 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Framework for Evaluating Semantic Preservation Using Hugging Face
Dec 08, 2025



As machine learning (ML) becomes an integral part of high-autonomy systems, it is critical to ensure the trustworthiness of learning-enabled software systems (LESS). Yet, the nondeterministic and run-time-defined semantics of ML complicate traditional software refactoring. We define semantic preservation in LESS as the property that optimizations of intelligent components do not alter the system's overall functional behavior. This paper introduces an empirical framework to evaluate semantic preservation in LESS by mining model evolution data from HuggingFace. We extract commit histories, $\textit{Model Cards}$, and performance metrics from a large number of models. To establish baselines, we conducted case studies in three domains, tracing performance changes across versions. Our analysis demonstrates how $\textit{semantic drift}$ can be detected via evaluation metrics across commits and reveals common refactoring patterns based on commit message analysis. Although API constraints limited the possibility of estimating a full-scale threshold, our pipeline offers a foundation for defining community-accepted boundaries for semantic preservation. Our contributions include: (1) a large-scale dataset of ML model evolution, curated from 1.7 million Hugging Face entries via a reproducible pipeline using the native HF hub API, (2) a practical pipeline for the evaluation of semantic preservation for a subset of 536 models and 4000+ metrics and (3) empirical case studies illustrating semantic drift in practice. Together, these contributions advance the foundations for more maintainable and trustworthy ML systems.
Safe Automated Refactoring for Efficient Migration of Imperative Deep Learning Programs to Graph Execution
Apr 07, 2025Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code -- supporting symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, imperative DL frameworks encouraging eager execution have emerged at the expense of run-time performance. Though hybrid approaches aim for the "best of both worlds," using them effectively requires subtle considerations to make code amenable to safe, accurate, and efficient graph execution. We present an automated refactoring approach that assists developers in specifying whether their otherwise eagerly-executed imperative DL code could be reliably and efficiently executed as graphs while preserving semantics. The approach, based on a novel imperative tensor analysis, automatically determines when it is safe and potentially advantageous to migrate imperative DL code to graph execution. The approach is implemented as a PyDev Eclipse IDE plug-in that integrates the WALA Ariadne analysis framework and evaluated on 19 Python projects consisting of 132.05 KLOC. We found that 326 of 766 candidate functions (42.56%) were refactorable, and an average speedup of 2.16 on performance tests was observed. The results indicate that the approach is useful in optimizing imperative DL code to its full potential.
Handling Uncertainty in Health Data using Generative Algorithms
Mar 05, 2025
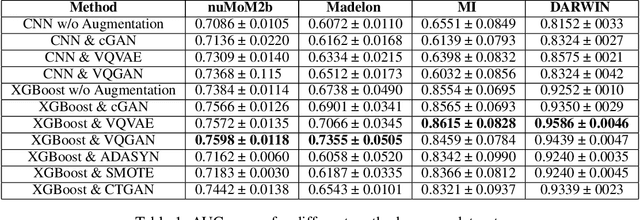


Understanding and managing uncertainty is crucial in machine learning, especially in high-stakes domains like healthcare, where class imbalance can impact predictions. This paper introduces RIGA, a novel pipeline that mitigates class imbalance using generative AI. By converting tabular healthcare data into images, RIGA leverages models like cGAN, VQVAE, and VQGAN to generate balanced samples, improving classification performance. These representations are processed by CNNs and later transformed back into tabular format for seamless integration. This approach enhances traditional classifiers like XGBoost, improves Bayesian structure learning, and strengthens ML model robustness by generating realistic synthetic data for underrepresented classes.
M-DEW: Extending Dynamic Ensemble Weighting to Handle Missing Values
Apr 30, 2024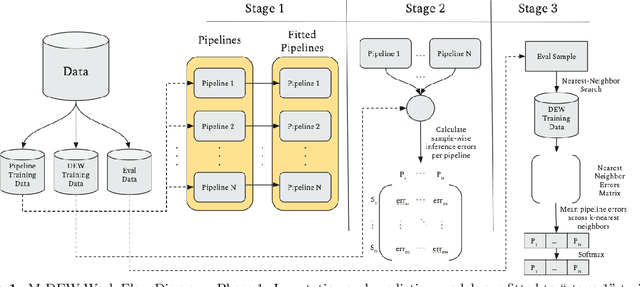


