 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructBioMol: Advancing Biomolecule Understanding and Design Following Human Instructions
Oct 10, 2024Understanding and designing biomolecules, such as proteins and small molecules, is central to advancing drug discovery, synthetic biology, and enzyme engineering. Recent breakthroughs in Artificial Intelligence (AI) have revolutionized biomolecular research, achieving remarkable accuracy in biomolecular prediction and design. However, a critical gap remains between AI's computational power and researchers' intuition, using natural language to align molecular complexity with human intentions. Large Language Models (LLMs) have shown potential to interpret human intentions, yet their application to biomolecular research remains nascent due to challenges including specialized knowledge requirements, multimodal data integration, and semantic alignment between natural language and biomolecules. To address these limitations, we present InstructBioMol, a novel LLM designed to bridge natural language and biomolecules through a comprehensive any-to-any alignment of natural language, molecules, and proteins. This model can integrate multimodal biomolecules as input, and enable researchers to articulate design goals in natural language, providing biomolecular outputs that meet precise biological needs. Experimental results demonstrate InstructBioMol can understand and design biomolecules following human instructions. Notably, it can generate drug molecules with a 10% improvement in binding affinity and design enzymes that achieve an ESP Score of 70.4, making it the only method to surpass the enzyme-substrate interaction threshold of 60.0 recommended by the ESP developer. This highlights its potential to transform real-world biomolecular research.
SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
Jun 13, 2024The burgeoning utilization of Large Language Models (LLMs) in scientific research necessitates advanced benchmarks capable of evaluating their understanding and application of scientific knowledge comprehensively. To address this need, we introduce the SciKnowEval benchmark, a novel framework that systematically evaluates LLMs across five progressive levels of scientific knowledge: studying extensively, inquiring earnestly, thinking profoundly, discerning clearly, and practicing assiduously. These levels aim to assess the breadth and depth of scientific knowledge in LLMs, including knowledge coverage, inquiry and exploration capabilities, reflection and reasoning abilities, ethic and safety considerations, as well as practice proficiency. Specifically, we take biology and chemistry as the two instances of SciKnowEval and construct a dataset encompassing 50K multi-level scientific problems and solutions. By leveraging this dataset, we benchmark 20 leading open-source and proprietary LLMs using zero-shot and few-shot prompting strategies. The results reveal that despite achieving state-of-the-art performance, the proprietary LLMs still have considerable room for improvement, particularly in addressing scientific computations and applications. We anticipate that SciKnowEval will establish a comprehensive standard for benchmarking LLMs in science research and discovery, and promote the development of LLMs that integrate scientific knowledge with strong safety awareness. The dataset and code are publicly available at https://github.com/hicai-zju/sciknoweval .
Scientific Large Language Models: A Survey on Biological & Chemical Domains
Jan 26, 2024
Large Language Models (LLMs) have emerged as a transformative power in enhancing natural language comprehension, representing a significant stride toward artificial general intelligence. The application of LLMs extends beyond conventional linguistic boundaries, encompassing specialized linguistic systems developed within various scientific disciplines. This growing interest has led to the advent of scientific LLMs, a novel subclass specifically engineered for facilitating scientific discovery. As a burgeoning area in the community of AI for Science, scientific LLMs warrant comprehensive exploration. However, a systematic and up-to-date survey introducing them is currently lacking. In this paper, we endeavor to methodically delineate the concept of "scientific language", whilst providing a thorough review of the latest advancements in scientific LLMs. Given the expansive realm of scientific disciplines, our analysis adopts a focused lens, concentrating on the biological and chemical domains. This includes an in-depth examination of LLMs for textual knowledge, small molecules, macromolecular proteins, genomic sequences, and their combinations, analyzing them in terms of model architectures, capabilities, datasets, and evaluation. Finally, we critically examine the prevailing challenges and point out promising research directions along with the advances of LLMs. By offering a comprehensive overview of technical developments in this field, this survey aspires to be an invaluable resource for researchers navigating the intricate landscape of scientific LLMs.
