 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Sequential Methodology for Convolutional Neural Networks
Nov 27, 2018
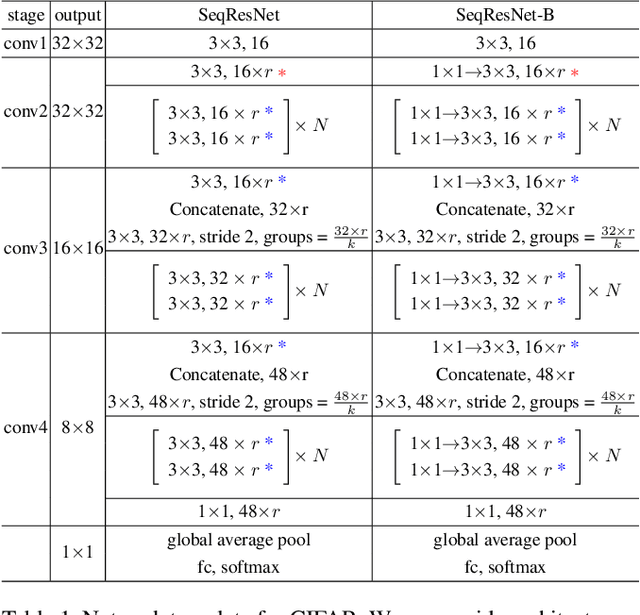


Recent work has shown that the performance of convolutional neural networks could be significantly improved by increasing the depth of the representation. We propose a fully sequential methodology to construct and train extremely deep convolutional neural networks. We first introduce a novel sequential convolutional layer to construct the network. The proposed layer is capable of constructing trainable and highly efficient feedforward networks that consist of thousands of vanilla convolutional layers with rather limited number of parameters. The layer extracts each feature of the produced representation in sequence, allowing feature reuse within the layer. This form of feature reuse introduces in-layer hierarchy to the extracted features which greatly increases the depth of the representation, enabling richer structures to be explored. Furthermore, we employ the progressive growing training method to optimize each module of the network in sequence. This training manner progressively increases the network capacity allowing later modules to be optimized conditioning on prior knowledge from earlier modules. Thus, it encourages long term dependency to be established among each module of the network, which increases the effective depth of networks with skip connections, as well alleviates multiple optimization difficulties for deep networks.