 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Automated Refactoring for Efficient Migration of Imperative Deep Learning Programs to Graph Execution
Apr 07, 2025Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code -- supporting symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, imperative DL frameworks encouraging eager execution have emerged at the expense of run-time performance. Though hybrid approaches aim for the "best of both worlds," using them effectively requires subtle considerations to make code amenable to safe, accurate, and efficient graph execution. We present an automated refactoring approach that assists developers in specifying whether their otherwise eagerly-executed imperative DL code could be reliably and efficiently executed as graphs while preserving semantics. The approach, based on a novel imperative tensor analysis, automatically determines when it is safe and potentially advantageous to migrate imperative DL code to graph execution. The approach is implemented as a PyDev Eclipse IDE plug-in that integrates the WALA Ariadne analysis framework and evaluated on 19 Python projects consisting of 132.05 KLOC. We found that 326 of 766 candidate functions (42.56%) were refactorable, and an average speedup of 2.16 on performance tests was observed. The results indicate that the approach is useful in optimizing imperative DL code to its full potential.
Challenges in Migrating Imperative Deep Learning Programs to Graph Execution: An Empirical Study
Jan 24, 2022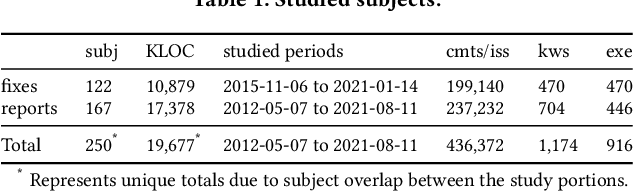
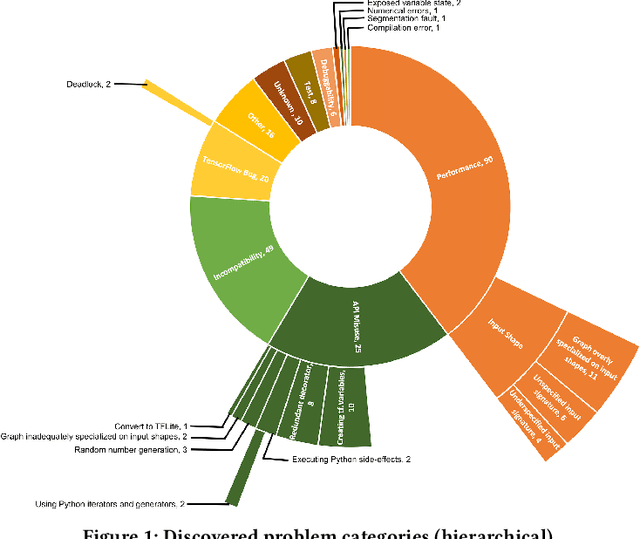
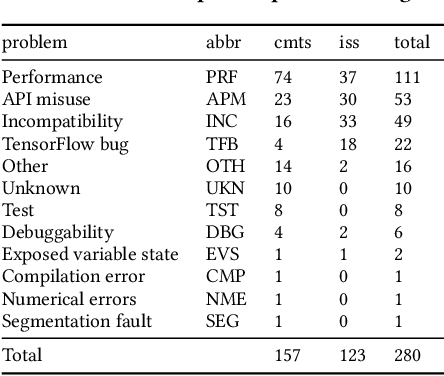

Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code that supports symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development tends to produce DL code that is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, less error-prone imperative DL frameworks encouraging eager execution have emerged but at the expense of run-time performance. While hybrid approaches aim for the "best of both worlds," the challenges in applying them in the real world are largely unknown. We conduct a data-driven analysis of challenges -- and resultant bugs -- involved in writing reliable yet performant imperative DL code by studying 250 open-source projects, consisting of 19.7 MLOC, along with 470 and 446 manually examined code patches and bug reports, respectively. The results indicate that hybridization: (i) is prone to API misuse, (ii) can result in performance degradation -- the opposite of its intention, and (iii) has limited application due to execution mode incompatibility. We put forth several recommendations, best practices, and anti-patterns for effectively hybridizing imperative DL code, potentially benefiting DL practitioners, API designers, tool developers, and educators.