InstructProtein: Aligning Human and Protein Language via Knowledge Instruction
Oct 05, 2023Large Language Models (LLMs) have revolutionized the field of natural language processing, but they fall short in comprehending biological sequences such as proteins. To address this challenge, we propose InstructProtein, an innovative LLM that possesses bidirectional generation capabilities in both human and protein languages: (i) taking a protein sequence as input to predict its textual function description and (ii) using natural language to prompt protein sequence generation. To achieve this, we first pre-train an LLM on both protein and natural language corpora, enabling it to comprehend individual languages. Then supervised instruction tuning is employed to facilitate the alignment of these two distinct languages. Herein, we introduce a knowledge graph-based instruction generation framework to construct a high-quality instruction dataset, addressing annotation imbalance and instruction deficits in existing protein-text corpus. In particular, the instructions inherit the structural relations between proteins and function annotations in knowledge graphs, which empowers our model to engage in the causal modeling of protein functions, akin to the chain-of-thought processes in natural languages. Extensive experiments on bidirectional protein-text generation tasks show that InstructProtein outperforms state-of-the-art LLMs by large margins. Moreover, InstructProtein serves as a pioneering step towards text-based protein function prediction and sequence design, effectively bridging the gap between protein and human language understanding.
Molecular Contrastive Learning with Chemical Element Knowledge Graph
Dec 01, 2021
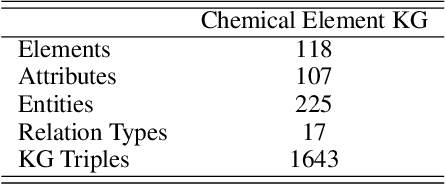
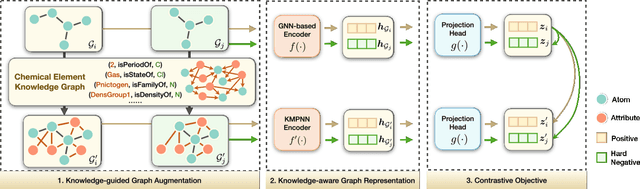
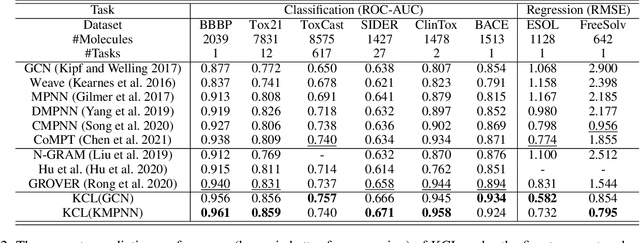
Molecular representation learning contributes to multiple downstream tasks such as molecular property prediction and drug design. To properly represent molecules, graph contrastive learning is a promising paradigm as it utilizes self-supervision signals and has no requirements for human annotations. However, prior works fail to incorporate fundamental domain knowledge into graph semantics and thus ignore the correlations between atoms that have common attributes but are not directly connected by bonds. To address these issues, we construct a Chemical Element Knowledge Graph (KG) to summarize microscopic associations between elements and propose a novel Knowledge-enhanced Contrastive Learning (KCL) framework for molecular representation learning. KCL framework consists of three modules. The first module, knowledge-guided graph augmentation, augments the original molecular graph based on the Chemical Element KG. The second module, knowledge-aware graph representation, extracts molecular representations with a common graph encoder for the original molecular graph and a Knowledge-aware Message Passing Neural Network (KMPNN) to encode complex information in the augmented molecular graph. The final module is a contrastive objective, where we maximize agreement between these two views of molecular graphs. Extensive experiments demonstrated that KCL obtained superior performances against state-of-the-art baselines on eight molecular datasets. Visualization experiments properly interpret what KCL has learned from atoms and attributes in the augmented molecular graphs. Our codes and data are available in supplementary materials.
Densely Connected High Order Residual Network for Single Frame Image Super Resolution
Apr 16, 2018
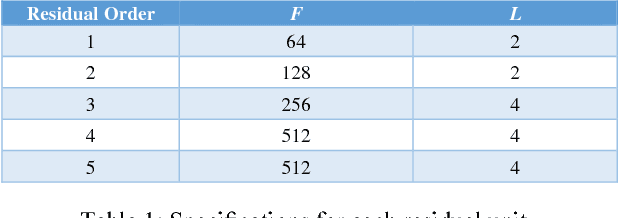


Deep convolutional neural networks (DCNN) have been widely adopted for research on super resolution recently, however previous work focused mainly on stacking as many layers as possible in their model, in this paper, we present a new perspective regarding to image restoration problems that we can construct the neural network model reflecting the physical significance of the image restoration process, that is, embedding the a priori knowledge of image restoration directly into the structure of our neural network model, we employed a symmetric non-linear colorspace, the sigmoidal transfer, to replace traditional transfers such as, sRGB, Rec.709, which are asymmetric non-linear colorspaces, we also propose a "reuse plus patch" method to deal with super resolution of different scaling factors, our proposed methods and model show generally superior performance over previous work even though our model was only roughly trained and could still be underfitting the training set.