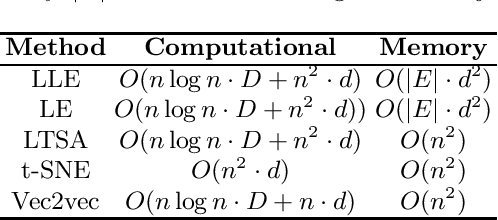
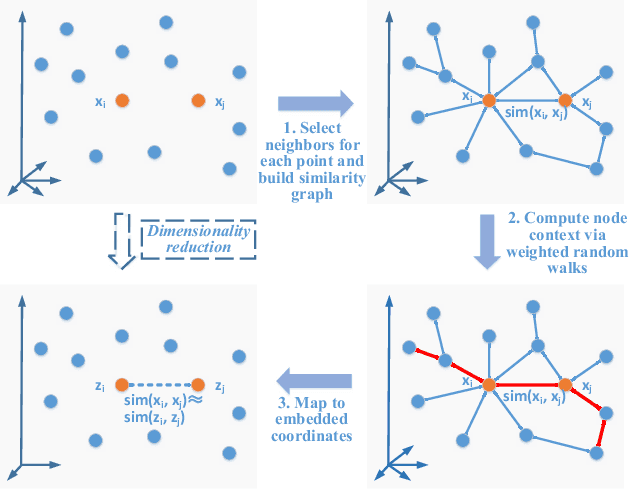
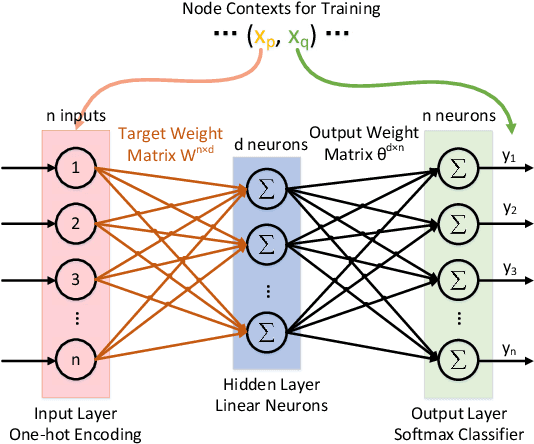
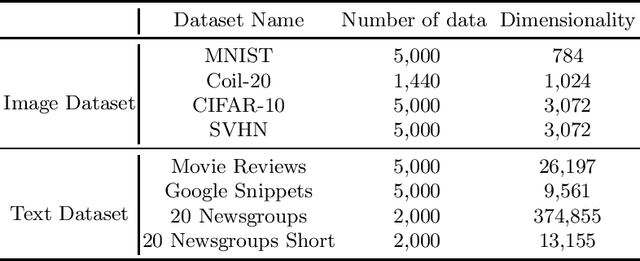
Real-world data usually have high dimensionality and it is important to mitigate the curse of dimensionality. High-dimensional data are usually in a coherent structure and make the data in relatively small true degrees of freedom. There are global and local dimensionality reduction methods to alleviate the problem. Most of existing methods for local dimensionality reduction obtain an embedding with the eigenvalue or singular value decomposition, where the computational complexities are very high for a large amount of data. Here we propose a novel local nonlinear approach named Vec2vec for general purpose dimensionality reduction, which generalizes recent advancements in embedding representation learning of words to dimensionality reduction of matrices. It obtains the nonlinear embedding using a neural network with only one hidden layer to reduce the computational complexity. To train the neural network, we build the neighborhood similarity graph of a matrix and define the context of data points by exploiting the random walk properties. Experiments demenstrate that Vec2vec is more efficient than several state-of-the-art local dimensionality reduction methods in a large number of high-dimensional data. Extensive experiments of data classification and clustering on eight real datasets show that Vec2vec is better than several classical dimensionality reduction methods in the statistical hypothesis test, and it is competitive with recently developed state-of-the-art UMAP.
