 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUlRe-NeRF: 3D Ultrasound Imaging through Neural Rendering with Ultrasound Reflection Direction Parameterization
Aug 05, 2024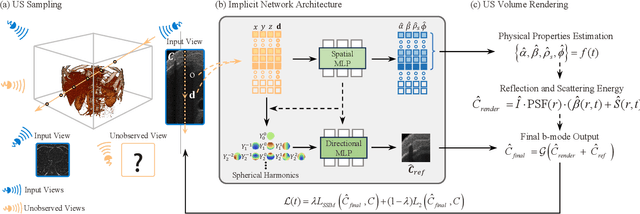
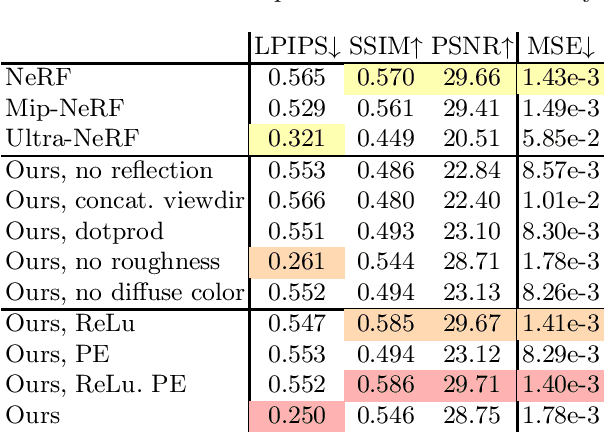
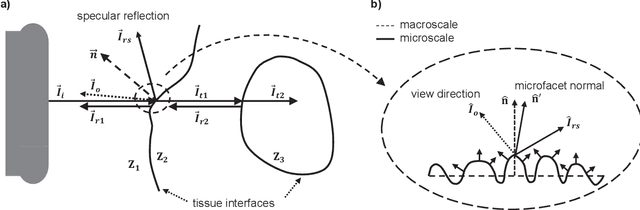
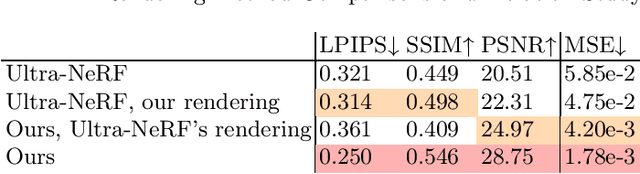
Three-dimensional ultrasound imaging is a critical technology widely used in medical diagnostics. However, traditional 3D ultrasound imaging methods have limitations such as fixed resolution, low storage efficiency, and insufficient contextual connectivity, leading to poor performance in handling complex artifacts and reflection characteristics. Recently, techniques based on NeRF (Neural Radiance Fields) have made significant progress in view synthesis and 3D reconstruction, but there remains a research gap in high-quality ultrasound imaging. To address these issues, we propose a new model, UlRe-NeRF, which combines implicit neural networks and explicit ultrasound volume rendering into an ultrasound neural rendering architecture. This model incorporates reflection direction parameterization and harmonic encoding, using a directional MLP module to generate view-dependent high-frequency reflection intensity estimates, and a spatial MLP module to produce the medium's physical property parameters. These parameters are used in the volume rendering process to accurately reproduce the propagation and reflection behavior of ultrasound waves in the medium. Experimental results demonstrate that the UlRe-NeRF model significantly enhances the realism and accuracy of high-fidelity ultrasound image reconstruction, especially in handling complex medium structures.
