 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing automatic speech recognition using feature fusion with self-supervised learning features: A case study on Fearless Steps Apollo corpus
Apr 24, 2026Using self-supervised learning (SSL) models has significantly improved performance for downstream speech tasks, surpassing the capabilities of traditional hand-crafted features. This study investigates the amalgamation of SSL models, with the aim to leverage both their individual strengths and refine extracted features to achieve improved speech recognition models for naturalistic scenarios. Our research investigates the massive naturalistic Fearless Steps (FS) APOLLO resource, with particular focus on the FS Challenge (FSC) Phase-4 corpus, providing the inaugural analysis of this dataset. Additionally, we incorporate the CHiME-6 dataset to evaluate performance across diverse naturalistic speech scenarios. While exploring previously proposed Feature Refinement Loss and fusion methods, we found these methods to be less effective on the FSC Phase-4 corpus. To address this, we introduce a novel deep cross-attention (DCA) fusion method, designed to elevate performance, especially for the FSC Phase-4 corpus. Our objective is to foster creation of superior FS APOLLO community resources, catering to the diverse needs of researchers across various disciplines. The proposed solution achieves an absolute +1.1% improvement in WER, providing effective meta-data creation for the massive FS APOLLO community resource.
* Accepted to Speech Communication 2026
Emotion-Aware Prefix: Towards Explicit Emotion Control in Voice Conversion Models
Mar 10, 2026Recent advances in zero-shot voice conversion have exhibited potential in emotion control, yet the performance is suboptimal or inconsistent due to their limited expressive capacity. We propose Emotion-Aware Prefix for explicit emotion control in a two-stage voice conversion backbone. We significantly improve emotion conversion performance, doubling the baseline Emotion Conversion Accuracy (ECA) from 42.40% to 85.50% while maintaining linguistic integrity and speech quality, without compromising speaker identity. Our ablation study suggests that a joint control of both sequence modulation and acoustic realization is essential to synthesize distinct emotions. Furthermore, comparative analysis verifies the generalizability of proposed method, while it provides insights on the role of acoustic decoupling in maintaining speaker identity.
Bridging the Modality Gap: Softly Discretizing Audio Representation for LLM-based Automatic Speech Recognition
Jun 06, 2025One challenge of integrating speech input with large language models (LLMs) stems from the discrepancy between the continuous nature of audio data and the discrete token-based paradigm of LLMs. To mitigate this gap, we propose a method for integrating vector quantization (VQ) into LLM-based automatic speech recognition (ASR). Using the LLM embedding table as the VQ codebook, the VQ module aligns the continuous representations from the audio encoder with the discrete LLM inputs, enabling the LLM to operate on a discretized audio representation that better reflects the linguistic structure. We further create a soft "discretization" of the audio representation by updating the codebook and performing a weighted sum over the codebook embeddings. Empirical results demonstrate that our proposed method significantly improves upon the LLM-based ASR baseline, particularly in out-of-domain conditions. This work highlights the potential of soft discretization as a modality bridge in LLM-based ASR.
Acoustic modeling for Overlapping Speech Recognition: JHU Chime-5 Challenge System
May 17, 2024This paper summarizes our acoustic modeling efforts in the Johns Hopkins University speech recognition system for the CHiME-5 challenge to recognize highly-overlapped dinner party speech recorded by multiple microphone arrays. We explore data augmentation approaches, neural network architectures, front-end speech dereverberation, beamforming and robust i-vector extraction with comparisons of our in-house implementations and publicly available tools. We finally achieved a word error rate of 69.4% on the development set, which is a 11.7% absolute improvement over the previous baseline of 81.1%, and release this improved baseline with refined techniques/tools as an advanced CHiME-5 recipe.
