 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Prefix: Towards Explicit Emotion Control in Voice Conversion Models
Mar 10, 2026Recent advances in zero-shot voice conversion have exhibited potential in emotion control, yet the performance is suboptimal or inconsistent due to their limited expressive capacity. We propose Emotion-Aware Prefix for explicit emotion control in a two-stage voice conversion backbone. We significantly improve emotion conversion performance, doubling the baseline Emotion Conversion Accuracy (ECA) from 42.40% to 85.50% while maintaining linguistic integrity and speech quality, without compromising speaker identity. Our ablation study suggests that a joint control of both sequence modulation and acoustic realization is essential to synthesize distinct emotions. Furthermore, comparative analysis verifies the generalizability of proposed method, while it provides insights on the role of acoustic decoupling in maintaining speaker identity.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025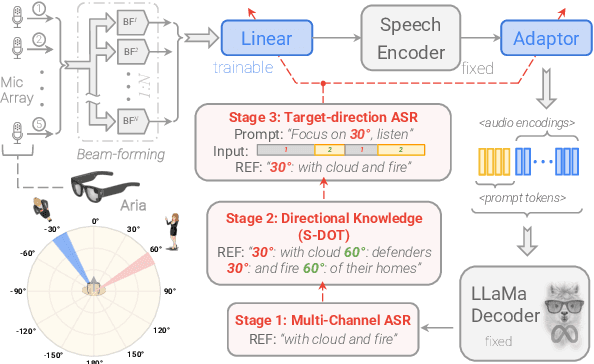
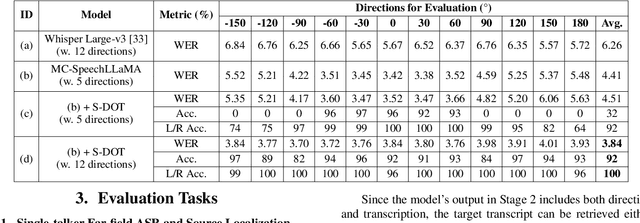
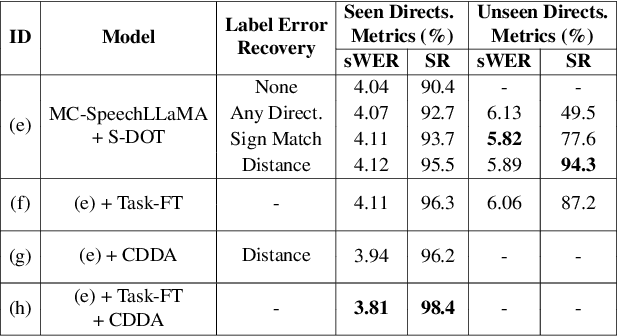
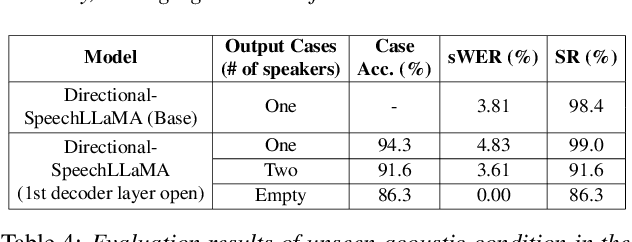
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
Bridging the Modality Gap: Softly Discretizing Audio Representation for LLM-based Automatic Speech Recognition
Jun 06, 2025One challenge of integrating speech input with large language models (LLMs) stems from the discrepancy between the continuous nature of audio data and the discrete token-based paradigm of LLMs. To mitigate this gap, we propose a method for integrating vector quantization (VQ) into LLM-based automatic speech recognition (ASR). Using the LLM embedding table as the VQ codebook, the VQ module aligns the continuous representations from the audio encoder with the discrete LLM inputs, enabling the LLM to operate on a discretized audio representation that better reflects the linguistic structure. We further create a soft "discretization" of the audio representation by updating the codebook and performing a weighted sum over the codebook embeddings. Empirical results demonstrate that our proposed method significantly improves upon the LLM-based ASR baseline, particularly in out-of-domain conditions. This work highlights the potential of soft discretization as a modality bridge in LLM-based ASR.
MixRep: Hidden Representation Mixup for Low-Resource Speech Recognition
Oct 27, 2023



