 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe GAN is dead; long live the GAN! A Modern GAN Baseline
Jan 09, 2025
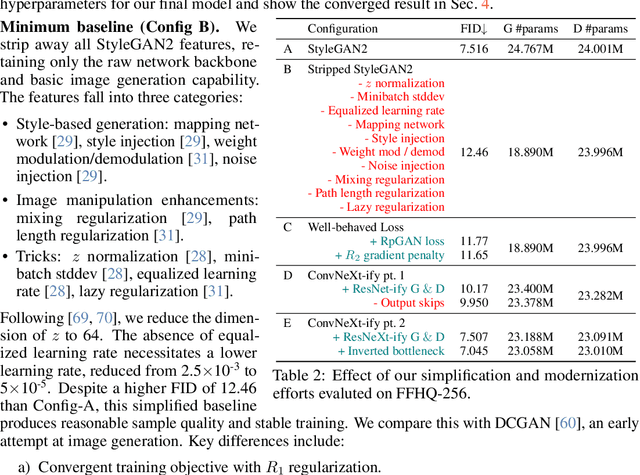


There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, our new loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline -- R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models.
Hierarchical Visual Categories Modeling: A Joint Representation Learning and Density Estimation Framework for Out-of-Distribution Detection
Aug 28, 2024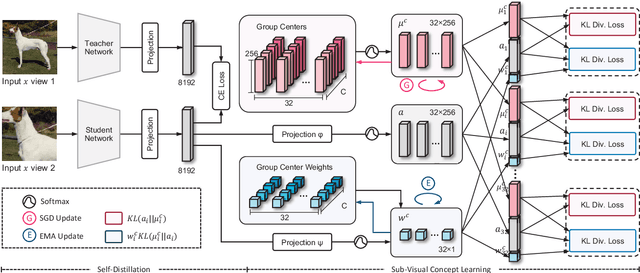
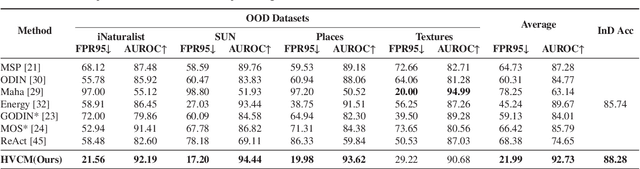
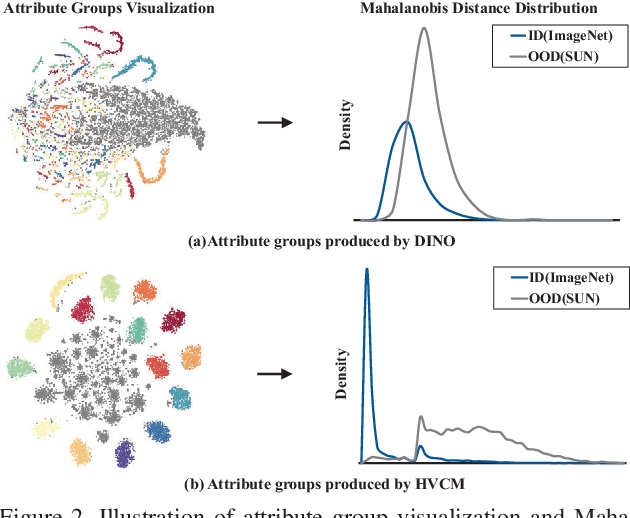
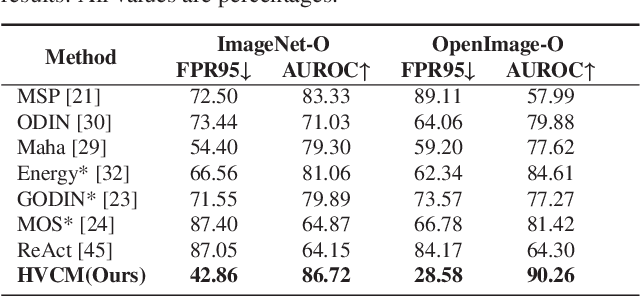
Detecting out-of-distribution inputs for visual recognition models has become critical in safe deep learning. This paper proposes a novel hierarchical visual category modeling scheme to separate out-of-distribution data from in-distribution data through joint representation learning and statistical modeling. We learn a mixture of Gaussian models for each in-distribution category. There are many Gaussian mixture models to model different visual categories. With these Gaussian models, we design an in-distribution score function by aggregating multiple Mahalanobis-based metrics. We don't use any auxiliary outlier data as training samples, which may hurt the generalization ability of out-of-distribution detection algorithms. We split the ImageNet-1k dataset into ten folds randomly. We use one fold as the in-distribution dataset and the others as out-of-distribution datasets to evaluate the proposed method. We also conduct experiments on seven popular benchmarks, including CIFAR, iNaturalist, SUN, Places, Textures, ImageNet-O, and OpenImage-O. Extensive experiments indicate that the proposed method outperforms state-of-the-art algorithms clearly. Meanwhile, we find that our visual representation has a competitive performance when compared with features learned by classical methods. These results demonstrate that the proposed method hasn't weakened the discriminative ability of visual recognition models and keeps high efficiency in detecting out-of-distribution samples.