* Published in: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Language Agnostic Data-Driven Inverse Text Normalization
Jan 24, 2023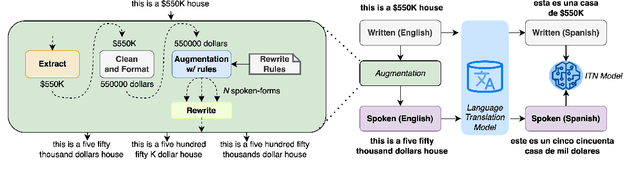
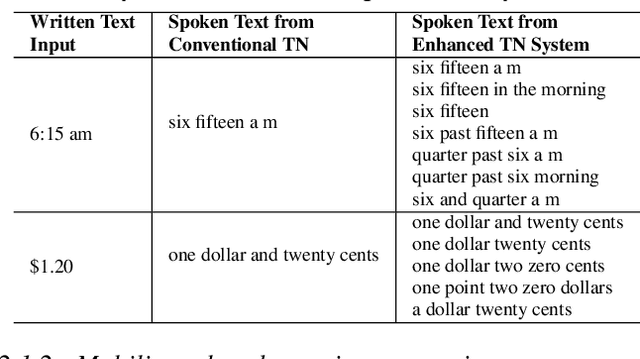
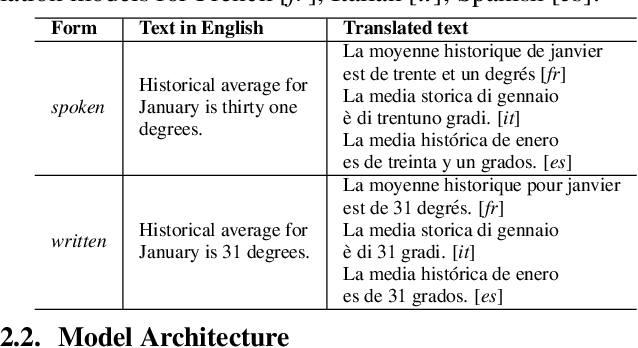
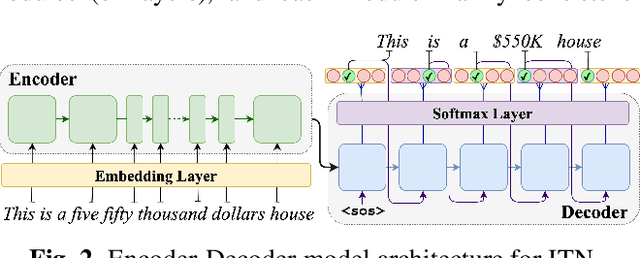
With the emergence of automatic speech recognition (ASR) models, converting the spoken form text (from ASR) to the written form is in urgent need. This inverse text normalization (ITN) problem attracts the attention of researchers from various fields. Recently, several works show that data-driven ITN methods can output high-quality written form text. Due to the scarcity of labeled spoken-written datasets, the studies on non-English data-driven ITN are quite limited. In this work, we propose a language-agnostic data-driven ITN framework to fill this gap. Specifically, we leverage the data augmentation in conjunction with neural machine translated data for low resource languages. Moreover, we design an evaluation method for language agnostic ITN model when only English data is available. Our empirical evaluation shows this language agnostic modeling approach is effective for low resource languages while preserving the performance for high resource languages.
