 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClickVOS: Click Video Object Segmentation
Paper and Code

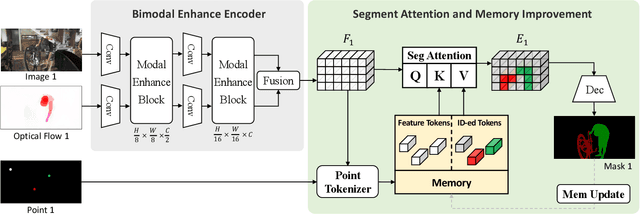


Video Object Segmentation (VOS) task aims to segment objects in videos. However, previous settings either require time-consuming manual masks of target objects at the first frame during inference or lack the flexibility to specify arbitrary objects of interest. To address these limitations, we propose the setting named Click Video Object Segmentation (ClickVOS) which segments objects of interest across the whole video according to a single click per object in the first frame. And we provide the extended datasets DAVIS-P and YouTubeVOSP that with point annotations to support this task. ClickVOS is of significant practical applications and research implications due to its only 1-2 seconds interaction time for indicating an object, comparing annotating the mask of an object needs several minutes. However, ClickVOS also presents increased challenges. To address this task, we propose an end-to-end baseline approach named called Attention Before Segmentation (ABS), motivated by the attention process of humans. ABS utilizes the given point in the first frame to perceive the target object through a concise yet effective segmentation attention. Although the initial object mask is possibly inaccurate, in our ABS, as the video goes on, the initially imprecise object mask can self-heal instead of deteriorating due to error accumulation, which is attributed to our designed improvement memory that continuously records stable global object memory and updates detailed dense memory. In addition, we conduct various baseline explorations utilizing off-the-shelf algorithms from related fields, which could provide insights for the further exploration of ClickVOS. The experimental results demonstrate the superiority of the proposed ABS approach. Extended datasets and codes will be available at https://github.com/PinxueGuo/ClickVOS.