FormalGeo: The First Step Toward Human-like IMO-level Geometric Automated Reasoning
Oct 30, 2023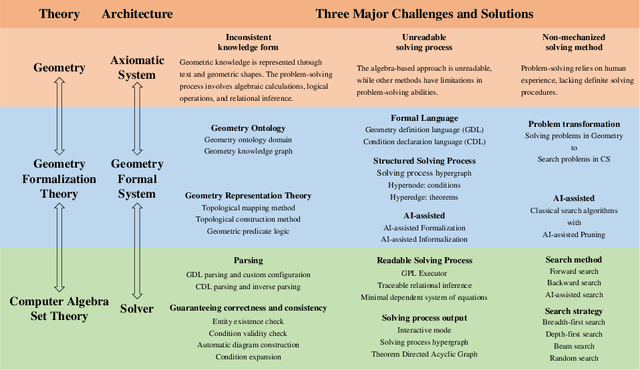
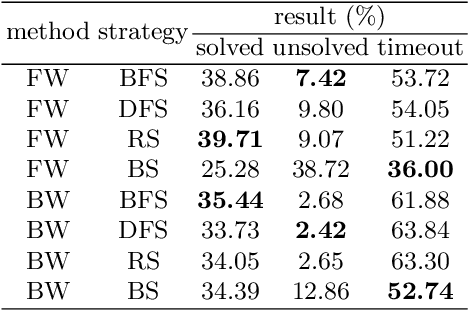
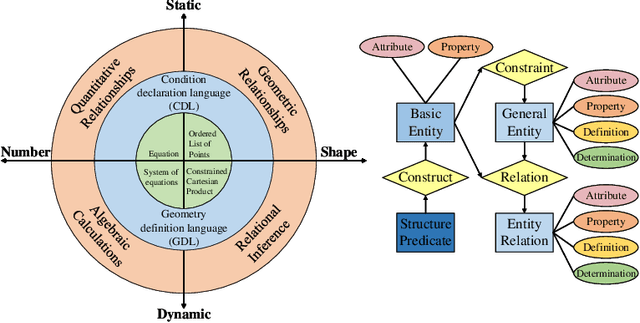
This is the first paper in a series of work we have accomplished over the past three years. In this paper, we have constructed a complete and compatible formal plane geometry system. This will serve as a crucial bridge between IMO-level plane geometry challenges and readable AI automated reasoning. With this formal system in place, we have been able to seamlessly integrate modern AI models with our formal system. Within this formal framework, AI is now capable of providing deductive reasoning solutions to IMO-level plane geometry problems, just like handling other natural languages, and these proofs are readable, traceable, and verifiable. We propose the geometry formalization theory (GFT) to guide the development of the geometry formal system. Based on the GFT, we have established the FormalGeo, which consists of 88 geometric predicates and 196 theorems. It can represent, validate, and solve IMO-level geometry problems. we also have crafted the FGPS (formal geometry problem solver) in Python. It serves as both an interactive assistant for verifying problem-solving processes and an automated problem solver, utilizing various methods such as forward search, backward search and AI-assisted search. We've annotated the FormalGeo7k dataset, containing 6,981 (expand to 186,832 through data augmentation) geometry problems with complete formal language annotations. Implementation of the formal system and experiments on the FormalGeo7k validate the correctness and utility of the GFT. The backward depth-first search method only yields a 2.42% problem-solving failure rate, and we can incorporate deep learning techniques to achieve lower one. The source code of FGPS and FormalGeo7k dataset are available at https://github.com/BitSecret/FormalGeo.