DEAL: Decremental Energy-Aware Learning in a Federated System
Feb 05, 2021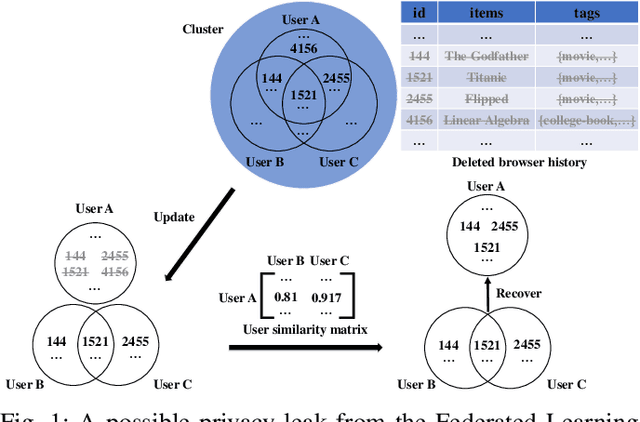
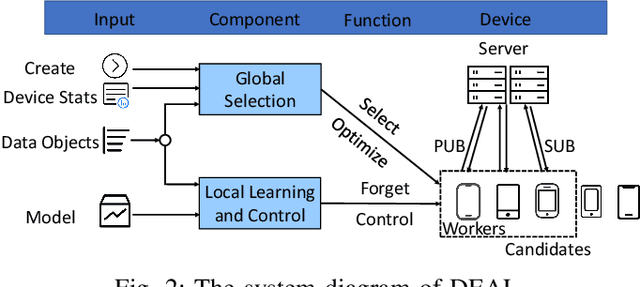
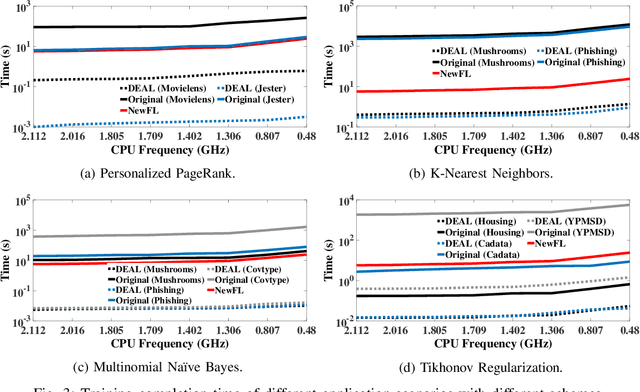
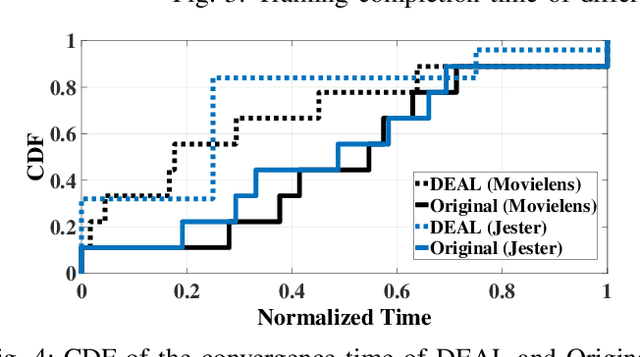
Federated learning struggles with their heavy energy footprint on battery-powered devices. The learning process keeps all devices awake while draining expensive battery power to train a shared model collaboratively, yet it may still leak sensitive personal information. Traditional energy management techniques in system kernel mode can force the training device entering low power states, but it may violate the SLO of the collaborative learning. To address the conflict between learning SLO and energy efficiency, we propose DEAL, an energy efficient learning system that saves energy and preserves privacy with a decremental learning design. DEAL reduces the energy footprint from two layers: 1) an optimization layer that selects a subset of workers with sufficient capacity and maximum rewards. 2) a specified decremental learning algorithm that actively provides a decremental and incremental update functions, which allows kernel to correctly tune the local DVFS. We prototyped DEAL in containerized services with modern smartphone profiles and evaluated it with several learning benchmarks with realistic traces. We observed that DEAL achieves 75.6%-82.4% less energy footprint in different datasets, compared to the traditional methods. All learning processes are faster than state-of-the-practice FL frameworks up to 2-4X in model convergence.