 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Saliency Guided Trunk-Collateral Network for Unsupervised Video Object Segmentation
Apr 08, 2025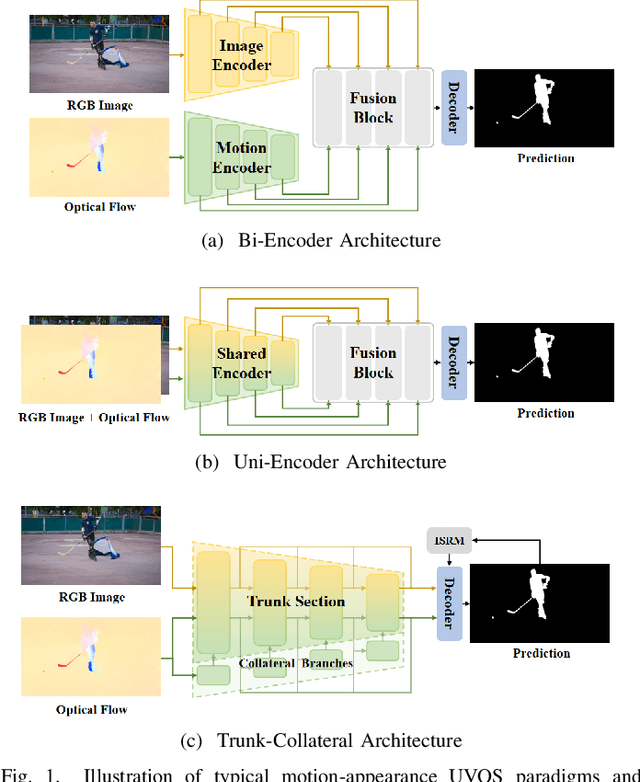

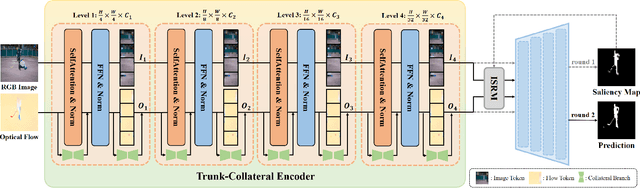
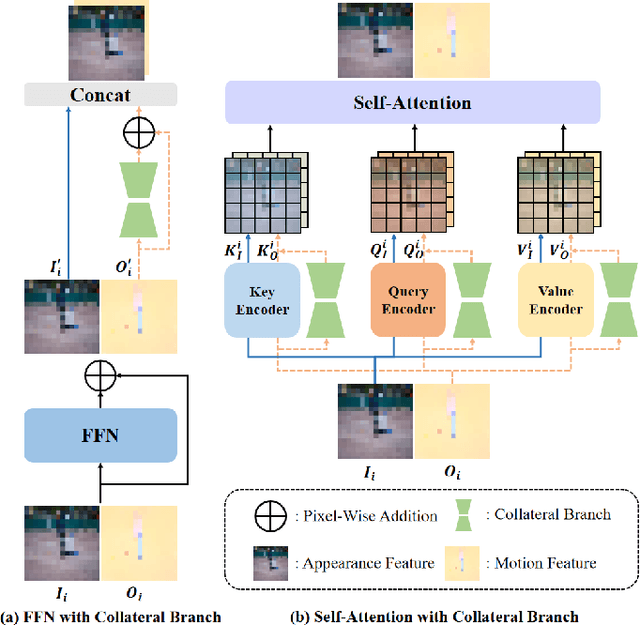
Recent unsupervised video object segmentation (UVOS) methods predominantly adopt the motion-appearance paradigm. Mainstream motion-appearance approaches use either the two-encoder structure to separately encode motion and appearance features, or the single-encoder structure for joint encoding. However, these methods fail to properly balance the motion-appearance relationship. Consequently, even with complex fusion modules for motion-appearance integration, the extracted suboptimal features degrade the models' overall performance. Moreover, the quality of optical flow varies across scenarios, making it insufficient to rely solely on optical flow to achieve high-quality segmentation results. To address these challenges, we propose the Intrinsic Saliency guided Trunk-Collateral Net}work (ISTC-Net), which better balances the motion-appearance relationship and incorporates model's intrinsic saliency information to enhance segmentation performance. Specifically, considering that optical flow maps are derived from RGB images, they share both commonalities and differences. We propose a novel Trunk-Collateral structure. The shared trunk backbone captures the motion-appearance commonality, while the collateral branch learns the uniqueness of motion features. Furthermore, an Intrinsic Saliency guided Refinement Module (ISRM) is devised to efficiently leverage the model's intrinsic saliency information to refine high-level features, and provide pixel-level guidance for motion-appearance fusion, thereby enhancing performance without additional input. Experimental results show that ISTC-Net achieved state-of-the-art performance on three UVOS datasets (89.2% J&F on DAVIS-16, 76% J on YouTube-Objects, 86.4% J on FBMS) and four standard video salient object detection (VSOD) benchmarks with the notable increase, demonstrating its effectiveness and superiority over previous methods.