 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio MultiChallenge: A Multi-Turn Evaluation of Spoken Dialogue Systems on Natural Human Interaction
Dec 16, 2025



End-to-end (E2E) spoken dialogue systems are increasingly replacing cascaded pipelines for voice-based human-AI interaction, processing raw audio directly without intermediate transcription. Existing benchmarks primarily evaluate these models on synthetic speech and single-turn tasks, leaving realistic multi-turn conversational ability underexplored. We introduce Audio MultiChallenge, an open-source benchmark to evaluate E2E spoken dialogue systems under natural multi-turn interaction patterns. Building on the text-based MultiChallenge framework, which evaluates Inference Memory, Instruction Retention, and Self Coherence, we introduce a new axis Voice Editing that tests robustness to mid-utterance speech repairs and backtracking. We further augment each axis to the audio modality, such as introducing Audio-Cue challenges for Inference Memory that require recalling ambient sounds and paralinguistic signals beyond semantic content. We curate 452 conversations from 47 speakers with 1,712 instance-specific rubrics through a hybrid audio-native agentic and human-in-the-loop pipeline that exposes model failures at scale while preserving natural disfluencies found in unscripted human speech. Our evaluation of proprietary and open-source models reveals that even frontier models struggle on our benchmark, with Gemini 3 Pro Preview (Thinking), our highest-performing model achieving a 54.65% pass rate. Error analysis shows that models fail most often on our new axes and that Self Coherence degrades with longer audio context. These failures reflect difficulty of tracking edits, audio cues, and long-range context in natural spoken dialogue. Audio MultiChallenge provides a reproducible testbed to quantify them and drive improvements in audio-native multi-turn interaction capability.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025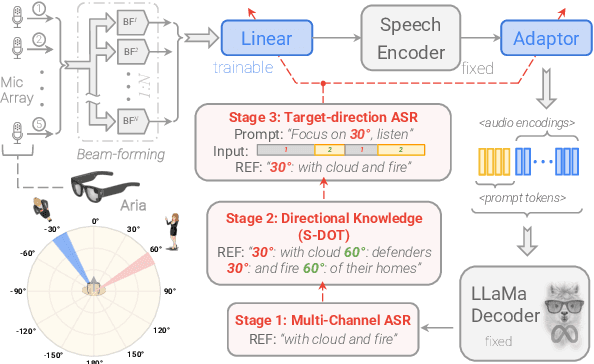
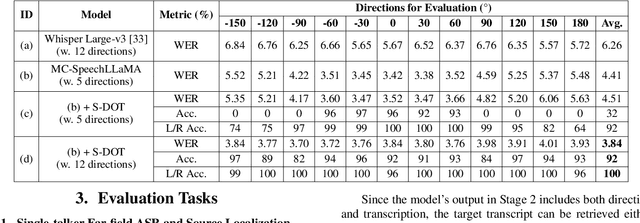
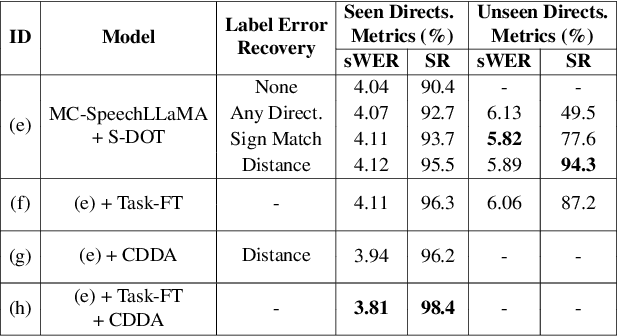
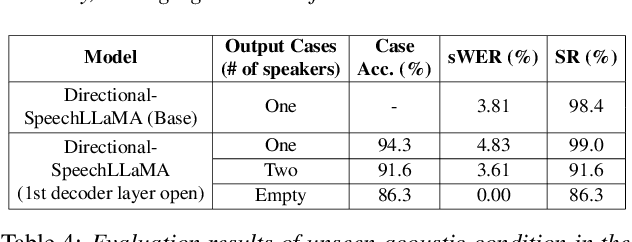
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
Self-supervision and Learnable STRFs for Age, Emotion, and Country Prediction
Jun 25, 2022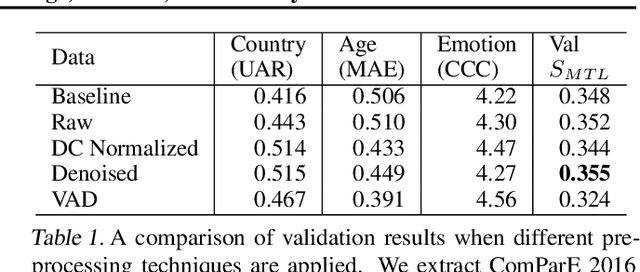
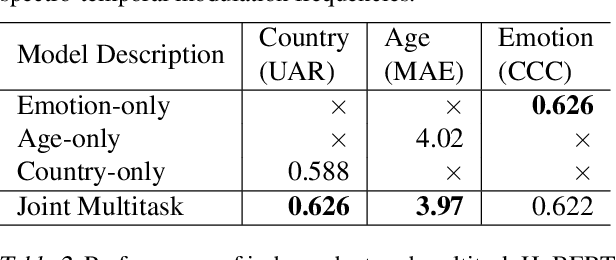
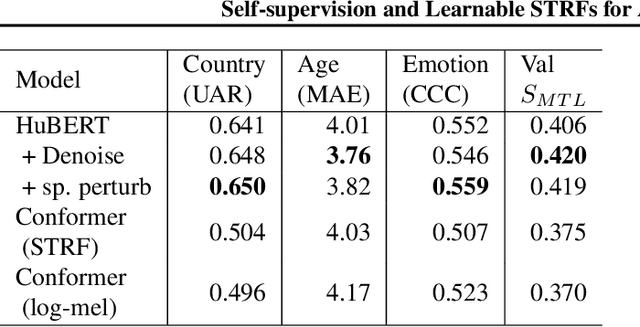