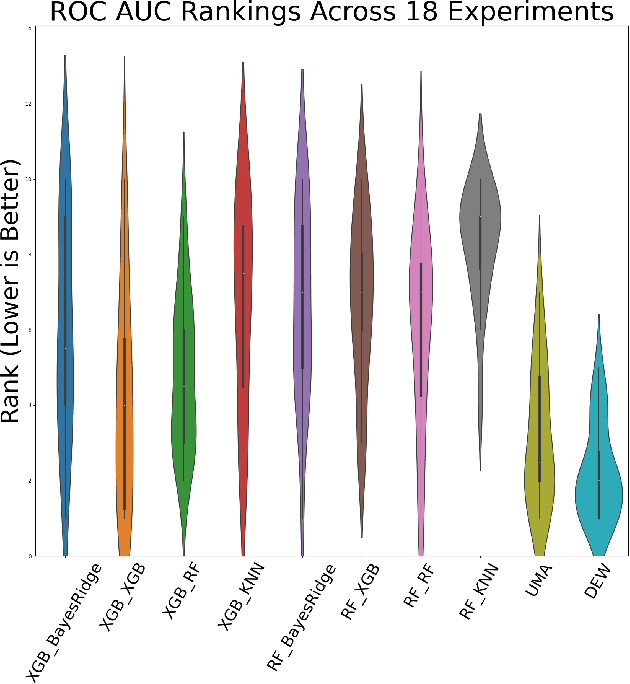
Missing value imputation is a crucial preprocessing step for many machine learning problems. However, it is often considered as a separate subtask from downstream applications such as classification, regression, or clustering, and thus is not optimized together with them. We hypothesize that treating the imputation model and downstream task model together and optimizing over full pipelines will yield better results than treating them separately. Our work describes a novel AutoML technique for making downstream predictions with missing data that automatically handles preprocessing, model weighting, and selection during inference time, with minimal compute overhead. Specifically we develop M-DEW, a Dynamic missingness-aware Ensemble Weighting (DEW) approach, that constructs a set of two-stage imputation-prediction pipelines, trains each component separately, and dynamically calculates a set of pipeline weights for each sample during inference time. We thus extend previous work on dynamic ensemble weighting to handle missing data at the level of full imputation-prediction pipelines, improving performance and calibration on downstream machine learning tasks over standard model averaging techniques. M-DEW is shown to outperform the state-of-the-art in that it produces statistically significant reductions in model perplexity in 17 out of 18 experiments, while improving average precision in 13 out of 18 experiments.
Challenges in Migrating Imperative Deep Learning Programs to Graph Execution: An Empirical Study
Jan 24, 2022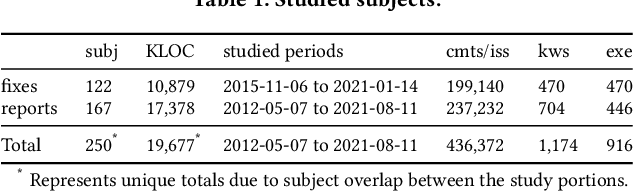
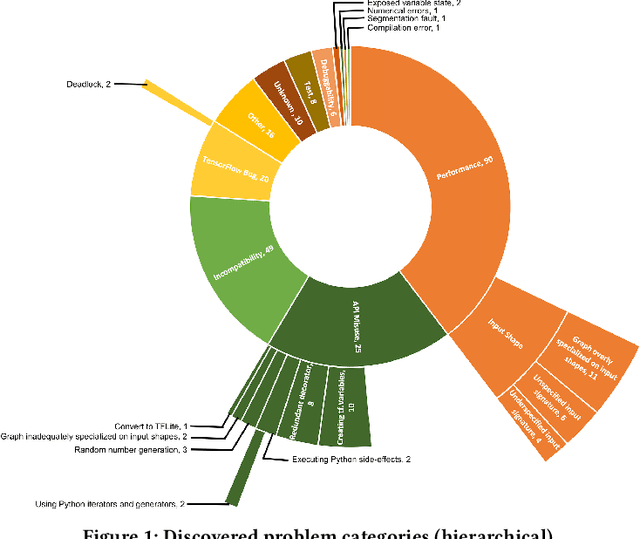
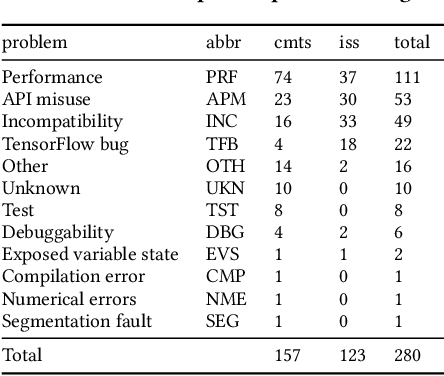

Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code that supports symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development tends to produce DL code that is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, less error-prone imperative DL frameworks encouraging eager execution have emerged but at the expense of run-time performance. While hybrid approaches aim for the "best of both worlds," the challenges in applying them in the real world are largely unknown. We conduct a data-driven analysis of challenges -- and resultant bugs -- involved in writing reliable yet performant imperative DL code by studying 250 open-source projects, consisting of 19.7 MLOC, along with 470 and 446 manually examined code patches and bug reports, respectively. The results indicate that hybridization: (i) is prone to API misuse, (ii) can result in performance degradation -- the opposite of its intention, and (iii) has limited application due to execution mode incompatibility. We put forth several recommendations, best practices, and anti-patterns for effectively hybridizing imperative DL code, potentially benefiting DL practitioners, API designers, tool developers, and educators.
Using Kernel Methods and Model Selection for Prediction of Preterm Birth
Sep 05, 2016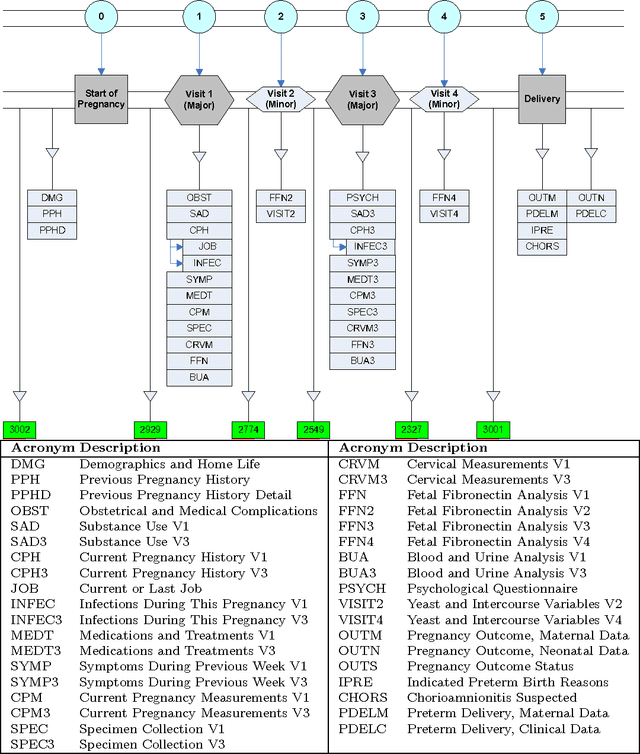
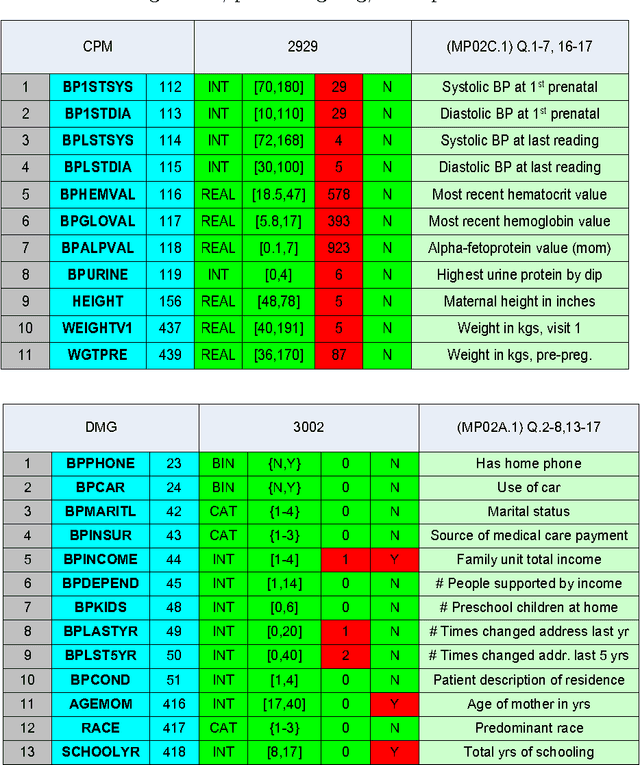

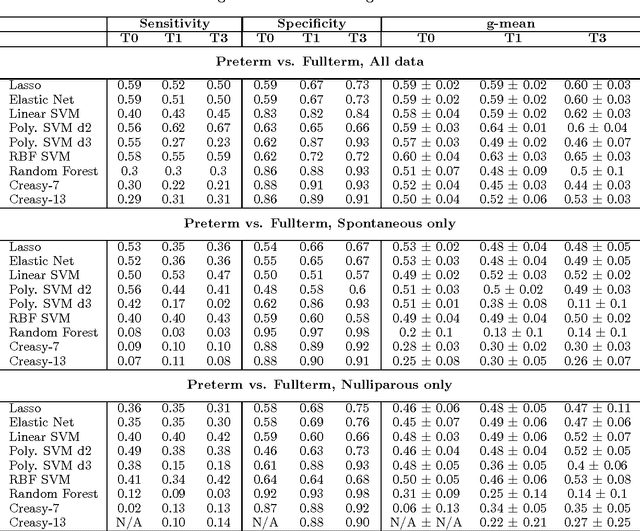
We describe an application of machine learning to the problem of predicting preterm birth. We conduct a secondary analysis on a clinical trial dataset collected by the National In- stitute of Child Health and Human Development (NICHD) while focusing our attention on predicting different classes of preterm birth. We compare three approaches for deriving predictive models: a support vector machine (SVM) approach with linear and non-linear kernels, logistic regression with different model selection along with a model based on decision rules prescribed by physician experts for prediction of preterm birth. Our approach highlights the pre-processing methods applied to handle the inherent dynamics, noise and gaps in the data and describe techniques used to handle skewed class distributions. Empirical experiments demonstrate significant improvement in predicting preterm birth compared to past work.