FeaRLESS: Feature Refinement Loss for Ensembling Self-Supervised Learning Features in Robust End-to-end Speech Recognition
Jun 30, 2022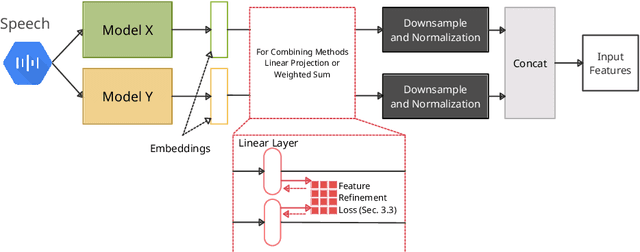
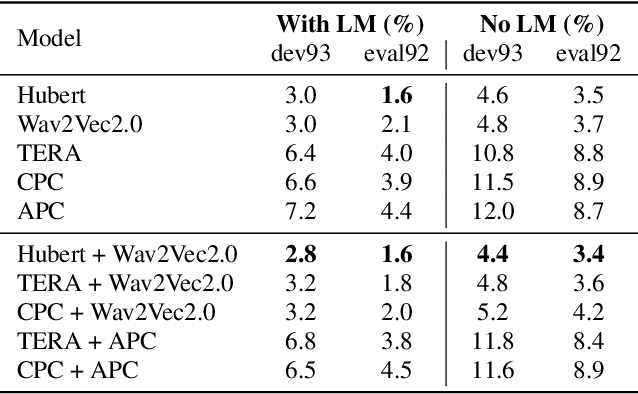
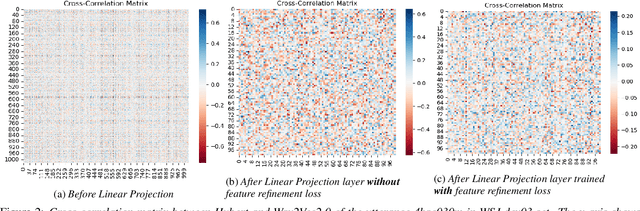
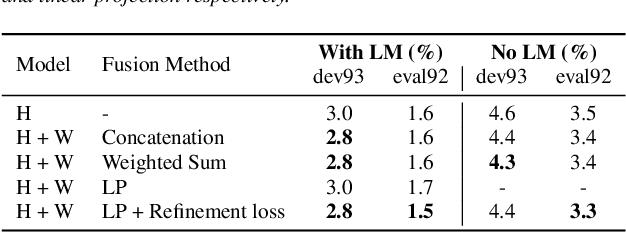
Self-supervised learning representations (SSLR) have resulted in robust features for downstream tasks in many fields. Recently, several SSLRs have shown promising results on automatic speech recognition (ASR) benchmark corpora. However, previous studies have only shown performance for solitary SSLRs as an input feature for ASR models. In this study, we propose to investigate the effectiveness of diverse SSLR combinations using various fusion methods within end-to-end (E2E) ASR models. In addition, we will show there are correlations between these extracted SSLRs. As such, we further propose a feature refinement loss for decorrelation to efficiently combine the set of input features. For evaluation, we show that the proposed 'FeaRLESS learning features' perform better than systems without the proposed feature refinement loss for both the WSJ and Fearless Steps Challenge (FSC) corpora.
Scenario Aware Speech Recognition: Advancements for Apollo Fearless Steps & CHiME-4 Corpora
Sep 23, 2021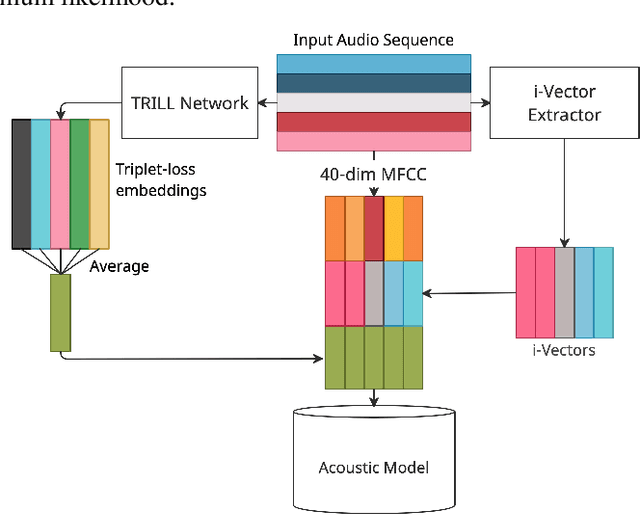
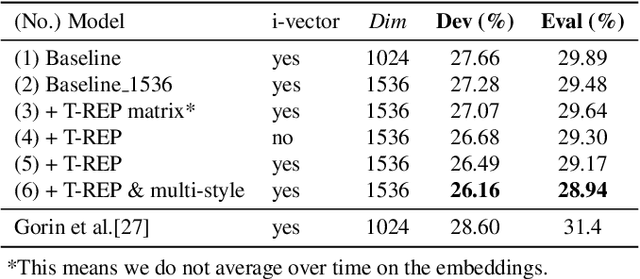
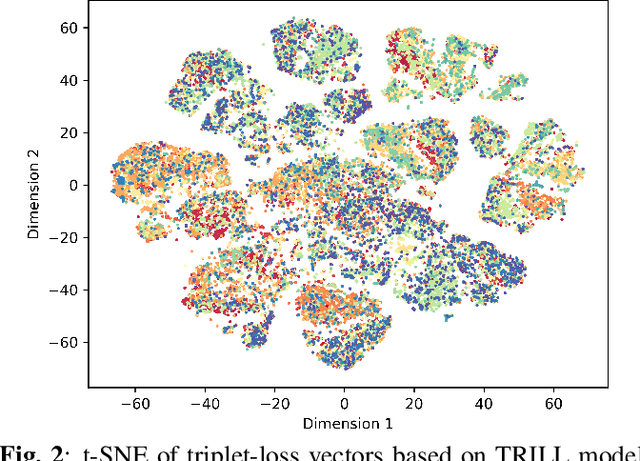

In this study, we propose to investigate triplet loss for the purpose of an alternative feature representation for ASR. We consider a general non-semantic speech representation, which is trained with a self-supervised criteria based on triplet loss called TRILL, for acoustic modeling to represent the acoustic characteristics of each audio. This strategy is then applied to the CHiME-4 corpus and CRSS-UTDallas Fearless Steps Corpus, with emphasis on the 100-hour challenge corpus which consists of 5 selected NASA Apollo-11 channels. An analysis of the extracted embeddings provides the foundation needed to characterize training utterances into distinct groups based on acoustic distinguishing properties. Moreover, we