Robust Implementation of Foreground Extraction and Vessel Segmentation for X-ray Coronary Angiography Image Sequence
Sep 15, 2022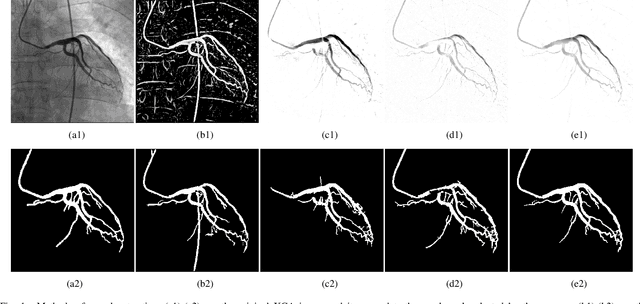
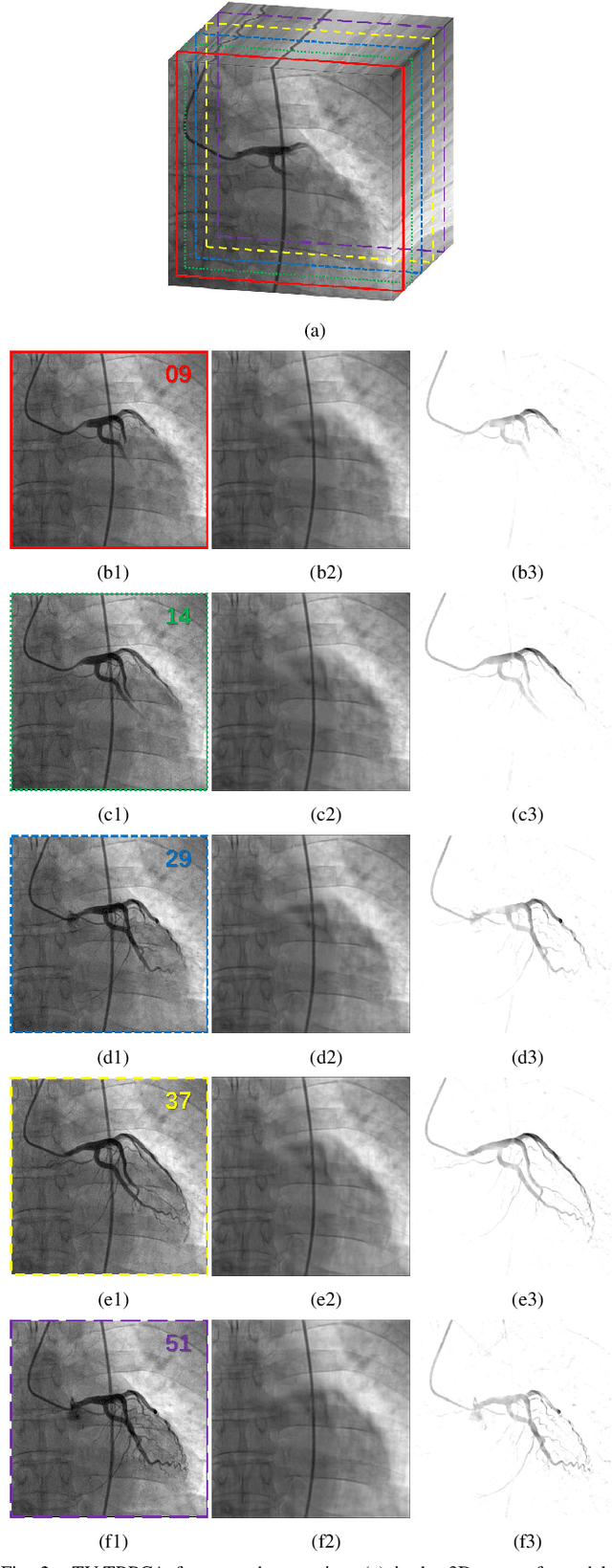
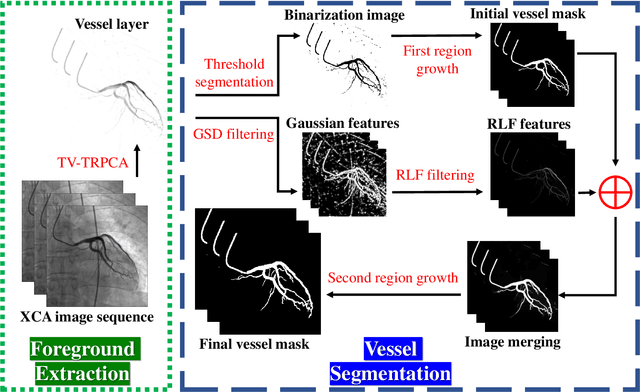

The extraction of contrast-filled vessels from X-ray coronary angiography(XCA) image sequence has important clinical significance for intuitively diagnosis and therapy. In this study, XCA image sequence O is regarded as a three-dimensional tensor input, vessel layer H is a sparse tensor, and background layer B is a low-rank tensor. Using tensor nuclear norm(TNN) minimization, a novel method for vessel layer extraction based on tensor robust principal component analysis(TRPCA) is proposed. Furthermore, considering the irregular movement of vessels and the dynamic interference of surrounding irrelevant tissues, the total variation(TV) regularized spatial-temporal constraint is introduced to separate the dynamic background E. Subsequently, for the vessel images with uneven contrast distribution, a two-stage region growth(TSRG) method is utilized for vessel enhancement and segmentation. A global threshold segmentation is used as the pre-processing to obtain the main branch, and the Radon-Like features(RLF) filter is used to enhance and connect broken minor segments, the final vessel mask is constructed by combining the two intermediate results. We evaluated the visibility of TV-TRPCA algorithm for foreground extraction and the accuracy of TSRG algorithm for vessel segmentation on real clinical XCA image sequences and third-party database. Both qualitative and quantitative results verify the superiority of the proposed methods over the existing state-of-the-art approaches.
