 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation-Aligned Audio Reproduction With LLM-Based Equalizers
Jan 14, 2026Conventional audio equalization is a static process that requires manual and cumbersome adjustments to adapt to changing listening contexts (e.g., mood, location, or social setting). In this paper, we introduce a Large Language Model (LLM)-based alternative that maps natural language text prompts to equalization settings. This enables a conversational approach to sound system control. By utilizing data collected from a controlled listening experiment, our models exploit in-context learning and parameter-efficient fine-tuning techniques to reliably align with population-preferred equalization settings. Our evaluation methods, which leverage distributional metrics that capture users' varied preferences, show statistically significant improvements in distributional alignment over random sampling and static preset baselines. These results indicate that LLMs could function as "artificial equalizers," contributing to the development of more accessible, context-aware, and expert-level audio tuning methods.
Sound field reconstruction in rooms: inpainting meets superresolution
Jan 30, 2020
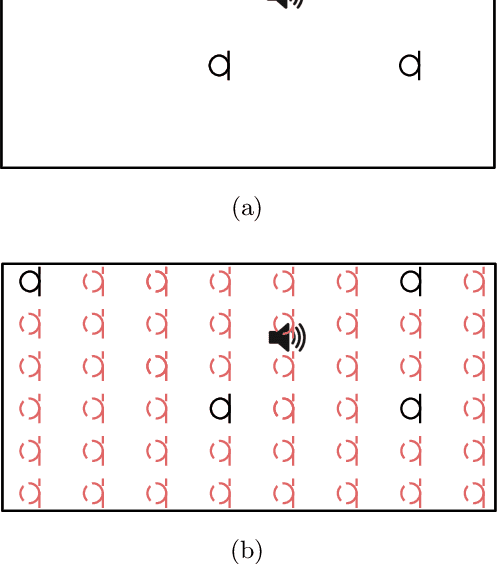
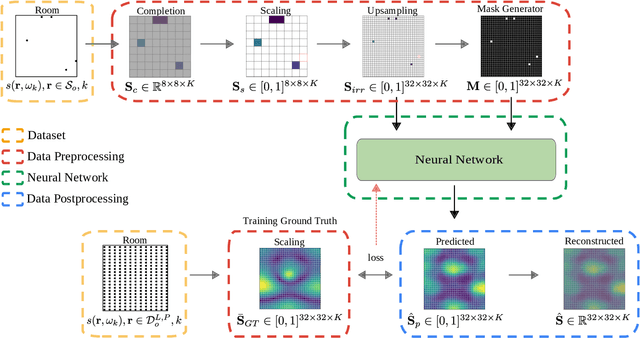
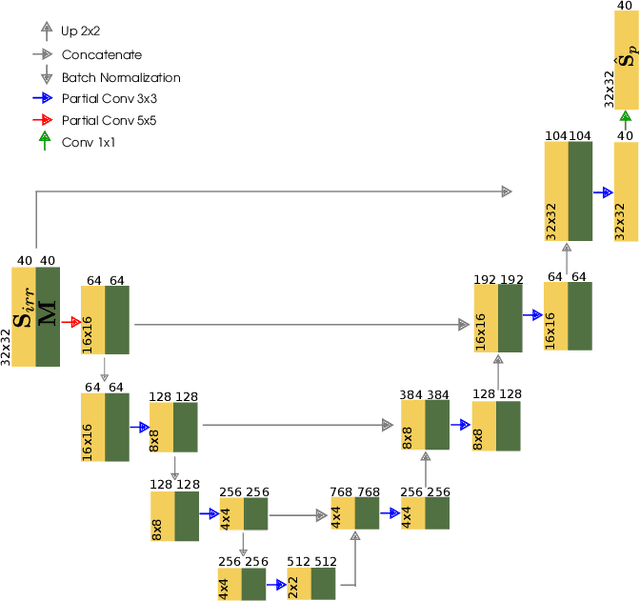
In this paper a deep-learning-based method for sound field reconstruction is proposed. It is shown the possibility to reconstruct the magnitude of the sound pressure in the frequency band 30-300 Hz for an entire room by using a very low number of irregularly distributed microphones arbitrarily arranged. In particular, the presented approach uses a limited number of arbitrary discrete measurements of the magnitude of the sound field pressure in order to extrapolate this field to a higher-resolution grid of discrete points in space with a low computational complexity. The method is based on a U-net-like neural network with partial convolutions trained solely on simulated data, i.e. the dataset is constructed from numerical simulations of the Green's function across thousands of common rectangular rooms. Although extensible to three dimensions, the method focuses on reconstructing a two-dimensional plane of the room from measurements of the three-dimensional sound field. Experiments using simulated data together with an experimental validation in a real listening room are shown. The results suggest a performance---in terms of mean squared error and structural similarity---which may exceed conventional reconstruction techniques for a low number of microphones and computational requirements.
Multiview Based 3D Scene Understanding On Partial Point Sets
Nov 30, 2018
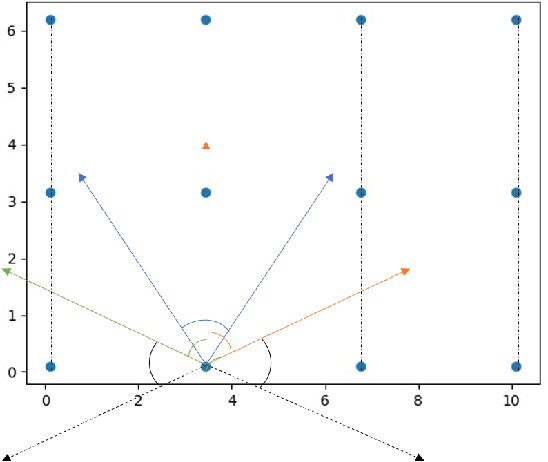

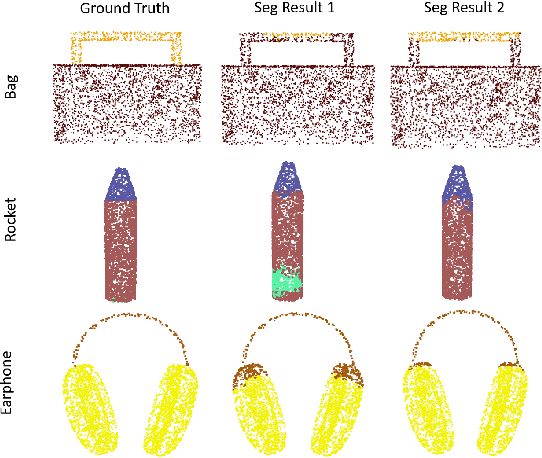
Deep learning within the context of point clouds has gained much research interest in recent years mostly due to the promising results that have been achieved on a number of challenging benchmarks, such as 3D shape recognition and scene semantic segmentation. In many realistic settings however, snapshots of the environment are often taken from a single view, which only contains a partial set of the scene due to the field of view restriction of commodity cameras. 3D scene semantic understanding on partial point clouds is considered as a challenging task. In this work, we propose a processing approach for 3D point cloud data based on a multiview representation of the existing 360{\deg} point clouds. By fusing the original 360{\deg} point clouds and their corresponding 3D multiview representations as input data, a neural network is able to recognize partial point sets while improving the general performance on complete point sets, resulting in an overall increase of 31.9% and 4.3% in segmentation accuracy for partial and complete scene semantic understanding, respectively. This method can also be applied in a wider 3D recognition context such as 3D part segmentation.