'Tax-free' 3DMM Conditional Face Generation
May 22, 2023



3DMM conditioned face generation has gained traction due to its well-defined controllability; however, the trade-off is lower sample quality: Previous works such as DiscoFaceGAN and 3D-FM GAN show a significant FID gap compared to the unconditional StyleGAN, suggesting that there is a quality tax to pay for controllability. In this paper, we challenge the assumption that quality and controllability cannot coexist. To pinpoint the previous issues, we mathematically formalize the problem of 3DMM conditioned face generation. Then, we devise simple solutions to the problem under our proposed framework. This results in a new model that effectively removes the quality tax between 3DMM conditioned face GANs and the unconditional StyleGAN.
FERV39k: A Large-Scale Multi-Scene Dataset for Facial Expression Recognition in Videos
Mar 20, 2022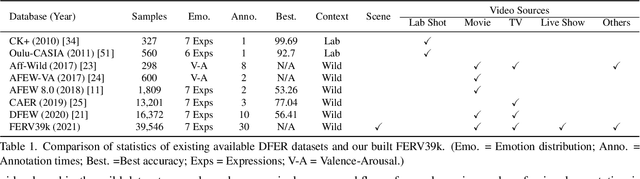
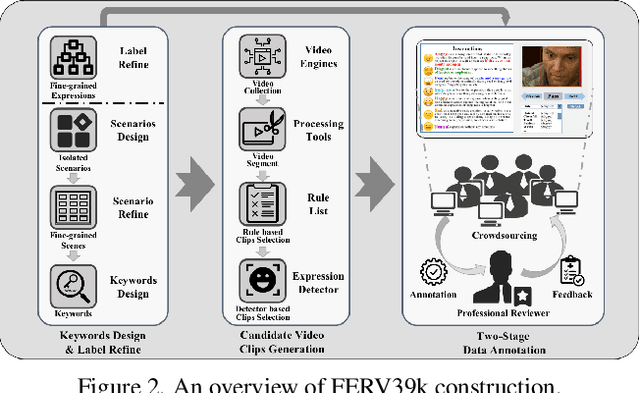
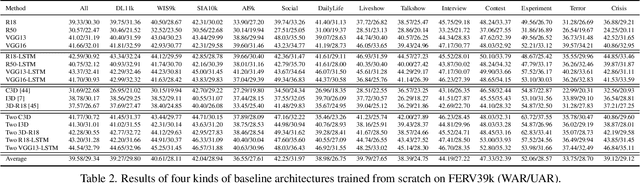
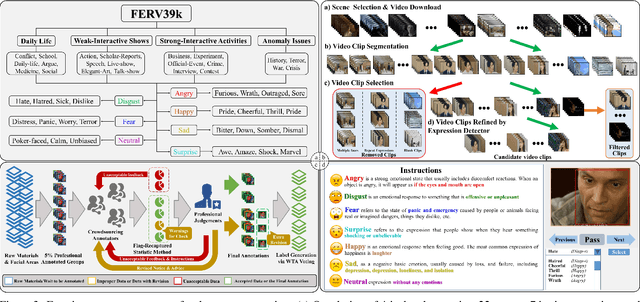
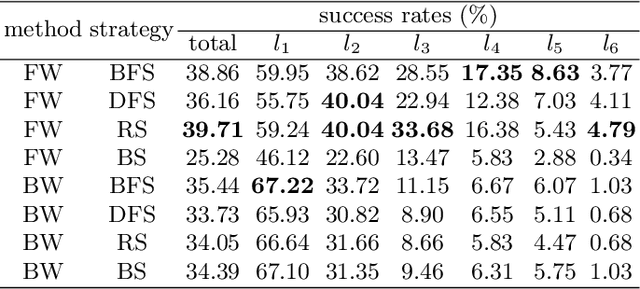
Current benchmarks for facial expression recognition (FER) mainly focus on static images, while there are limited datasets for FER in videos. It is still ambiguous to evaluate whether performances of existing methods remain satisfactory in real-world application-oriented scenes. For example, the "Happy" expression with high intensity in Talk-Show is more discriminating than the same expression with low intensity in Official-Event. To fill this gap, we build a large-scale multi-scene dataset, coined as FERV39k. We analyze the important ingredients of constructing such a novel dataset in three aspects: (1) multi-scene hierarchy and expression class, (2) generation of candidate video clips, (3) trusted manual labelling process. Based on these guidelines, we select 4 scenarios subdivided into 22 scenes, annotate 86k samples automatically obtained from 4k videos based on the well-designed workflow, and finally build 38,935 video clips labeled with 7 classic expressions. Experiment benchmarks on four kinds of baseline frameworks were also provided and further analysis on their performance across different scenes and some challenges for future research were given. Besides, we systematically investigate key components of DFER by ablation studies. The baseline framework and our project will be available.