This work presents a multitask approach to the simultaneous estimation of age, country of origin, and emotion given vocal burst audio for the 2022 ICML Expressive Vocalizations Challenge ExVo-MultiTask track. The method of choice utilized a combination of spectro-temporal modulation and self-supervised features, followed by an encoder-decoder network organized in a multitask paradigm. We evaluate the complementarity between the tasks posed by examining independent task-specific and joint models, and explore the relative strengths of different feature sets. We also introduce a simple score fusion mechanism to leverage the complementarity of different feature sets for this task. We find that robust data preprocessing in conjunction with score fusion over spectro-temporal receptive field and HuBERT models achieved our best ExVo-MultiTask test score of 0.412.
Generalized Spoofing Detection Inspired from Audio Generation Artifacts
Apr 08, 2021

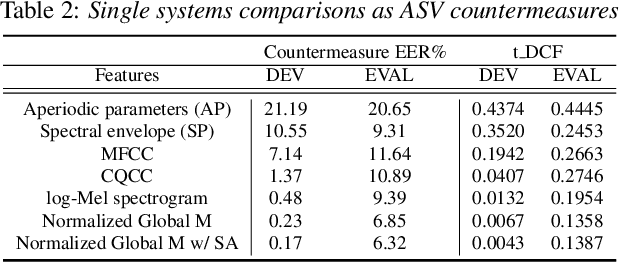

State-of-the-art methods for audio generation suffer from fingerprint artifacts and repeated inconsistencies across temporal and spectral domains. Such artifacts could be well captured by the frequency domain analysis over the spectrogram. Thus, we propose a novel use of long-range spectro-temporal modulation feature -- 2D DCT over log-Mel spectrogram for the audio deepfake detection. We show that this feature works better than log-Mel spectrogram, CQCC, MFCC, etc., as a suitable candidate to capture such artifacts. We employ spectrum augmentation and feature normalization to decrease overfitting and bridge the gap between training and test dataset along with this novel feature introduction. We developed a CNN-based baseline that achieved a 0.0849 t-DCF and outperformed the best single system reported in the ASVspoof 2019 challenge. Finally, by combining our baseline with our proposed 2D DCT spectro-temporal feature, we decrease the t-DCF score down by 14% to 0.0737, making it one of the best systems for spoofing detection. Furthermore, we evaluate our model using two external datasets, showing the proposed feature's generalization ability. We also provide analysis and ablation studies for our proposed feature and results.
A Modulation-Domain Loss for Neural-Network-based Real-time Speech Enhancement
Feb 15, 2021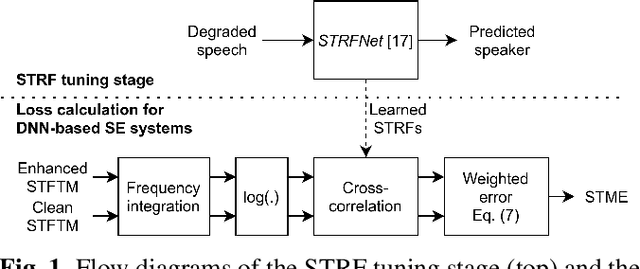
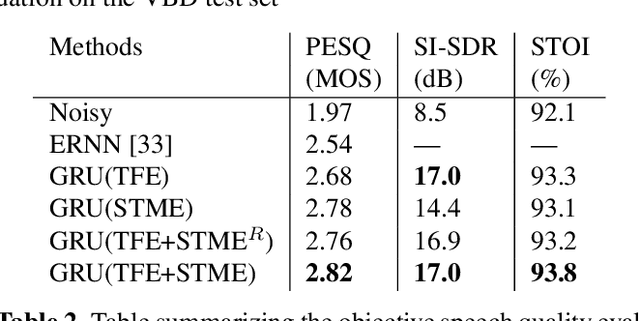
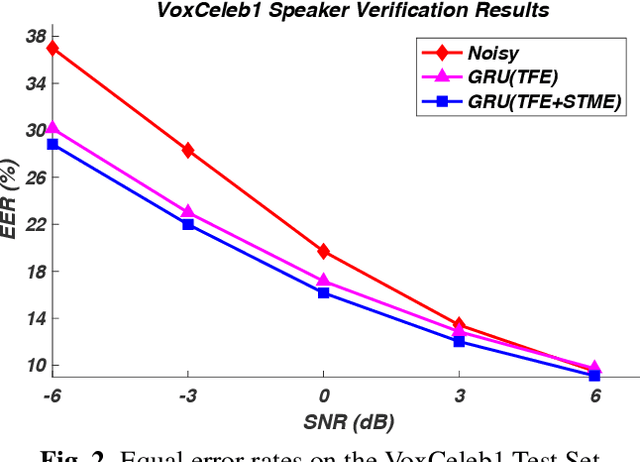
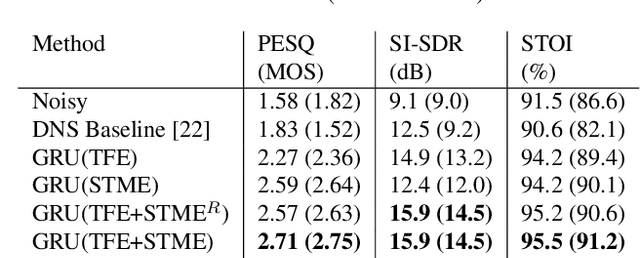