Gamma-Reward: A Novel Multi-Agent Reinforcement Learning Method for Traffic Signal Control
Feb 27, 2020
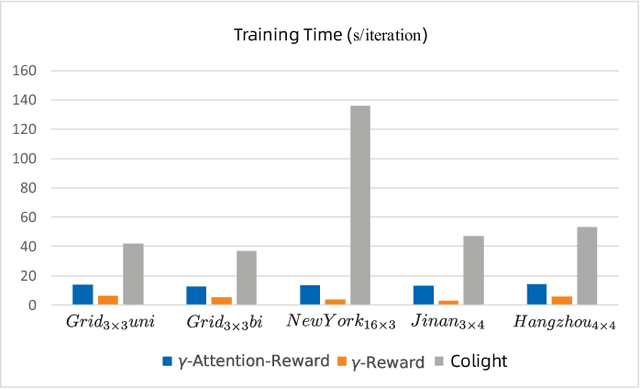
The intelligent control of traffic signal is critical to the optimization of transportation systems. To solve the problem in large-scale road networks, recent research has focused on interactions among intersections, which have shown promising results. However, existing studies pay more attention to the sensation sharing among agents and do not care about the results after taking each action. In this paper, we propose a novel multi-agent interaction mechanism, defined as Gamma-Reward that includes both original Gamma-Reward and Gamma-Attention-Reward, which use the space-time information in the replay buffer to amend the reward of each action, for traffic signal control based on deep reinforcement learning method. We give a detailed theoretical foundation and prove the proposed method can converge to Nash Equilibrium. By extending the idea of Markov Chain to the road network, this interaction mechanism replaces the graph attention method and realizes the decoupling of the road network, which is more in line with practical applications. Simulation and experiment results demonstrate that the proposed model can get better performance than previous studies, by amending the reward. To our best knowledge, our work appears to be the first to treat the road network itself as a Markov Chain.