also demonstrate that triplet-loss based embedding performs better than i-Vector in acoustic modeling, confirming that the triplet loss is more effective than a speaker feature. With additional techniques such as pronunciation and silence probability modeling, plus multi-style training, we achieve a +5.42% and +3.18% relative WER improvement for the development and evaluation sets of the Fearless Steps Corpus. To explore generalization, we further test the same technique on the 1 channel track of CHiME-4 and observe a +11.90% relative WER improvement for real test data.
Building state-of-the-art distant speech recognition using the CHiME-4 challenge with a setup of speech enhancement baseline
Mar 27, 2018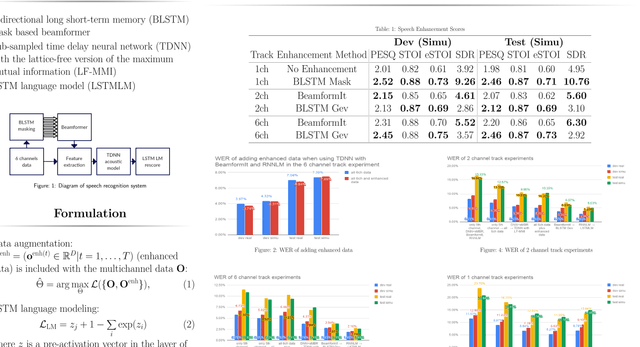
This paper describes a new baseline system for automatic speech recognition (ASR) in the CHiME-4 challenge to promote the development of noisy ASR in speech processing communities by providing 1) state-of-the-art system with a simplified single system comparable to the complicated top systems in the challenge, 2) publicly available and reproducible recipe through the main repository in the Kaldi speech recognition toolkit. The proposed system adopts generalized eigenvalue beamforming with bidirectional long short-term memory (LSTM) mask estimation. We also propose to use a time delay neural network (TDNN) based on the lattice-free version of the maximum mutual information (LF-MMI) trained with augmented all six microphones plus the enhanced data after beamforming. Finally, we use a LSTM language model for lattice and n-best re-scoring. The final system achieved 2.74\% WER for the real test set in the 6-channel track, which corresponds to the 2nd place in the challenge. In addition, the proposed baseline recipe includes four different speech enhancement measures, short-time objective intelligibility measure (STOI), extended STOI (eSTOI), perceptual evaluation of speech quality (PESQ) and speech distortion ratio (SDR) for the simulation test set. Thus, the recipe also provides an experimental platform for speech enhancement studies with these performance measures.