We describe a modulation-domain loss function for deep-learning-based speech enhancement systems. Learnable spectro-temporal receptive fields (STRFs) were adapted to optimize for a speaker identification task. The learned STRFs were then used to calculate a weighted mean-squared error (MSE) in the modulation domain for training a speech enhancement system. Experiments showed that adding the modulation-domain MSE to the MSE in the spectro-temporal domain substantially improved the objective prediction of speech quality and intelligibility for real-time speech enhancement systems without incurring additional computation during inference.
Natural Language Person Search Using Deep Reinforcement Learning
Sep 02, 2018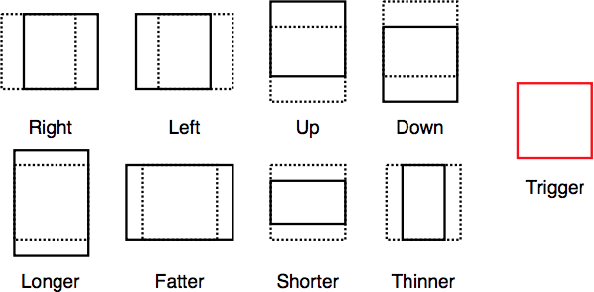
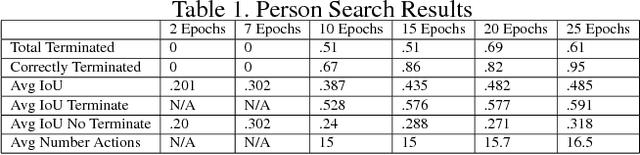
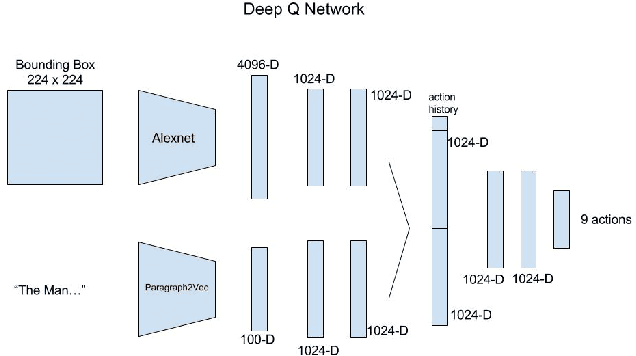

Recent success in deep reinforcement learning is having an agent learn how to play Go and beat the world champion without any prior knowledge of the game. In that task, the agent has to make a decision on what action to take based on the positions of the pieces. Person Search is recently explored using natural language based text description of images for video surveillance applications (S.Li et.al). We see (Fu.et al) provides an end to end approach for object-based retrieval using deep reinforcement learning without constraints placed on which objects are being detected. However, we believe for real-world applications such as person search defining specific constraints which identify a person as opposed to starting with a general object detection will have benefits in terms of performance and computational resources required. In our task, Deep reinforcement learning would localize the person in an image by reshaping the sizes of the bounding boxes. Deep Reinforcement learning with appropriate constraints would look only for the relevant person in the image as opposed to an unconstrained approach where each individual objects in the image are ranked. For person search, the agent is trying to form a tight bounding box around the person in the image who matches the description. The bounding box is initialized to the full image and at each time step, the agent makes a decision on how to change the current bounding box so that it has a tighter bound around the person based on the description of the person and the pixel values of the current bounding box. After the agent takes an action, it will be given a reward based on the Intersection over Union (IoU) of the current bounding box and the ground truth box. Once the agent believes that the bounding box is covering the person, it will indicate that the person is found.