Efficient reinforcement learning control for continuum robots based on Inexplicit Prior Knowledge
Feb 26, 2020
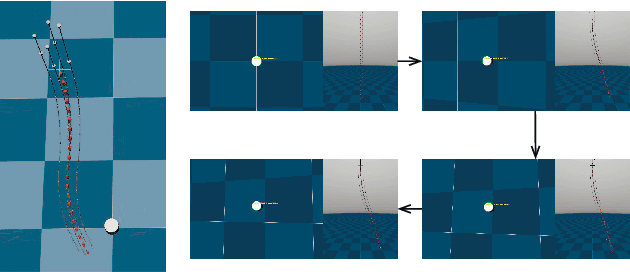
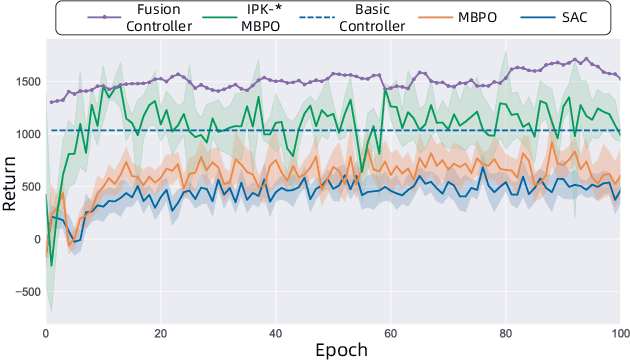
Compared to rigid robots that are often studied in reinforcement learning, the physical characteristics of some sophisticated robots such as software or continuum are more complicated. Moreover, recent reinforcement learning methods are data-inefficient and can not be directly deployed to the robot without simulation. In this paper, we propose an efficient reinforcement learning method based on inexplicit prior knowledge in response to such problems. The method is firstly corroborated by simulation and employed directly in the real world. By using our method, we can achieve visual active tracking and distance maintenance of a tendon-driven robot which will be critical in minimally-invasive procedures.
Multiview Based 3D Scene Understanding On Partial Point Sets
Nov 30, 2018
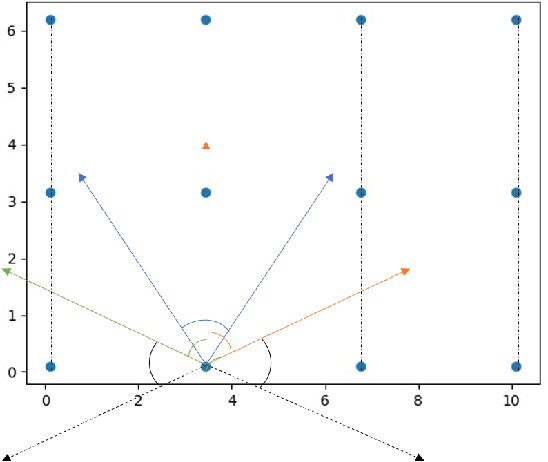

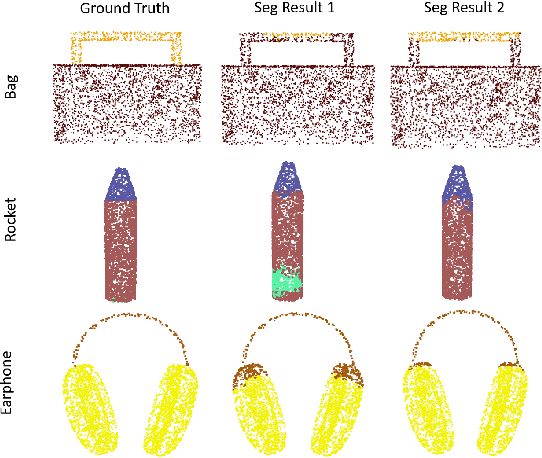
Deep learning within the context of point clouds has gained much research interest in recent years mostly due to the promising results that have been achieved on a number of challenging benchmarks, such as 3D shape recognition and scene semantic segmentation. In many realistic settings however, snapshots of the environment are often taken from a single view, which only contains a partial set of the scene due to the field of view restriction of commodity cameras. 3D scene semantic understanding on partial point clouds is considered as a challenging task. In this work, we propose a processing approach for 3D point cloud data based on a multiview representation of the existing 360{\deg} point clouds. By fusing the original 360{\deg} point clouds and their corresponding 3D multiview representations as input data, a neural network is able to recognize partial point sets while improving the general performance on complete point sets, resulting in an overall increase of 31.9% and 4.3% in segmentation accuracy for partial and complete scene semantic understanding, respectively. This method can also be applied in a wider 3D recognition context such as 3D part segmentation.