Machine-learning non-stationary noise out of gravitational wave detectors
Jan 10, 2020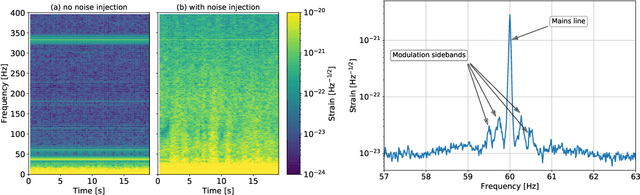

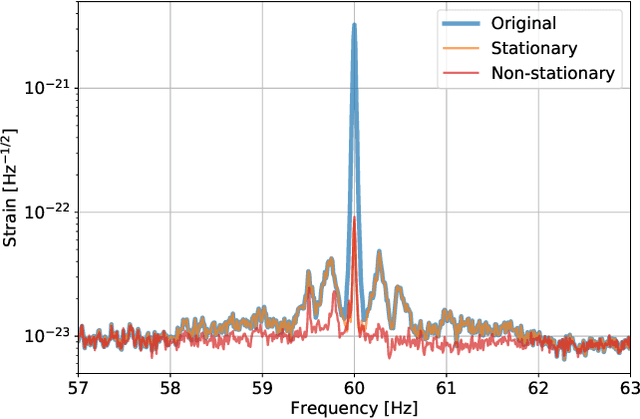

Signal extraction out of background noise is a common challenge in high precision physics experiments, where the measurement output is often a continuous data stream. To improve the signal to noise ratio of the detection, witness sensors are often used to independently measure background noises and subtract them from the main signal. If the noise coupling is linear and stationary, optimal techniques already exist and are routinely implemented in many experiments. However, when the noise coupling is non-stationary, linear techniques often fail or are sub-optimal. Inspired by the properties of the background noise in gravitational wave detectors, this work develops a novel algorithm to efficiently characterize and remove non-stationary noise couplings, provided there exist witnesses of the noise source and of the modulation. In this work, the algorithm is described in its most general formulation, and its efficiency is demonstrated with examples from the data of the Advanced LIGO gravitational wave observatory, where we could obtain an improvement of the detector gravitational wave reach without introducing any bias on the source parameter estimation.