In this paper, we present MixRep, a simple and effective data augmentation strategy based on mixup for low-resource ASR. MixRep interpolates the feature dimensions of hidden representations in the neural network that can be applied to both the acoustic feature input and the output of each layer, which generalizes the previous MixSpeech method. Further, we propose to combine the mixup with a regularization along the time axis of the input, which is shown as complementary. We apply MixRep to a Conformer encoder of an E2E LAS architecture trained with a joint CTC loss. We experiment on the WSJ dataset and subsets of the SWB dataset, covering reading and telephony conversational speech. Experimental results show that MixRep consistently outperforms other regularization methods for low-resource ASR. Compared to a strong SpecAugment baseline, MixRep achieves a +6.5\% and a +6.7\% relative WER reduction on the eval92 set and the Callhome part of the eval'2000 set.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023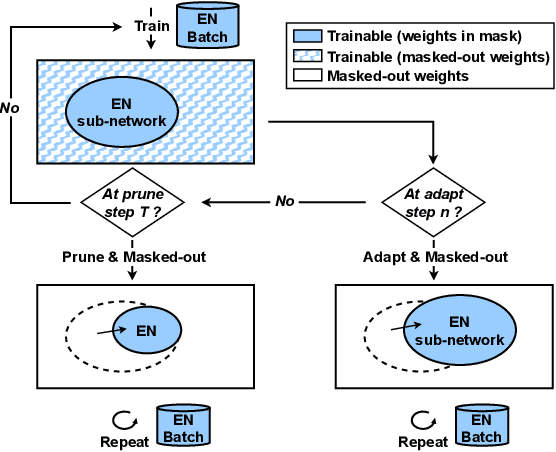



Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
DEFORMER: Coupling Deformed Localized Patterns with Global Context for Robust End-to-end Speech Recognition
Jul 06, 2022



Convolutional neural networks (CNN) have improved speech recognition performance greatly by exploiting localized time-frequency patterns. But these patterns are assumed to appear in symmetric and rigid kernels by the conventional CNN operation. It motivates the question: What about asymmetric kernels? In this study, we illustrate adaptive views can discover local features which couple better with attention than fixed views of the input. We replace depthwise CNNs in the Conformer architecture with a deformable counterpart, dubbed this "Deformer". By analyzing our best-performing model, we visualize both local receptive fields and global attention maps learned by the Deformer and show increased feature associations on the utterance level. The statistical analysis of learned kernel offsets provides an insight into the change of information in features with the network depth. Finally, replacing only half of the layers in the encoder, the Deformer improves +5.6% relative WER without a LM and +6.4% relative WER with a LM over the Conformer baseline on the WSJ eval92 set.
FeaRLESS: Feature Refinement Loss for Ensembling Self-Supervised Learning Features in Robust End-to-end Speech Recognition
Jun 30, 2022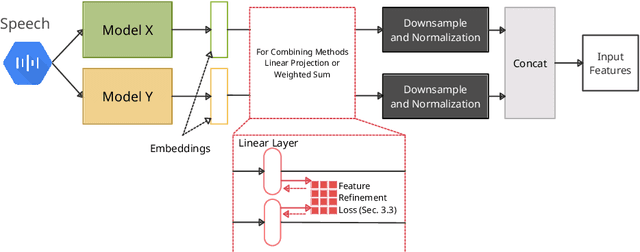
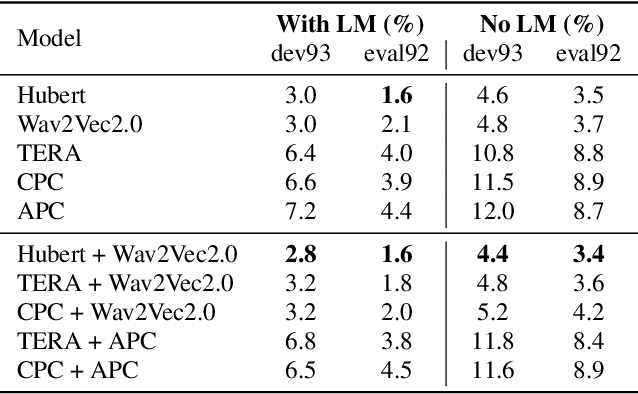
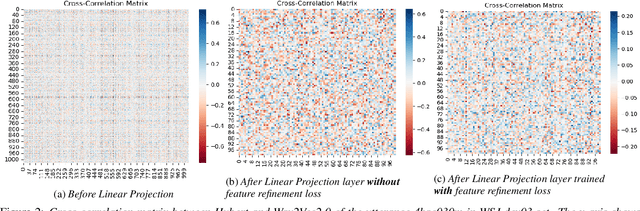
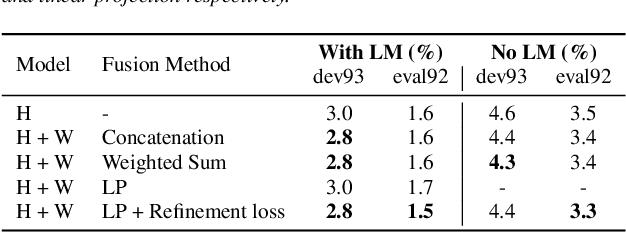
Self-supervised learning representations (SSLR) have resulted in robust features for downstream tasks in many fields. Recently, several SSLRs have shown promising results on automatic speech recognition (ASR) benchmark corpora. However, previous studies have only shown performance for solitary SSLRs as an input feature for ASR models. In this study, we propose to investigate the effectiveness of diverse SSLR combinations using various fusion methods within end-to-end (E2E) ASR models. In addition, we will show there are correlations between these extracted SSLRs. As such, we further propose a feature refinement loss for decorrelation to efficiently combine the set of input features. For evaluation, we show that the proposed 'FeaRLESS learning features' perform better than systems without the proposed feature refinement loss for both the WSJ and Fearless Steps Challenge (FSC) corpora.