A Fully Sequential Methodology for Convolutional Neural Networks
Nov 27, 2018
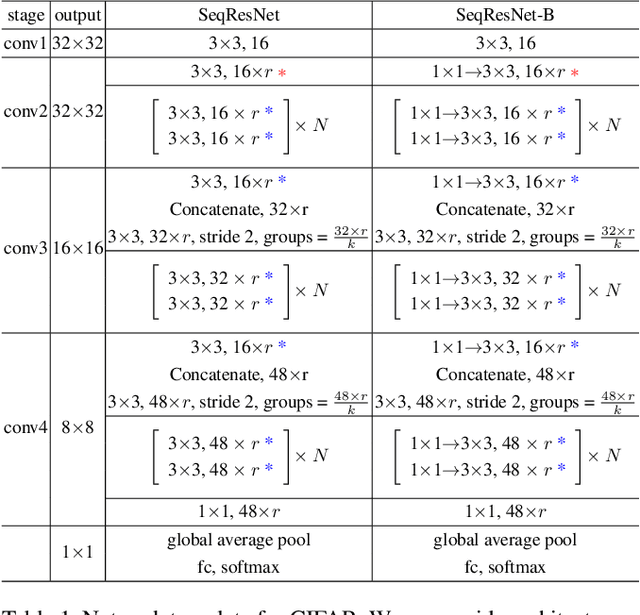


Recent work has shown that the performance of convolutional neural networks could be significantly improved by increasing the depth of the representation. We propose a fully sequential methodology to construct and train extremely deep convolutional neural networks. We first introduce a novel sequential convolutional layer to construct the network. The proposed layer is capable of constructing trainable and highly efficient feedforward networks that consist of thousands of vanilla convolutional layers with rather limited number of parameters. The layer extracts each feature of the produced representation in sequence, allowing feature reuse within the layer. This form of feature reuse introduces in-layer hierarchy to the extracted features which greatly increases the depth of the representation, enabling richer structures to be explored. Furthermore, we employ the progressive growing training method to optimize each module of the network in sequence. This training manner progressively increases the network capacity allowing later modules to be optimized conditioning on prior knowledge from earlier modules. Thus, it encourages long term dependency to be established among each module of the network, which increases the effective depth of networks with skip connections, as well alleviates multiple optimization difficulties for deep networks.
Densely Connected High Order Residual Network for Single Frame Image Super Resolution
Apr 16, 2018


Deep convolutional neural networks (DCNN) have been widely adopted for research on super resolution recently, however previous work focused mainly on stacking as many layers as possible in their model, in this paper, we present a new perspective regarding to image restoration problems that we can construct the neural network model reflecting the physical significance of the image restoration process, that is, embedding the a priori knowledge of image restoration directly into the structure of our neural network model, we employed a symmetric non-linear colorspace, the sigmoidal transfer, to replace traditional transfers such as, sRGB, Rec.709, which are asymmetric non-linear colorspaces, we also propose a "reuse plus patch" method to deal with super resolution of different scaling factors, our proposed methods and model show generally superior performance over previous work even though our model was only roughly trained and could still be underfitting the training set.
Using Kernel Methods and Model Selection for Prediction of Preterm Birth
Sep 05, 2016

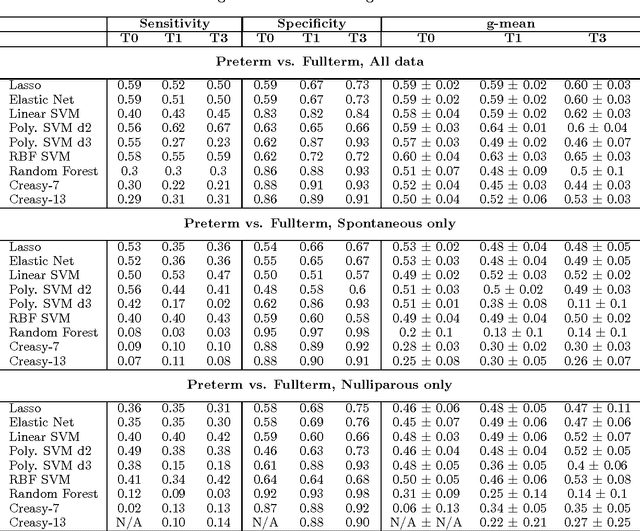
We describe an application of machine learning to the problem of predicting preterm birth. We conduct a secondary analysis on a clinical trial dataset collected by the National In- stitute of Child Health and Human Development (NICHD) while focusing our attention on predicting different classes of preterm birth. We compare three approaches for deriving predictive models: a support vector machine (SVM) approach with linear and non-linear kernels, logistic regression with different model selection along with a model based on decision rules prescribed by physician experts for prediction of preterm birth. Our approach highlights the pre-processing methods applied to handle the inherent dynamics, noise and gaps in the data and describe techniques used to handle skewed class distributions. Empirical experiments demonstrate significant improvement in predicting preterm birth compared to past work.